深度解析 P-tuning v2 为什么对大模型有效
理论部分
论文及项目地址
论文地址:https://arxiv.org/pdf/2110.07602.pdf
项目地址:https://github.com/THUDM/P-tuning-v2
技术背景
P-tuning v2的产生源于对bert类模型开创的微调(fine-tuning)方法的一系列改进。
fine-tuning。预训练的语言模型(Pretrained language model)提高了广泛的自然语言理解 ( NLU ) 任务的性能,例如bert、gpt。一个广泛使用的方法是微调fine-tuning,作用是更新整个模型参数以适应下游目标任务。虽然微调获得了良好的性能,但它有两个明显缺点。一是由于在训练过程中必须存储所有参数的梯度和优化器状态,十分消耗内存;二是在推理过程中需要为每个任务保留一份模型参数,而预训练的模型通常很大,造成很大不便。
Prompting。针对fine-tuning的缺点,产生了Prompting方式(原理后文介绍)。Prompting虽然冻结了所有预训练参数,但是离散的prompting性能往往逊色于fine-tuning。
Prompt tuning。连续的prompt只被插入到输入的嵌入序列中,但是由于长度限制,微调参数受到限制,而且输入嵌入对模型预测有相对间接的影响。缺乏跨规模普适性。只有在模型规模达到10B个参数以上性能才能和fine-tuning媲美,在中等规模模型(从100M到1B)范围表现比fine-tuning差很多,尤其是在硬序列标签任务上,比如抽取式问答任务。
方法和性质
1、Prompt tuning方式:例如做电影评论分类任务,输入的是“Amazing movie!”,输入的嵌入层被设定为[e(x), e(“It”), e(“is”), e(“[MASK]”)],其中x就是“Amazing movie!” 如图2(a)
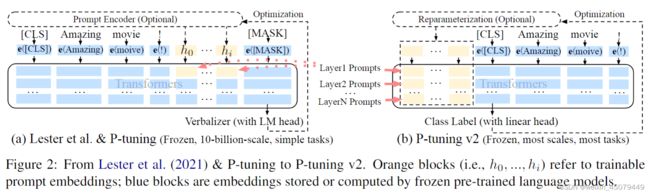
2、P-Tuning v2应用了深度prompt tuning方法,把每一层都添加了prompt作为前缀tokens,如图2(b)。这使P-Tuning v2有更多的参数(从占比0.01%到0.1~0.3%),容量增大提高了参数效率,同时prompt在深层的增加也对模型预测产生了更直接的影响。
研究结果
在NLU任务中,所有模型规模下,优化后的prompt tuning(P-tuning v2)性能都可以与fine-tuning媲美,具有普适性。
1、P-tuning v2在不同规模上(从300M到10B)的性能与fine-tuning相匹配,只需要0.1%的特定任务参数;
2、P-tuning v2在所有任务(NER、抽取式问答、语义角色标签)上的性能与fine-tuning相匹配;

3、消融实验。带有LM头的Verbalizer标签虽然之前一直在用,与线性头的[CLS]标签相比,性能没有明显差异。
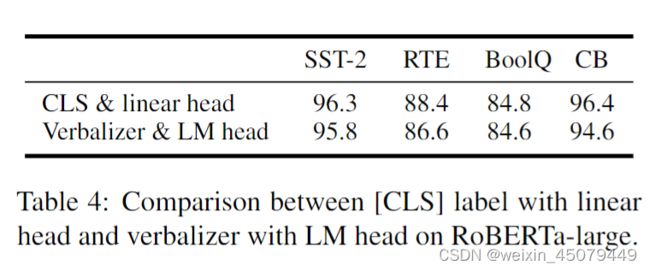
注:LM 头是指 LM HEAD层,即嵌入层后面接的softmax层
创新点
1、对每一个输入层都采用连续提示的这种deep prompt tuning

2、实验验证了prompt的深度对性能的影响。相同的prompt数量,添加在离输出层越近的模型性能越好

重要性(对后续研究的影响)
P-tuning V2的创新会对LLM的应用产生重要影响,不需要再次微调,仅用P-tuning V2方法就可以训练好模型应用于下游任务。因为对于LLM模型,微调是是否昂贵且不现实的,仅有的大公司(openAI、谷歌、meta)才有实力进行微调,但他们也不会这么做,而是用InstructGPT等方法来训练,例如2022-2023年训练一次ChatGPT成本在1000-2000万美元。
想法和问题(作者提出问题和解决问题的思路)
1、参数调整层。之前的工作通常用一个参数调整层,如MLP层,来转换嵌入层参数,但是对于NLU任务这一层是否有用严重依赖于特定的任务和数据集(如RTE 和 CoNLL04),但是对于其他数据集(例如BoolQ 和 CoNLL12)没有提升甚至有负面影响。
2、提示长度。提示长度在P-Tuning v2中起着十分关键作用,不同的NLU任务通常在不同的提示长度下达到最佳性能。一般来说,简单的分类任务倾向于较短的提示(少于20个);硬序列标签任务则倾向于较长的提示(大约100个)。
3、多任务学习。多任务学习(prgc、uie等模型就是多任务学习)在对单个任务进行微调之前,用共享的连续提示共同优化多个任务,它对于P-Tuning v2来说是非必选的,但可以通过提供更好的初始化来进一步提高性能。
4、分类头。使用分类头来预测一直是prompt tuning的核心,但在全数据设置中是不必要的,而且与序列标签不兼容。P-tuning v2则像BERT那样在标记之上应用一个随机初始化的分类头(图2)。
实战部分
(待补充)