Generative AI 新世界 | 文生图领域动手实践:预训练模型的部署和推理
在上期文章,我们探讨了文生图(Text-to-Image)方向的主要论文解读,包括:VAE、DDPM、DDIM、GLIDE、Imagen、UnCLIP、CDM、LDM 等主要扩散模型领域的发展状况。
本期我们将进入动手实践环节,我会带领大家使用 Amazon SageMaker Studio、Amazon SageMaker JumpStart 等服务,指导您在云中快速上手亲身体验大语言模型的魅力,并为有探索精神的小伙伴们准备了更高阶实验,以帮助您构建文生图(Text-to-Image)领域的大模型企业或科研应用。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点 这里让它成为你的技术宝库!
整个文生图(Text-to-Image)动手实践会分成两篇:
本篇将主要介绍预训练模型的部署和推理,其中包括:运行环境准备、角色权限配置、支持的主要推理参数、图像的压缩输出、提示工程(Prompt Engineering)、反向提示(Negative Prompting) 等内容。
下一篇将主要介绍预训练模型在客户数据集上的微调(Fine-tune),以及亚马逊云科技提供的更高阶的面向企业或科研单位生产环境级别的一些完整解决方案。
Amazon SageMaker JumpStart 介绍
Amazon SageMaker JumpStart 是一个机器学习 (ML) 中心,可以帮助您加速 ML 之旅。使用 Amazon SageMaker JumpStart,您可以访问预训练的模型,包括基础模型,以执行文章总结和图片生成等任务。预训练模型可针对您的使用案例和数据完全自定义,并且您可以使用用户界面或 SDK 轻松将其部署到生产中。此外,您可以在组织内访问预构建的解决方案来解决常见使用案例和共享 ML 构件,包括 ML 模型和笔记本,以加速 ML 模型的构建和部署。
Amazon SageMaker JumpStart 未使用您的任何数据来训练基础模型。由于所有数据都经过加密且不会离开您的虚拟私有云 (VPC),因此您可以相信您的数据将会保持私密和机密。
Amazon SageMaker JumpStart 提供来自不同模型提供商的各种专有和公开可用的基础模型。基础模型是包含数十亿个参数并在数 TB 的文本和图像数据上进行预训练的大规模 ML 模型,因此您可以执行范围广泛的任务,例如文章摘要和文本、图像或视频生成。由于基础模型是经过预训练的,因此它们可以帮助降低训练和基础设施成本,并支持针对您的用例进行定制。
在 Amazon SageMaker Studio 中快速上手 JumpStart
打开 Amazon SageMaker Studio,选择左侧菜单栏的 “SageMaker JumpStart” ,如下图所示:
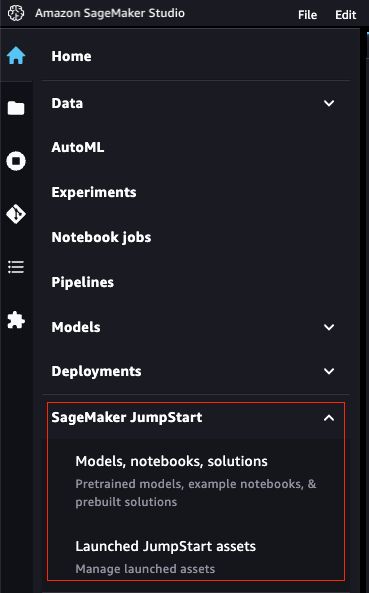
这将打开一个新选项卡,显示 SageMaker JumpStart 支持的所有模型(包括解决方案、基础模型基本信息等),如下图所示:

选择 “Stable Diffusion 2.1 base” 这个文生图的基础模型,如下图所示:
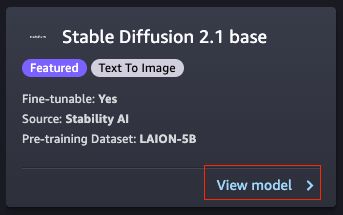
在新打开的选项卡中,你将看到部署 (Deploy)、训练 (Train)、Notebook、模型介绍 (Model details) 这四个子选项,分别单击这四个子选项,可以帮助您快速进入相关部分进行配置,如下图示:

以部署 (Deploy) 为例,可以在 “Deployment Configuration” 中,自行定义运行 SageMaker 所需的机型、终端节点名等。
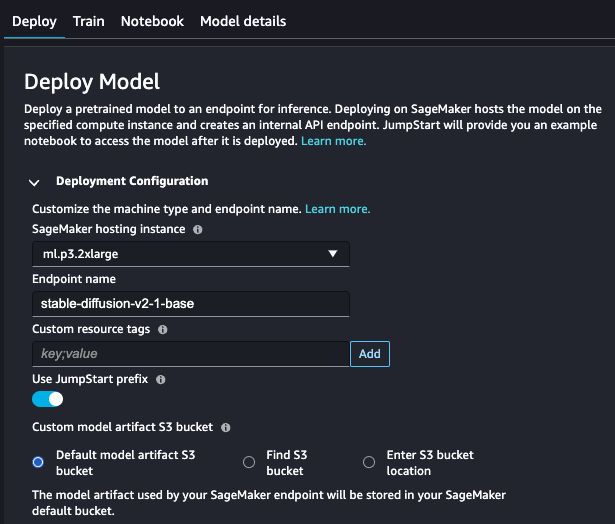
以及可以在 “Security Settings” 中定义在 SageMaker 中运行的角色 (role),控制这个角色的权限即可控制其访问亚马逊云科技资源的权限颗粒度;以及可以配置 VPC、加密 keys 等重要安全管理机制。如下图所示:

篇幅所限,我们就不对 SageMaker JumpStart 做更详细的介绍,有深入研究兴趣的同学可以参考一下资料:关于 Amazon SageMaker JumpStart 的官方页面,可参考:
https://aws.amazon.com/cn/sagemaker/jumpstart/?trk=cndc-detail
关于 Amazon SageMaker JumpStart 支持基础模型的最新更新,可参考:
https://aws.amazon.com/cn/sagemaker/jumpstart/getting-started...
在 Amazon SageMaker JumpStart 中运行 Notebook
本节我将带领大家在 Amazon SageMaker JumpStart 中运行 Notebook。
首先,参考下图选择 “Notebook” 子选项。

点击 “Open notebook” 进入 Notebook。
当 “Starting notebook kernel” 完成后,就可以运行这个示例的 Notebook 了!接下来的体验,和大家在其它各种环境中运行 Jupyter Notebook 是很类似的。

