多特征变量序列预测(六) CEEMDAN+CNN-Transformer风速预测模型
目录
往期精彩内容:
前言
1 多特征变量数据集制作与预处理
1.1 导入数据
1.2 CEEMDAN分解
1.3 数据集制作与预处理
2 基于Pytorch的CEEMDAN + CNN-Transformer 预测模型
2.1 定义CEEMDAN + CNN-Transformer预测模型
2.2 设置参数,训练模型
3 模型评估与可视化
3.1 结果可视化
代码、数据如下:

往期精彩内容:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较-CSDN博客
风速预测(一)数据集介绍和预处理-CSDN博客
风速预测(二)基于Pytorch的EMD-LSTM模型-CSDN博客
风速预测(三)EMD-LSTM-Attention模型-CSDN博客
风速预测(四)基于Pytorch的EMD-Transformer模型-CSDN博客
风速预测(五)基于Pytorch的EMD-CNN-LSTM模型-CSDN博客
风速预测(六)基于Pytorch的EMD-CNN-GRU并行模型-CSDN博客
CEEMDAN +组合预测模型(BiLSTM-Attention + ARIMA)-CSDN博客
CEEMDAN +组合预测模型(CNN-LSTM + ARIMA)-CSDN博客
CEEMDAN +组合预测模型(Transformer - BiLSTM+ ARIMA)-CSDN博客
CEEMDAN +组合预测模型(CNN-Transformer + ARIMA)-CSDN博客
多特征变量序列预测(一)——CNN-LSTM风速预测模型-CSDN博客
多特征变量序列预测(二)——CNN-LSTM-Attention风速预测模型-CSDN博客
多特征变量序列预测(三)——CNN-Transformer风速预测模型-CSDN博客
多特征变量序列预测(四)Transformer-BiLSTM风速预测模型-CSDN博客
多特征变量序列预测(五) CEEMDAN+CNN-LSTM风速预测模型-CSDN博客
前言
本文基于前期介绍的风速数据(文末附数据集),介绍一种多特征变量序列预测模型CEEMDAN + CNN-Transformer,以提高时间序列数据的预测性能。
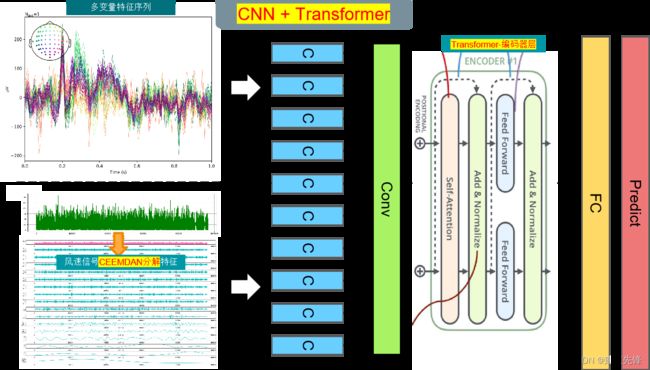
模型整体结构:数据集一共有天气、温度、湿度、气压、风速等九个变量,使用CEEMDAN算法对风速序列进行分解,然后合并所有的分量和原始数据集变量,形成一个加强的特征输入,通过滑动窗口制作数据集,利用多变量来预测风速。先通过CNN进行卷积池化操作提取特征变量的空间特征,增加维度,缩短序列长度,然后再送入Transformer层增强特征,实现CNN-Transformer的预测模型。
风速数据集的详细介绍可以参考下文:
风速预测(一)数据集介绍和预处理-CSDN博客
LSTF(Long Sequence Time-Series Forecasting)问题是指在时间序列预测中需要处理长序列的情况。在实际应用中,时间序列可能会包含非常大量的数据点,在这种情况下,传统的时间序列预测模型可能会遇到一些挑战,因为处理长序列时会出现一些问题,例如:
-
长期依赖性: 随着时间序列数据的增长,模型需要能够捕捉长期的依赖关系和趋势。
-
计算复杂性: 针对长序列进行训练和预测通常需要更多的计算资源和时间。
-
内存消耗: 长序列通常需要大量的内存来存储数据和模型参数,这可能会导致内存耗尽或者性能下降的问题。
在处理LSTF问题时,选择合适的窗口大小(window size)是非常关键的。选择合适的窗口大小可以帮助模型更好地捕捉时间序列中的模式和特征,为了提取序列中更长的依赖建模,本文把窗口大小提升到96,运用CNN-Transformer模型来充分提取序列中的特征信息。
1 多特征变量数据集制作与预处理
1.1 导入数据

1.2 CEEMDAN分解

1.3 数据集制作与预处理
先合并原始数据变量和分解的分量,按照9:1划分训练集和测试集

制作数据集

2 基于Pytorch的CEEMDAN + CNN-Transformer 预测模型
2.1 定义CEEMDAN + CNN-Transformer预测模型
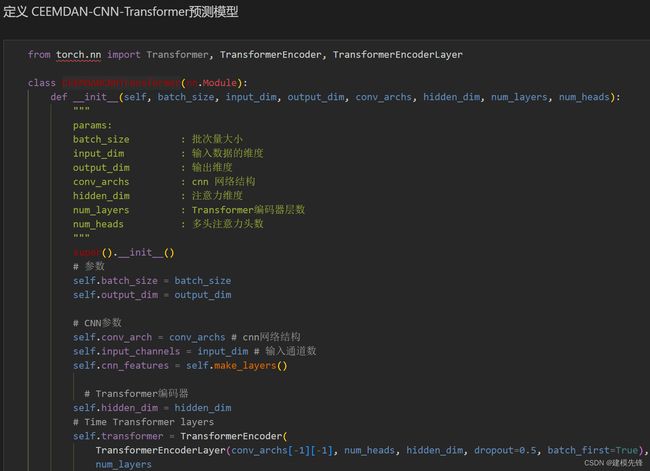
注意:输入风速数据形状为 [256, 96, 23], batch_size=256,96代表序列长度(滑动窗口取值), 维度23维代表挑选的8个变量和15个分量的维度。
2.2 设置参数,训练模型

50个epoch,MSE 为0.000319,多变量特征CEEMDAN + CNN-Transformer预测效果良好,加入CEEMDAN分解后,多变量预测效果提升明显,性能优越,适当调整模型参数,还可以进一步提高模型预测表现。
注意调整参数:
-
可以适当增加CNN层数和隐藏层的维度,微调学习率;
-
调整Transformer编码器层数和维度数,增加更多的 epoch (注意防止过拟合)
-
可以改变滑动窗口长度(设置合适的窗口长度)
3 模型评估与可视化
3.1 结果可视化
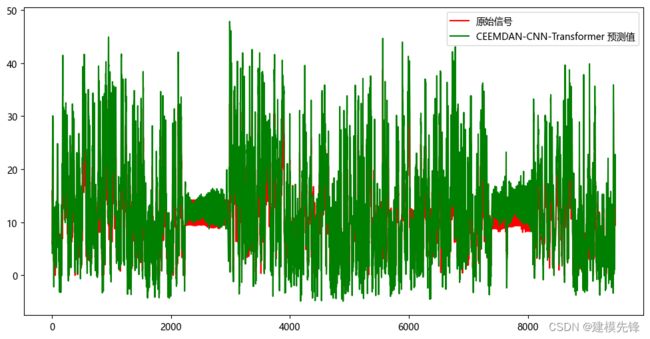
3.2 模型评估

代码、数据如下:
