将大模型与小模型结合的8种常用策略分享,附17篇案例论文和代码
现在我们对大模型的研究逐渐转向了“降耗增效”,通过结合高性能低耗资的小模型,实现更高效的计算和内存利用,达到满足特定场景的需求、降低成本和提高效率、提升系统性能以及增强适应性和扩展性的目的。
那么如何将大模型与小模型结合?
目前较常用的策略有模型压缩(蒸馏、剪枝)、提示语压缩、联合推理、迁移学习、权值共享、集成学习等。咱们今天就来简单聊聊这8种策略。
部分策略的具体步骤以及每种策略相关的参考论文我也放上了,方便同学们理解学习。
论文原文以及开源代码需要的同学看文末
一、模型压缩
模型压缩是一种策略,旨在将复杂的大模型转化为计算效率更高、资源消耗更少的小模型。这种策略主要通过知识蒸馏、轻量化模型架构、剪枝和量化等方法实现。
「参考论文:」
An Evaluation of Model Compression & Optimization Combinations
模型压缩和优化组合的评估
「简述:」本文旨在探索模型压缩领域的各种可能性,讨论不同级别的剪枝和量化的组合效率,并提出一种质量测量指标,以客观地决定哪种组合在最小化准确性差异和最大化大小减小因子方面最佳。
知识蒸馏
知识蒸馏是其中一种常用的压缩技术,它通过让小模型去拟合大模型,使小模型学习到与大模型相似的函数映射,从而达到模拟大模型性能的目的。
具体步骤:
-
首先需要一个性能优秀的大模型作为教师模型,让其学习数据并产生预测结果;
-
然后将这个大模型的输出概率向量作为软目标,称之为“soft targets”;
-
接着训练一个小模型,我们称其为学生模型,让学生模型去尽量拟合这些软目标;
-
最后在一些验证集或者测试集上评估学生模型的性能。
「参考论文:」
Distilling the Knowledge in aNeural Network
提取神经网络中的知识
「简述:」一种简单的方法是训练多个不同的模型,然后平均它们的预测结果来提高机器学习算法的性能。然而,使用整个模型集合进行预测可能会变得繁琐和计算密集。Caruana和他的合作者提出了将知识压缩到一个单一模型中的方法,这种方法更容易部署。他们通过将模型集合的知识蒸馏到一个单一模型中,显著提高了商用系统的声学模型性能。他们还引入了一种由完整模型和专家模型组成的新型集成方法,这些专家模型可以快速并行地训练,用于区分完整模型混淆的细粒度类别。
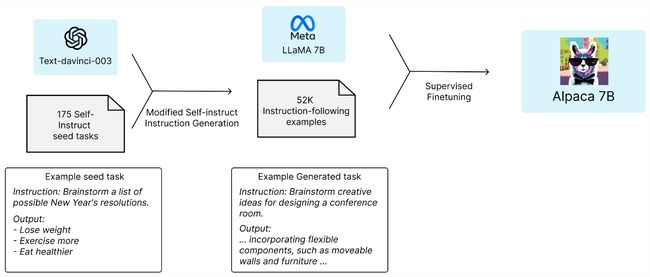
Alpaca: A Strong, Replicable Instruction-Following Model
一种强大的、可重复的指令遵循模型
「简述:」论文介绍了Alpaca 7B,这是一个从52K指令跟随演示中微调的LLaMA 7B模型。根据作者对单轮指令跟随的初步评估,Alpaca在质量上与OpenAI的text-davinci-003相似,同时令人惊讶的是它很小且易于/便宜复制(<600)。
Knowledge Distillation of Large Language Models
大型语言模型的知识蒸馏
「简述:」MINILLM是一个新的知识蒸馏方法,用于从大型生成型语言模型中提取小型语言模型。这种方法通过使用反向Kullback-Leibler散度来防止学生模型高估教师分布的低概率区域,从而提高了生成响应的精度和整体质量。实验表明,MINILLM在指令跟随设置中表现优异,具有较低的曝光偏差、更好的校准和更高的长文本生成性能。