如果你计划在这个 Notebook 做的工作负载需要较多的 CPU 或者 GPU 资源,可以通过点击 Notebook 右上角的配置位置(如下图),来选择需要的 Notebook 实例类型、代码运行的 Image 环境、Python 版本等。
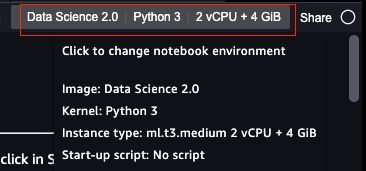
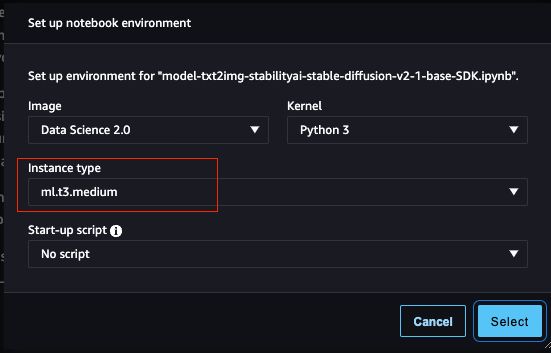
这个实验我们选择比较小的 “ml.t3.medium” 实例即可,如下图示:
SageMaker JumpStart 上部署模型和运行推理
代码说明
本实验的完整代码,可以在亚马逊云科技的 SageMaker 代码库中获得。
GitHub 地址如下:
https://github.com/aws/amazon-sagemaker-examples/blob/main/introduction_to_amazon_algorithms/jumpstart_text_to_image/Amazon_JumpStart_Text_To_Image.ipynb?trk=cndc-detail
以上全部代码分为两部分:
- 预训练模型的部署和运行推理
- 预训练模型在客户数据集上的微调(Fine-tune)
本章涉及第一部分:预训练模型的部署和推理。
环境和权限配置准备
这个 Notebook 在带有 Python 3 (Data Science) 内核的 SageMaker Studio 中,使用 ml.t3.medium 实例上进行了测试。要部署预先训练或经过微调的模型,可使用 ml.p3.2xlarge 或 ml.g4dn.2xlarge 实例类型。如果 ml.g5.2xlarge 在你所在的地区可用,我们建议使用该实例类型进行部署。
在运行这个 Notebook 的代码之前,需要先执行一些初始步骤进行设置,例如:安装 ipywidgets 库和最新版本的 sagemaker。代码如下:
!pip install ipywidgets==7.0.0 --quiet
!pip install --upgrade sagemaker要在 Amazon SageMaker 上托管,我们还需要设置其对亚马逊云科技的相关服务授权,并对其使用进行身份验证。在这里,我们将与当前 Notebook 关联的执行角色配置了具有 SageMaker 访问权限的角色 (role)。
import sagemaker, boto3, json
from sagemaker import get_execution_role
aws_role = get_execution_role()
aws_region = boto3.Session().region_name
sess = sagemaker.Session()预训练模型的部署
使用亚马逊云科技的 SageMaker JumpStart,我们可以直接在预训练模型上进行推理 (inference),而无须先在新的数据集上做微调 (fine-tuning)。
你可以继续使用默认模型配置,也可以参考以下代码,从生成的下拉列表中选择不同的模型版本。
from ipywidgets import Dropdown
from sagemaker.jumpstart.notebook_utils import list_jumpstart_models
# Retrieves all Text-to-Image generation models.
filter_value = "task == txt2img"
txt2img_models = list_jumpstart_models(filter=filter_value)
# display the model-ids in a dropdown to select a model for inference.
model_dropdown = Dropdown(
options=txt2img_models,
value="model-txt2img-stabilityai-stable-diffusion-v2-1-base",
description="Select a model",
style={"description_width": "initial"},
layout={"width": "max-content"},
)
display(model_dropdown)以上代码的运行结果,如下图所示:

如果你好奇在 Sagemaker JumpStart 支持那些预训练模型,可以参考以下的完整列表:
https://sagemaker.readthedocs.io/en/stable/doc_utils/pretrain...
首先,我们需要设置预训练模型的 deploy_image_uri 和 model_uri。为了托管预训练模型,我们将创建一个 sagemaker.model.Model 的实例并开始部署。
from sagemaker import image_uris, model_uris, script_uris, hyperparameters, instance_types
from sagemaker.model import Model
from sagemaker.predictor import Predictor
from sagemaker.utils import name_from_base
endpoint_name = name_from_base(f"jumpstart-example-infer-{model_id}")
# Please use ml.g5.24xlarge instance type if it is available in your region. ml.g5.24xlarge has 24GB GPU compared to 16GB in ml.p3.2xlarge and supports generation of larger and better quality images.
inference_instance_type = instance_types.retrieve_default(
region=None,
model_id=model_id,
model_version=model_version,
scope="inference"
)
# Retrieve the inference docker container uri. This is the base HuggingFace container image for the default model above.
deploy_image_uri = image_uris.retrieve(
region=None,
framework=None, # automatically inferred from model_id
image_scope="inference",
model_id=model_id,
model_version=model_version,
instance_type=inference_instance_type,
)
# Retrieve the model uri. This includes the pre-trained model and parameters as well as the inference scripts.
# This includes all dependencies and scripts for model loading, inference handling etc..
model_uri = model_uris.retrieve(
model_id=model_id, model_version=model_version, model_scope="inference"
)
# To increase the maximum response size (in bytes) from the endpoint.
env = {
"MMS_MAX_RESPONSE_SIZE": "20000000",
}
# Create the SageMaker model instance
model = Model(
image_uri=deploy_image_uri,
model_data=model_uri,
role=aws_role,
predictor_cls=Predictor,
name=endpoint_name,
env=env,
)
# Deploy the Model. Note that we need to pass Predictor class when we deploy model through Model class,
# for being able to run inference through the sagemaker API.
model_predictor = model.deploy(
initial_instance_count=1,
instance_type=inference_instance_type,
predictor_cls=Predictor,
endpoint_name=endpoint_name,
)创建以及模型部署需要 10 分钟左右的时间。特别提醒:在等待模型部署期间,请不要中断内核的运行。
运行以上代码后,你会在 SageMaker 控制台的 “Endpoints” 项,看到有端点在部署,状态为 “Creating”,如下图所示:

等待大约 10 分钟左右的时间,如果看到以下 “!” 返回,表示模型已经在 SageMaker 的端点部署完成:
![]()
这时如果你继续留意 SageMaker 控制台的 “Endpoints” 项,会观察到状态已经由 “Creating” 变成 “InService”,如下图所示:
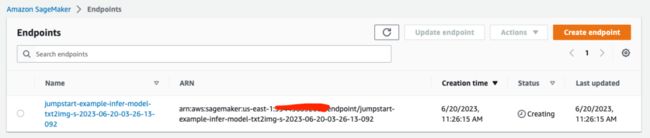
现在模型已经部署完成,可以开始进行推理了!
预训练模型的运行推理
模型的输入数据格式是:json 格式,并用 utf-8 编码的文本字符串。
模型的输出数据格式是:json 格式,并且包含生成的文本。
import matplotlib.pyplot as plt
import numpy as np
def query(model_predictor, text):
"""Query the model predictor."""
encoded_text = text.encode("utf-8")
query_response = model_predictor.predict(
encoded_text,
{
"ContentType": "application/x-text",
"Accept": "application/json",
},
)
return query_response
def parse_response(query_response):
"""Parse response and return generated image and the prompt"""
response_dict = json.loads(query_response)
return response_dict["generated_image"], response_dict["prompt"]
def display_img_and_prompt(img, prmpt):
"""Display hallucinated image."""
plt.figure(figsize=(12, 12))
plt.imshow(np.array(img))
plt.axis("off")
plt.title(prmpt)
plt.show()如下代码以及代码运行后返回的图例所示,输入文本 “cottage in impressionist style”,模型就会预测与该文本对应的图像。
text = "cottage in impressionist style"
query_response = query(model_predictor, text)
img, prmpt = parse_response(query_response)
display_img_and_prompt(img, prmpt)
预训练模型的高级推理参数
该模型在执行推理时还支持许多高级参数。它们包括:
- prompt: 提示指导图像生成。必须指定,可以是字符串或字符串列表
- width: 图像的宽度。如果指定,则必须是可被 8 整除的正整数
- height: 图像的高度。如果指定,则必须是可被 8 整除的正整数
- num_inference_steps: 图像生成过程中的降噪步骤数。步骤越多,图像质量越高。如果指定,则必须为正整数
- guidance_scale: 较高的制导比例 (guidance scale) 会导致图像与提示密切相关,但会牺牲图像质量。如果指定,则必须为浮点数;而设置guidance_scale<=1 将忽略
- negative_prompt: 根据此提示引导图像生成。如果指定,则必须是字符串或字符串列表,并与 guidance_scale 一起使用。如果 guidance_scale 被禁用,它也会被禁用;此外,如果 prompt 是字符串列表,那么 negative_prompt 也必须是字符串列表
- num_images_per_prompt: 每个提示返回的图像数量,如果指定,则必须为正整数
- seed: 修复随机化状态以提高可重复性 (reproducibility),如果指定,则必须是整数
以下举例说明:
import json
payload = {
"prompt": "astronaut on a horse",
"width": 512,
"height": 512,
"num_images_per_prompt": 1,
"num_inference_steps": 50,
"guidance_scale": 7.5,
"seed": 1,
}
def query_endpoint_with_json_payload(model_predictor, payload, content_type, accept):
"""Query the model predictor with json payload."""
encoded_payload = json.dumps(payload).encode("utf-8")
query_response = model_predictor.predict(
encoded_payload,
{
"ContentType": content_type,
"Accept": accept,
},
)
return query_response
def parse_response_multiple_images(query_response):
"""Parse response and return generated image and the prompt"""
response_dict = json.loads(query_response)
return response_dict["generated_images"], response_dict["prompt"]
query_response = query_endpoint_with_json_payload(
model_predictor, payload, "application/json", "application/json"
)
generated_images, prompt = parse_response_multiple_images(query_response)
for img in generated_images:
display_img_and_prompt(img, prompt)不同模型的训练数据具有不同的图像大小,通常可以观察到,当生成的图像的维度与训练数据维度相同时,模型的性能最佳。如果尺寸与默认尺寸不匹配,则可能会导致图像呈黑色。Stable Diffusion v1.4 模型是在 512512 的图像数据集上训练的,而 Stable Diffusion v2 模型是在 768768 的图像数据集上训练的。
在上述代码中,我们设置了希望输出的图像长度和宽度都是 512。以下是得到的模型输出图像:

图像的压缩输出 Compressed Image Output
上面来自端点的默认响应类型是具有 RGB 值的嵌套数组。因此,如果生成的图像尺寸很大,则可能会达到响应大小限制。为了解决这个问题,SageMaker 还支持返回 JPEG 图像的端点响应,是以字节为单位返回 (returned as bytes)。
如果需要以字节为单位返回,请设置:
Accept = 'application/json;jpeg'关于图像的压缩输出部分的代码如下:
from PIL import Image
from io import BytesIO
import base64
import json
def display_encoded_images(generated_images, title):
"""Decode the images and convert to RGB format and display
Args:
generated_images: are a list of jpeg images as bytes with b64 encoding.
"""
for generated_image in generated_images:
generated_image_decoded = BytesIO(base64.b64decode(generated_image.encode()))
generated_image_rgb = Image.open(generated_image_decoded).convert("RGB")
display_img_and_prompt(generated_image_rgb, title)
def compressed_output_query_and_display(payload, title):
query_response = query_endpoint_with_json_payload(
model_predictor, payload, "application/json", "application/json;jpeg"
)
generated_images, prompt = parse_response_multiple_images(query_response)
display_encoded_images(generated_images, title)
payload = {
"prompt": "astronaut on a horse",
"width": 512,
"height": 512,
"num_images_per_prompt": 1,
"num_inference_steps": 50,
"guidance_scale": 7.5,
"seed": 1,
}
compressed_output_query_and_display(payload, "generated image with compressed response type")采用以字节为单位返回(returned as bytes)后,输出的图像如下图所示:

提示工程 Prompt Engineering
写一个好的提示词,在大模型时代可能是一门艺术。
在给定模型下,通常很难预测某个提示词是否会产生令人满意的图像。不过,已经有分析和实践显示,某些模板可能是非常有效的。
提示词可以大致分为三部分:
- 图像类型(照片/素描/绘画等)
- 描述(主题/物体/环境/场景等)
- 图像风格(写实/艺术/艺术类型等)
因此,可以分别更改以上这三个部分的提示词,来生成图像的变体。众所周知,形容词在图像生成过程中起着重要作用。此外,添加更多细节也会有助于高质量的生成图像过程。
要生成逼真的图像,您可以使用诸如 “的照片”、“的照片”、“逼真” 或 “超逼真” 之类的短语。要生成艺术家的图像,您可以使用诸如 “巴勃罗·皮卡索的作品” 或 “伦勃朗的油画” 或 “弗雷德里克·埃德温·丘奇的风景艺术” 或 “阿尔布雷希特·丢勒的铅笔画” 之类的短语。
你也可以组合不同的艺术家。要按类别生成艺术图像,可以在提示中添加艺术类别,例如 “海滩上的狮子,抽象”。其他一些类别包括 “油画”、“铅笔画”、“波普艺术”、“数字艺术”、“动漫”、“卡通”、“未来主义”、“水彩”、“漫画” 等。您还可以包括灯光或相机镜头(如 35 毫米宽镜头或 85 毫米宽镜头)和取景细节(人像/风景/特写等)。
请注意:即使多次给出相同的提示词,模型也会生成不同的图像。因此,您可以生成多个图像并选择最适合您的应用程序的图像。
以下举例。有如下这段英文的描述词:
prompts = [
"symmetry!! portrait of vanessa hudgens in the style of horizon zero dawn, machine face, intricate, elegant, highly detailed, digital painting, artstation, concept art, smooth, sharp focus, illustration, art by artgerm and greg rutkowski and alphonse mucha, 8 k",
]
for prompt in prompts:
payload = {"prompt": prompt, "width": 512, "height": 512, "seed": 1}
compressed_output_query_and_display(payload, "generated image with detailed prompt")输出的图像结果如下。是不是已经有些令人惊艳的感觉了?

反向提示参数 Negative Prompt Parameter
使用 Stable Diffusion 模型生成图像时,反向提示 (Negative Prompting) 也是一个重要方法。反向提示 (Negative Prompting) 提供了对图像生成过程的额外控制,引导模型避开生成的图像中的某些对象、颜色、样式、属性等。
让我们来看一段反向提示(Negative Prompting)的代码示例:
prompt = "emma watson as nature magic celestial, top down pose, long hair, soft pink and white transparent cloth, space, D&D, shiny background, intricate, elegant, highly detailed, digital painting, artstation, concept art, smooth, sharp focus, illustration, artgerm, bouguereau"
payload = {"prompt": prompt, "seed": 0}
compressed_output_query_and_display(payload, "generated image with no negative prompt")
negative_prompt = "windy"
payload = {"prompt": prompt, "negative_prompt": negative_prompt, "seed": 0}
compressed_output_query_and_display(
payload, f"generated image with negative prompt: `{negative_prompt}`"
)
代码运行结果如上面的两幅图对比所示。
左图是没有采用反向提示 (Negative Prompting) 方法生成的图,右图是采用了反向提示 (Negative Prompting) 方法生成的图。相信大家已经看到的这个神奇的差异了。
另外,还有值得一提的地方是:尽管你可以通过指定否定词 “没有”、“except”、“no” 和 “not” 来在原始提示中指定其中的许多概念,但据观察,Stable Diffusion 模型无法很好地理解否定词。因此,在根据用例定制图像时,应使用反向提示参数 (Negative Prompt Parameter)。
prompt = "a portrait of a man without beard"
payload = {"prompt": prompt, "seed": 0}
compressed_output_query_and_display(payload, f"prompt: `{prompt}`, negative prompt: None")
prompt, negative_prompt = "a portrait of a man", "beard"
payload = {"prompt": prompt, "negative_prompt": negative_prompt, "seed": 0}
compressed_output_query_and_display(
payload, f"prompt: `{prompt}`, negative prompt: `{negative_prompt}`"
)举例说明如下:

左图是没有采用反向提示 (Negative Prompting) 方法生成的图,虽然提示词里明确写明了 "a portrait of a man without beard",用了 “without” 这种制定否定词,但是仍然没有达到效果(生成的图像中的男人仍然有胡须)。
右图是采用了反向提示 (Negative Prompting)方法生成的图,达到了预期的效果生成的图像中的男人无胡须)。
清理和释放资源
实验完成后,请通过运行以下代码清理和释放资源,以避免不必要的费用开销:
# Delete the SageMaker endpoint
model_predictor.delete_model()
model_predictor.delete_endpoint()成功释放资源后,在 SageMaker 控制台的 “Endpoints” 项,就应该看不到有任何的端点在部署了,如下图所示:

小结
本篇作为文生图 (Text-to-Image) 领域动手实践系列的上集,主要涉及了两个大方面:
- 首先,通过介绍 Stable Diffusion 模型在 Amazon SageMaker JumpStart 上的快速部署和推理细节,带领大家一起领略了大模型的部署其实没有神秘,而 SageMaker JumpStart 是大家入门学习的好帮手;
- 另外,本文还 Stable Diffusion 模型,逐行代码为大家演示了如何进行 Stable Diffusion 大模型的预训练模型的部署和推理,其中包括:运行环境准备、角色权限配置、支持的主要推理参数、图像的压缩输出、提示工程 (Prompt Engineering)、反向提示 (Negative Prompting) 等内容。
下一篇将继续以 Stable Diffusion 模型为力,介绍预训练模型在客户数据集上的微调 (Fine-tune),以及亚马逊云科技提供的更高阶的面向企业或科研单位生产环境级别的一些完整解决方案,敬请期待。
请持续关注 Build On Cloud 微信公众号,了解更多面向开发者的技术分享和云开发动态!
往期推荐
#开发者生态
#亚马逊的开源文化
#构建模型最佳实践
文章来源:
https://dev.amazoncloud.cn/column/article/6492dcb385edc058b7ab8e22?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN