python spacy
Searching through text is one of the key focus areas of Machine Learning Applications in the field of Natural Language.
在自然语言领域,通过文本搜索是机器学习应用程序的重点关注领域之一。
But what if we have to search for multiple keywords from a large document (100+ pages). Also, what if we have do a contextual search (searching for similar meaning keywords) with in our document! — The conventional ‘CTRL + F’ solution would either take long long hours to accomplish this task (or in case of contextual search, it will not be able to find any meaning text).
但是,如果我们必须从一个大型文档(超过100页)中搜索多个关键字,该怎么办? 另外,如果我们在文档中进行了上下文搜索(搜索具有相似含义的关键字),该怎么办! —传统的“ CTRL + F”解决方案将花费很长时间才能完成此任务(或者在上下文搜索的情况下,它将找不到任何含义文本)。
This article will help the readers understand how we can use Machine Learning to solve this problem using Spacy (a powerful open source NLP library) and Python.
本文将帮助读者理解我们如何使用Spacy(强大的开源NLP库)和Python使用机器学习解决此问题。
数据预处理 (Data Pre-Processing)
The initial step in any building any machine learning-based solution is pre-processing the data. In our case, we will be pre-processing a PDF document using PyPDF2 package in Python and then convert the entire text into a Spacy document object. For readers who have not worked on Spacy — It is an advanced open source library in Python used for various NLP tasks. For users who are interested in learning more about Spacy, please refer this link for reading the documentation and learning more about Spacy — https://spacy.io/
建立任何基于机器学习的解决方案的第一步是对数据进行预处理。 在我们的例子中,我们将使用Python中的PyPDF2包预处理PDF文档,然后将整个文本转换为Spacy文档对象。 对于尚未使用Spacy的读者-这是Python中用于各种NLP任务的高级开源库。 对于谁是有兴趣学习更多有关Spacy用户,请参考阅读文档和学习更多有关Spacy这个链接- https://spacy.io/
We will first load the PDF document, clean the text and then convert it into Spacy document object. The following code can be used to perform this task-
我们将首先加载PDF文档,清理文本,然后将其转换为Spacy文档对象。 以下代码可用于执行此任务-
Data Pre-Processing 数据预处理First we will have to load Spacy’s ‘en_core_web_lg’ model which is a pre-trained English language model available in Spacy. Spacy also provide support for multiple languages (more can be found in the documentation link). Also, Spacy has multiple variations for models (small, medium and large) and for our case we will be working with large model since we have to work with word vectors which is only supported with the large model variant.
首先,我们必须加载Spacy的' en_core_web_lg '模型,该模型是Spacy中提供的经过预先训练的英语语言模型。 Spacy还提供了对多种语言的支持(更多信息可以在文档链接中找到)。 此外,Spacy对于模型(小,中和大)具有多种变体,对于我们的情况,我们将使用大模型,因为我们必须使用仅大模型变体支持的词向量。
The ‘setCustomBoundaries()’ is used as a customer sentence segmentation method as opposed to the default option. The same method can be modified depending upon the document we are dealing.
与默认选项相反,“ setCustomBoundaries() ”用作客户句子细分方法。 根据我们处理的文档,可以修改相同的方法。
Once we have the Spacy’s document object ready, we can move to the next part of handling the input query (keywords) that we need to search for in the document.
准备好Spacy的文档对象后,我们可以移至处理在文档中需要搜索的输入查询(关键字)的下一部分。
处理查询—查找相似的关键字 (Handling Query — Finding Similar Keywords)
Before moving on to the coding part, lets look at the broader approach we are following in order to get more accurate search results from the document we are searching.
在进入编码部分之前,让我们先看一下我们所遵循的更广泛的方法,以便从正在搜索的文档中获得更准确的搜索结果。
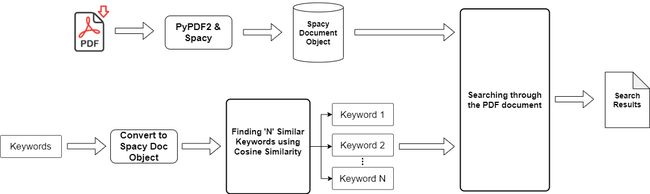
Up until the data preprocessing stage we have already converted our PDF document text to Spacy’s document object. Now we also have to convert our keywords to Spacy’s document object, convert them into their equivalent vector form ((300, ) dimension) and then finding similar keywords using the cosine similarity. At the end we will have an exhaustive list of similar keywords along with the original keywords that we can now search through the our document to generate accurate results.
在数据预处理阶段之前,我们已经将PDF文档文本转换为Spacy的文档对象。 现在,我们还必须将关键字转换为Spacy的文档对象,将其转换为等效的矢量形式((300,)维),然后使用余弦相似度查找相似的关键字。 最后,我们将提供详尽的相似关键字列表以及原始关键字,我们现在可以在文档中搜索这些原始关键字以生成准确的结果。
Refer the below code to perform this task-
请参考以下代码以执行此任务-
Generate Similar Keywords 产生类似的关键字Now that we have found contextually similar words to our original keywords, lets work on the final searching part.
现在,我们已经找到了与原始关键字在上下文上相似的词,让我们在最后的搜索部分开始工作。
通过文本搜索关键字 (Searching Keywords through Text)
For searching, we would be using the PhraseMatcher class of Spacy’s Matcher class. At this point it is important to remember that Spacy’s document object is not as same as a simple python string and hence we cannot directly use if then else to find the results.
为了进行搜索,我们将使用Spacy的Matcher类的PhraseMatcher类。 在这一点上,重要的是要记住,Spacy的文档对象与简单的python字符串不同,因此我们不能直接使用if否则查找结果。
Refer to the below code to perform this task-
请参考以下代码以执行此任务-
Searching through text 搜寻文字The above code will search for every keyword we have through the entire text and will return us the entire sentence wherever it has found a match.
上面的代码将在整个文本中搜索我们拥有的每个关键字,并在找到匹配项的地方返回整个句子。
The above code will generate the following output-
上面的代码将生成以下输出-

You can increase or decrease the number of similar keywords that you want to find for any original keywords. Also, once you get the results in a dataframe, you can simply add some more logics for ranking the results (give more weightage to exact keyword match and so on).
您可以增加或减少想要为任何原始关键字找到的相似关键字的数量。 同样,一旦在数据框中获得结果,就可以简单地添加一些用于对结果进行排名的逻辑(将更多的权重赋予完全匹配的关键字,依此类推)。
Note: Increasing number of Similar Keywords to large number may increase the computational cost of the overall program and hence should be chosen wisely.
注意:将相似关键字的数量增加到大量可能会增加整个程序的计算成本,因此应明智地选择。
So this is how you can create your own ML based Python program for performing search through any text.
因此,这就是您可以创建自己的基于ML的Python程序以通过任何文本执行搜索的方式。
In case of any other input source (Photographs, Web pages etc.) you just need to customize the data preprocessing part (OCR, Web Scraping etc.) and the rest of the logic should perform just fine.
如果有其他任何输入源(照片,网页等),则只需要自定义数据预处理部分(OCR,Web Scraping等),其余逻辑就可以正常工作。
翻译自: https://levelup.gitconnected.com/natural-language-processing-document-search-using-spacy-and-python-820acdf604af
python spacy