剪枝大模型
训练一个大模型,然后通过剪枝的方法压缩模型,去掉冗余的结构和参数,得到一个更小但精度依然高的模型。
「参考论文:」
Pruning Filters for Efficient ConvNets
剪枝过滤器以获得高效的卷积神经网络
「简述:」本文介绍了一种加速卷积神经网络(CNN)的方法,即通过剪枝对网络影响较小的过滤器来减少计算成本。与权重剪枝不同,这种方法可以在整个网络中删除整个过滤器及其连接的特征图,从而显著降低计算成本。由于不需要稀疏卷积库的支持,因此该方法可以与现有的高效BLAS库一起使用。实验表明,即使在简单的过滤器剪枝技术下,VGG-16和ResNet-110在CIFAR10上的推理成本也可以分别降低34%和38%,并且通过重新训练网络可以获得接近原始精度的结果。
模型蒸馏
用大模型蒸馏出小模型实现降本。
「参考论文:」
Large Language Models Are Reasoning Teachers
大型语言模型是推理教师
「简述:」近期研究表明,大型语言模型可以逐步引导小型模型解决复杂推理任务。然而,这些方法需要使用非常大的模型,如GPT-3 175B,成本很高。在这篇论文中,作者提出了一种名为Fine-tune-CoT的方法,利用大型模型作为推理教师来微调小型模型。在各种公共模型和复杂任务上的评估表明,它能够在小型模型中实现显著的推理能力,甚至超过了大型教师模型。此外,作者还扩展了该方法,利用教师模型生成多个不同的推理结果来丰富微调数据,进一步提高性能。
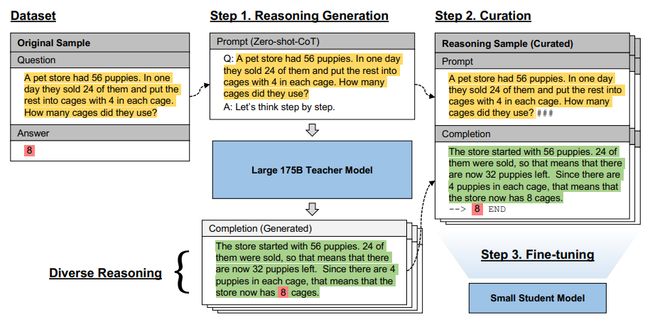
二、联合推理
联合推理:通过将大型语言模型(如GPT-3 175B)作为推理教师与小型模型相结合,实现复杂推理任务的解决。在这种方法中,大型模型被用来生成推理样本,这些样本包含了问题和对应的正确解答。然后,这些推理样本被用于微调小型模型,使其能够逐步学习和理解推理过程。
具体步骤:
-
首先使用大型模型对一组推理样本进行预测,得到每个样本的解答;
-
然后将这些解答与真实答案进行比较,计算出损失函数;
-
接着使用这个损失函数来微调小型模型的参数,以使其能够更好地生成正确的解答;
-
重复多次这个过程,直到小型模型能够达到满意的推理能力。
模型串联
大型模型负责处理输入数据的主要特征提取和理解,而小模型则用于进一步处理和生成最终的输出结果。
「参考论文:」
CascadeBERT: Acceleratingnference of Pre-trained Language Models viaCalibrated Complete Models Cascade
通过校准的完整模型级联加速预训练语言模型推理
「简述:」CascadeBERT以级联方式选择适当大小和完整的模型,为预测提供全面的表示。另外,作者还设计了一个难度感知的目标,以实现更可靠的级联机制。实验结果表明,与现有方法相比,CascadeBERT在4倍加速下可以整体提高15%的准确率。

投机采样
一种在大模型结合小模型中常用的技术,用于解决数据不平衡和样本选择偏差的问题。在训练过程中,根据当前模型的性能和预测结果,有选择性地从少数类样本中选取更具代表性或更容易分类的样本进行训练。
「参考论文:」
Fast inference from transformers via speculative decoding
通过投机解码从transformers进行快速推理
「简述:」投机解码是一种算法,用于加速大型自回归模型(如Transformers)的推理速度。它通过并行计算多个token来加快采样速度,无需对输出进行任何更改。该方法可以在不重新训练或更改架构的情况下加速现有的现成模型。作者在T5-XXL上进行了演示,并展示了与标准T5X实现相比2X-3X的加速效果,同时保持了相同的输出结果。

