算法练习-有效的字母异位词(思路+流程图+代码)
难度参考
难度:简单
分类:哈希表
难度与分类由我所参与的培训课程提供,但需要注意的是,难度与分类仅供参考。以下内容均为个人笔记,旨在督促自己认真学习。
题目
给定两个等长的字符串s和t,并且字符串中只包含小写字母,编写一个函数来判断t是否是s
的字母异位词。
注意:若s和t中每个字符出现的次数都【相同】,则称s和t互为字母异位词。
示例1:
输入:s="anagram",t="nagaram"
输出:true
示例2:
输入:s="rat",t="car"
输出:false
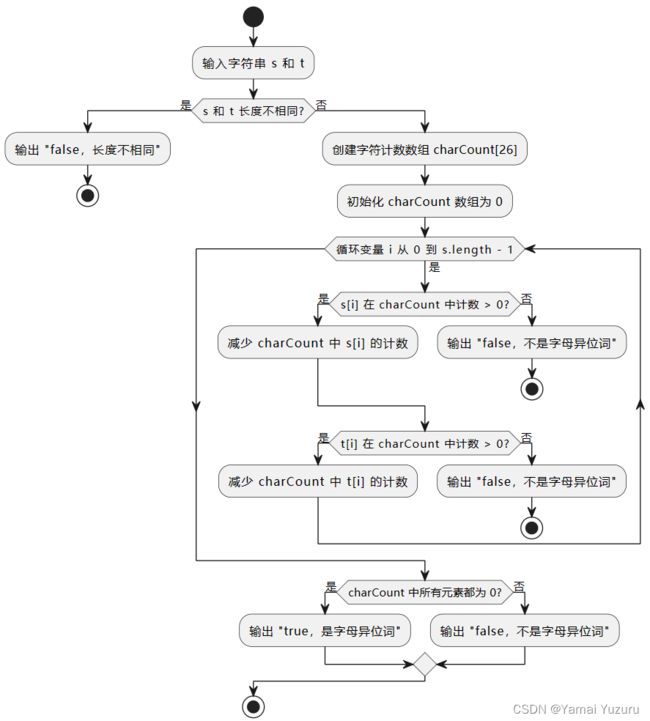
思路
这个问题要求判断两个字符串是否为字母异位词,即它们包含的字母种类相同且每种字母的数量相同。
常见的解决方法是使用哈希表来记录每个字符出现的次数。具体思路如下:
-
首先,判断两个字符串的长度是否相同,如果不相同,则它们不可能是字母异位词,直接返回 false。
-
创建一个大小为 26 的整数数组(因为只包含小写字母,所以只需考虑 26 个字母的情况),用来记录每个字符在字符串中出现的次数。
-
遍历字符串 s,对于每个字符,将对应位置的计数器加 1。
-
遍历字符串 t,对于每个字符,将对应位置的计数器减 1。
-
最后,如果整个数组的元素都为 0,说明两个字符串是字母异位词,返回 true;否则返回 false。
哈希表(Hash Table),也称为散列表,是一种常用的数据结构,用于将键(key)映射到值(value)的存储结构。它通过使用哈希函数将键映射到哈希表的特定位置,以实现高效的数据检索。哈希表的主要思想是将键映射到一个固定范围的索引,使得查找和插入等操作的时间复杂度是常数级别的,即O(1)。
在判断两个字符串是否为字母异位词的问题中,哈希表可以用来记录字符出现的次数。以下是如何在这个问题中使用哈希表:
-
创建一个长度为26的整数数组(哈希表),用于记录字符出现的次数。这是因为题目中明确说明字符串只包含小写字母,所以我们可以使用一个固定长度的数组来表示字符 'a' 到 'z'。
-
初始化哈希表的所有元素为0。
-
遍历第一个字符串s,对每个字符进行如下操作:
- 使用字符的ASCII码减去 'a' 的ASCII码作为索引,将对应位置的计数加1。
-
遍历第二个字符串t,对每个字符进行如下操作:
- 使用字符的ASCII码减去 'a' 的ASCII码作为索引,将对应位置的计数减1。
-
最后,检查哈希表中所有元素是否都为0。如果都为0,则说明两个字符串互为字母异位词,否则不是。
哈希表的使用使得我们可以高效地统计字符出现的次数,并在O(1)的时间内进行字符计数的增减操作。这种方法在解决字母异位词的问题中非常高效。
示例
假设我们有两个字符串 s 和 t,我们的目标是判断它们是否是字母异位词。
首先,我们需要创建一个大小为 26 的整数数组,用于记录每个字母的出现次数(因为只包含小写字母,所以数组大小为 26 足够了)。
然后,我们遍历字符串 s,对于每个字符,我们将对应字母的计数器加 1。例如,如果 s = "anagram",则遍历过程如下:
字符 'a':charCount[0]++
字符 'n':charCount[13]++
字符 'a':charCount[0]++
字符 'g':charCount[6]++
字符 'r':charCount[17]++
字符 'a':charCount[0]++接下来,我们遍历字符串 t,对于每个字符,我们将对应字母的计数器减 1。例如,如果 t = "nagaram",则遍历过程如下:
字符 'n':charCount[13]--
字符 'a':charCount[0]--
字符 'g':charCount[6]--
字符 'a':charCount[0]--
字符 'r':charCount[17]--
字符 'a':charCount[0]--
字符 'm':charCount[12]--最后,我们检查整个数组的元素是否都为 0。如果是,那么 s 和 t 是字母异位词,返回 true;否则,返回 false。
在这个示例中,由于 s 和 t 都是字母异位词,所以最终返回 true。
梳理
这种方法能够实现判断两个字符串是否为字母异位词的原理在于它利用了两个字符串中每个字符出现的次数必须相同这一条件。
具体原理如下:
-
遍历字符串 s,将 s 中每个字符出现的次数记录在一个字符计数数组
charCount中。charCount的索引对应字符的 ASCII 码值,数组的值表示该字符在字符串 s 中出现的次数。 -
遍历字符串 t,对应地减少
charCount数组中对应字符的计数。 -
如果最终
charCount数组中的所有元素都为 0,说明字符串 s 和 t 中每个字符出现的次数都相同,因此它们是字母异位词。
这种方法的时间复杂度是 O(n),其中 n 是字符串的长度,因为我们需要遍历两次字符串,并且数组的访问是常数时间。
这个方法之所以有效,是因为字母异位词的定义就是两个字符串中字符出现的次数相同,通过记录字符出现次数并对比,我们能够判断它们是否满足这一条件。
代码
#include
using namespace std;
// 定义函数,判断两个字符串是否为字母异位词
bool isAnagram(string s, string t) {
// 如果两个字符串的长度不相等,直接返回false
if (s.length() != t.length()) {
return false;
}
const int alphabetSize = 26; // 字母表大小,小写字母有26个
int charCount[alphabetSize] = {0}; // 用数组统计字符出现的次数
// 统计字符串s中的字符出现次数
for (char c : s) {
charCount[c - 'a']++;
}
// 遍历字符串t,减少数组中对应字符的计数
for (char c : t) {
// 如果字符计数为0或负数,则说明不是字母异位词,直接返回false
if (charCount[c - 'a'] <= 0) {
return false;
}
charCount[c - 'a']--;
}
// 如果经过上述检查,两个字符串互为字母异位词,返回true
return true;
}
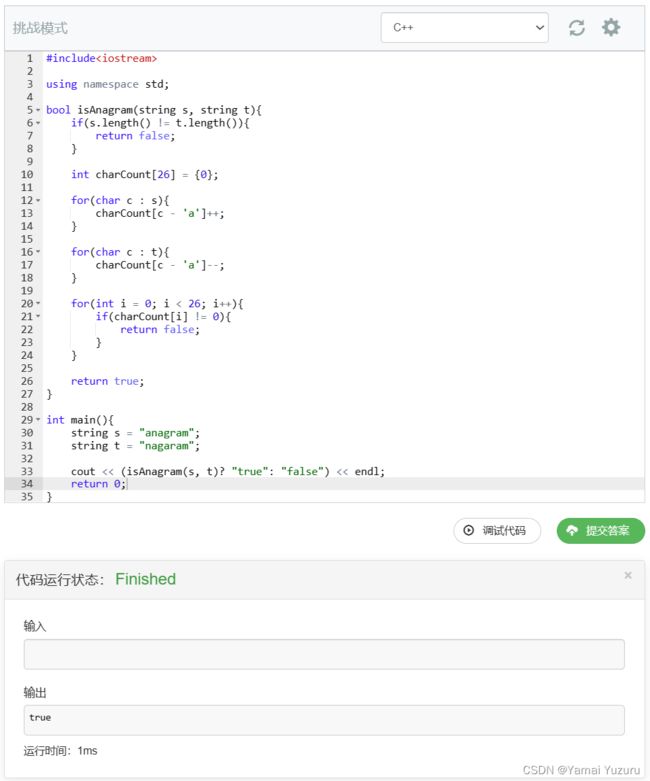
int main() {
string s1 = "anagram";
string t1 = "nagaram";
cout << "s1 和 t1 是否是字母异位词:" << isAnagram(s1, t1) << endl; // 输出true
string s2 = "rat";
string t2 = "car";
cout << "s2 和 t2 是否是字母异位词:" << isAnagram(s2, t2) << endl; // 输出false
return 0;
} 时间复杂度为O(n)。
空间复杂度为O(1)。
注意,char 和 string 不能随意变换。这是因为 char 和 string 是不同的数据类型,有不同的用途和操作。
char表示一个字符,是一个单一的字符数据类型,可以用来表示单个字符,如'a'或'b'。string是一个字符串数据类型,表示由多个字符组成的文本序列。它是一种更高级别的数据类型,可以包含多个字符,例如"abc"或"hello"。
在代码中,如果你希望比较两个字符串是否为字母异位词,必须使用 string 类型的变量来表示这两个字符串。因为 string 可以存储多个字符,而字母异位词的判断需要考虑字符串中的每个字符。
在 isAnagram 函数中,s 和 t 都是 string 类型的参数,用于表示两个字符串,然后对这两个字符串进行字符计数的比较。如果你将它们改为 char 类型,就无法正确地表示多字符字符串,也无法进行字符计数的比较,因此不能随意变换 char 和 string。
打卡
注意输出的时候,括号在这里是必需的,因为它们控制条件运算符(?:)的优先级。
在 C++ 中,条件运算符(?:)的优先级比位移运算符(<<)低。如果没有括号,那么表达式将会被解析为:
(cout << isAnagram(s, t)) ? "true" : ("false" << endl);
这将导致编译错误,因为尝试使用 << 运算符将字符串 "false" 和 endl 进行位移,而这是非法的。
为了正确分组表达式,将条件运算符的结果与 cout 进行位移,我们需要使用括号将条件部分括起来,即:
cout << (isAnagram(s, t) ? "true" : "false") << endl;
这样就能确保条件运算符的结果先与 << 运算符结合,然后再输出到 cout 流中。