Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models ——【代码复现】
本文是发表于SIGGRAPH(Special Interest Group on Computer Graphics and Interactive Techniques)2023 上的一篇文章
论文网址:Attend and Excite (yuval-alaluf.github.io)

一、引言
这篇论文主要是利用注意力来加强图像生成中语义的引导,本博客主要用于记录在复现过程中遇到的一些问题。
二、环境配置
想要部署整个项目,首先需要自身机器的显存大于4GB,(个人实测在没有改变默认参数的情况下是4GB是跑不动的,建议大于4GB,显存不够的情况可以改精度,本文就不叙述了。)
在配置项目之前,请自行安装Python环境、Anaconda、Pycharm又或者Vscode等,以及Cuda、Cudnn的安装。
三、下载相关文件
1. 下载项目文件
yuval-alaluf/attend-and-excite:“attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models”(SIGGRAPH 2023)正式实现 (github.com)
2.下载权重模型
由于这个项目的代码是依赖于 Hugging Face 的扩散器库来下载 Stable Diffusion v1.4 模型的,但是在我复现的过程中我发现直接通过代码下载模型是行不通的,主要的原因就是连接不上huggingface网站了。
这里提供两个方法下载权重:
方法一:手动下载模型
CompVis/stable-diffusion-v1-4 at main (huggingface.co)
开了科学上网的话我们还是可以通过网页浏览huggingface的,所以可以一个个把文件下载下来,然后放到对应文件夹中即可。
方法二:利用镜像网站:hf-mirror.com
网站里也有说明如何下载模型的,下面是我用的命令代码:
export HF_ENDPOINT=https://hf-mirror.com # 如果是windows下把export改成set
huggingface-cli download CompVis/stable-diffusion-v1-4 --local-dir "G:\Models\stable-diffusion-v1-4" --resume-download 一些主要的参数含义如下:
| 命令 | 含义 |
| -h 或 --help | 获取命令的帮助信息 |
| --repo-type | 仓库的类型,可以是模型(model)、数据集(dataset)或空间(space) |
| --revision | 下载的版本号或标签,默认为最新版本 |
| --include 和 --exclude | 指定要包含或排除的文件或目录 |
| --cache-dir | 缓存目录,下载的文件将放在该目录下 |
| --local-dir | 本地目录,如果设置了该参数,下载的文件将被放在该目录下 |
| --local-dir-use-symlinks | 与`--local-dir`一起使用,如果设置为"auto",则根据文件大小决定是复制文件还是创建符号链接到本地目录;如果设置为"True",则始终创建符号链接;如果设置为"False",则根据文件是否已存在于缓存中来决定是复制文件还是从Hub下载并不缓存 |
| --force-download | 如果文件已经存在于缓存中,是否强制重新下载 |
| --resume-download | 如果之前的下载被中断,是否继续下载 |
| --token | 用户访问令牌,用于授权访问私有资源 |
| --quiet | 如果设置为"True",则禁用进度条,只打印下载文件的路径 |
注:不知道为什么,我在实验室服务器上这样下载的时候,服务器的SSL证书总是崩溃,我也不太理解为啥...,但是我在自己电脑下载的时候是没有问题的,然后我是现在自己电脑下载之后传到服务器上的。
四、构建项目工程
这个项目主要还是基于Stablediffusion来改进的,所以跟Stable Diffusion的步骤大差不差
1.创建环境
可以直接利用下面的命令来创建环境、下载依赖包。
conda env create -f environment.yaml
conda activate ldm当然如果你和我一样之前已经安装过Stable Diffusion的环境,这里只需要额外装一下其他的包即可,可以直接用以下命令下载(注意终端所在的文件夹应该在Attend-and-Excite\environment)
pip install -r requiremnets.txt注:我在装好所有依赖包之后还存在一些报错,具体报错如下:
1.第一个主要是(pipeline_attend_and_excite.py)这里提示我没有这个randn_tensor,我们可以把这个randn_tensor去掉,然后添加下面这行代码(虽然感觉文件中并没有用到这个randn_tensor,不过还是加上hh)
![]()
from diffusers.utils.torch_utils import randn_tensor
2.第二个是ptp_utils.py文件里的,也是说我没cross_attention.
![]()
改进如下:
from diffusers.models.attention import Attention as CrossAttention, FeedForward, AdaLayerNorm在我解决这些问题的时候我发现这些问题主要还是diffuser的版本比较高导致的,旧版本的diffuser好像不会出现这些问题。
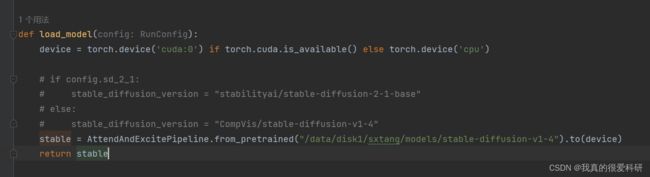
2.更改模型路径
由于我们已经把模型下载下来了,所以我们需要把模型加载代码改成本地路径,具体改进如下(run.py)
五、运行
一切准备就绪后就可以运行了,我们运行如下代码:
python run.py --prompt "a cat and a dog" --seeds [0] --token_indices [2,5]如果没有问题的话终端显示如下:
 最后就会生成图片,默认保存到./outputs文件夹下,当然,这些参数都可以在config.py中更改。
最后就会生成图片,默认保存到./outputs文件夹下,当然,这些参数都可以在config.py中更改。