三、权值共享
在小模型中共享大模型中部分层的权值,比如可以共享低层的特征提取层,然后在高层重新训练适合小模型的权值。
具体步骤:
-
首先设计一个小模型,该模型包含大模型中需要共享的一些重复的子结构。这些子结构可以是卷积核、循环矩阵等。
-
在训练过程中,将大模型和小模型中的对应层的参数共享起来。这意味着它们具有相同的权重和偏置项。
-
在进行前向传播或反向传播时,使用小模型来计算大模型中的对应层。由于参数共享,这些层的计算结果与使用完整大模型的计算结果相同。
「参考论文:」
Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks viaAttention Transfer
通过注意力转移提高卷积神经网络的性能
「简述:」论文研究了注意力在人类视觉体验和人工神经网络中的重要性,并提出了一种名为“注意力转移”的方法来提高卷积神经网络的性能。该方法通过定义适当的注意力机制,强制学生CNN网络模仿强大的教师网络的注意力映射,从而显著提高性能。

四、迁移学习
先在一个大型数据集上训练一个大模型,然后将这个大模型作为预训练模型,再在小型数据集上进行微调,从而得到一个小模型。
「参考论文:」
A Simple Framework for Contrastive Learning of Visual Representations
用于视觉表征对比学习的简单框架
「简述:」本文介绍了SimCLR框架,用于对比学习视觉表示。该框架不需要专门的架构或内存库,通过研究主要组成部分,发现数据增强、可学习的非线性变换和更大的批量大小和训练步骤可以提高表示的质量。在ImageNet上,使用SimCLR学习的自监督表示训练的线性分类器实现了76.5%的top-1准确率,比先前最先进的方法提高了7%。

Cross-property deep transfer learning framework for enhanced predictive analytics on small materials data
跨属性深度迁移学习框架,用于增强小材料数据的预测分析
「简述:」本文介绍了一种跨属性深度迁移学习框架,用于在材料科学中建立预测模型和加速发现。该框架利用大型数据集上训练的模型来构建不同属性的小数据集上的模型,并在多个数据集上进行了测试。测试结果表明,该框架可以解决应用AI/ML的材料科学中的小数据挑战。
五、将小模型作为插件
「参考论文:」
Small Models are Valuable Plug-ins for Large Language Models
小模型是大型语言模型的有价值的插件
「简述:」本文提出了一种名为Super In-Context Learning(SuperICL)的方法,用于在大型语言模型中进行本地微调,从而提高其在监督任务上的性能。该方法通过使用较小的本地微调模型来解决大型语言模型的不稳定性问题,并能够超越最先进的微调模型。实验结果表明,SuperICL可以提高性能,同时增强较小模型的能力,例如多语言性和可解释性。

六、提示语压缩
通过一个小模型对提示语进行压缩。
「参考论文:」
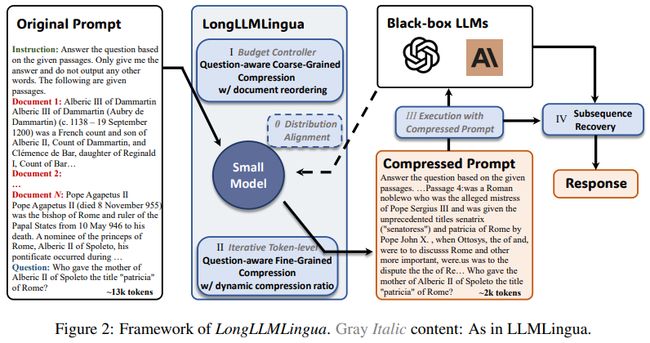
LongLLMLingua:ACCELERATING ANDLLMS IN LONG CONTEXT SCENARIOS VIA PROMPTCOMPRESSION
通过提示压缩加速长上下文场景中的LLMs
「简述:」论文提出了一种名为LongLLMLingua的方法,用于在长上下文场景中通过提示压缩来提高大型语言模型(LLMs)的性能。该方法利用了LLMs对输入提示中关键信息密度和位置的依赖性,并通过压缩提示来帮助LLMs更好地感知关键信息,从而同时解决计算/财务成本高、延迟时间长和性能低下等三个挑战。
七、集成学习
集成学习可以实现将大型模型与小型模型结合,通过将多个不同的模型组合起来,可以获得更好的性能和泛化能力。这可以通过模型平均或堆叠等技术来实现。
「参考论文:」
Ensemble deep learning: A review
深度学习集成
「简述:」本文综述了深度学习集成模型的最新研究进展,并介绍了不同种类的深度学习集成模型,包括基于bagging、boosting、stacking、负相关、显式/隐式、同质/异质和决策融合策略的深度学习集成模型。此外,还简要讨论了深度学习集成模型在不同领域的应用,并提出了未来研究的方向。

八、其他策略
SuperContext
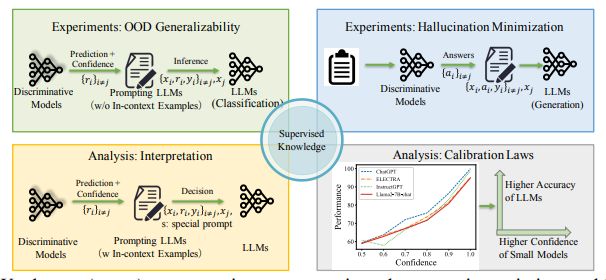
论文:SUPERVISED KNOWLEDGE MAKES LARGE LANGUAGE MODELS BETTER IN-CONTEXT LEARNERS
有监督知识使大型语言模型成为更好的上下文学习者
「简述:」本文提出了一种简单而有效的框架,通过使用特定任务的微调语言模型(SLMs)来提高大型语言模型(LLMs)在上下文学习中的可靠性。作者使用该方法对Llama 2和ChatGPT进行了增强,并在9个不同任务上提供了一套全面的资源,包括16个经过策划的数据集、提示、模型检查点和LLM输出。实验结果表明,该方法可以提高LLM的泛化能力和准确性,并展示了其在培养更可靠的LLM方面的潜力。
投机式推理
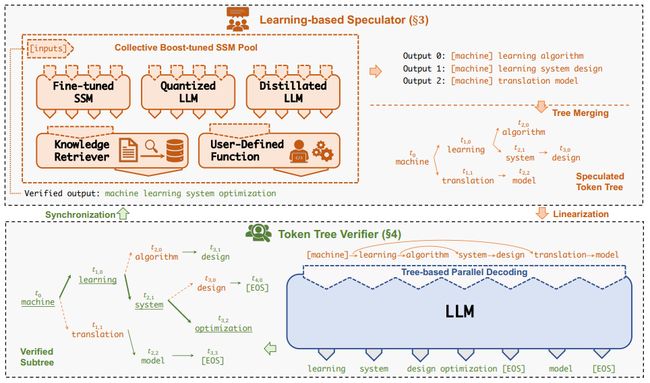
论文:SpecInfer: Accelerating Generative Large Language Model Serving with Speculative Inference and Token Tree Verification
通过投机推理和令牌树验证加速生成大型语言模型服务
「简述:」本文介绍了一种名为SpecInfer的生成式大型语言模型(LLM)服务系统,该系统使用投机推理和令牌树验证来加速LLM推理。SpecInfer的核心思想是将多个经过集体优化调整的小语言模型组合起来,共同预测LLM的输出结果,并将这些预测结果组织成一个令牌树,每个节点代表一个候选令牌序列。然后,使用一种新的基于树的并行解码机制,将令牌树中所有候选令牌序列的正确性与LLM进行并行验证。
大模型辅助小模型
论文:PROMPT2MODEL: Generating Deployable Models from Natural Language Instructions
从自然语言指令生成可部署的模型
「简述:」本文介绍了一种名为Prompt2Model的方法,它可以根据自然语言任务描述来训练适用于部署的特殊目的模型。该方法通过检索现有数据集和预训练模型、使用LLMs生成数据集以及在这些检索到的和生成的数据集中进行监督微调的多步骤过程来完成。在三个任务上,作者演示了Prompt2Model训练出的性能超过gpt-3.5-turbo强模型的平均20%,同时大小仅为700倍。

关注下方《学姐带你玩AI》
回复“模型结合”获取论文+代码合集
码字不易,欢迎大家点赞评论收藏