Golang面试题(1-25)
目录
一、var、new和make的区别?
二、进程、线程和协程的区别?
三、channel底层是什么?(待补充)
四、defer执行顺序?
五、defer、return和返回值的执行逻辑?
六、如何用两个协程交替打印出123456?
七、数组和切片的区别?
八、channel在项目中的使用场景?
九、使用channel的注意事项?
十、对channel的哪些操作会产生panic?
十一、Golang相比其他语言有哪些优势?
十二、Golang的数据类型?
十三、Golang程序中的包是什么?
十四、Golang支持什么形式的类型转换?
十五、什么是Goroutine,如何停止它?
十六、两个接口之间可以存在什么关系?
十七、同步锁有什么特点?作用是什么?
十八、channel有什么特点,需要注意什么?
十九、channel缓冲有什么特点?
二十、cap函数可以作用于哪些内容?
二十一、Printf(),Sprintf(),FprintF()都是格式化输出,有什么不同?
二十二、值传递和引用传递的区别?
二十三、切片的扩容是如何实现的?
二十四、defer的常用场景?
二十五、切片的底层实现?
一、var、new和make的区别?
变量初始化一般包括两步:变量声明和内存分配。var关键字是用来声明变量的,new和make函数是用来分配内存的。
(一)使用var初始化有两种情况
- 值类型:var声明值变量的同时会分配内存,然后赋予该类型零值。
package main
import "fmt"
func main() {
var i int
fmt.Println(i)
}
// 输出
0- 引用类型或指针类型:var只声明变量不分配内存,默认为nil。此时如果直接使用会报错。
package main
import "fmt"
func main() {
var i *int
*i = 0
fmt.Println(*i)
}
// 输出
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x2 addr=0x0 pc=0x104edf930]
goroutine 1 [running]:
main.main()
/Users/Jason/go/src/test.go:7 +0x20
exit status 2此时想要使用需要分配内存
package main
import "fmt"
func main() {
var i *int
i = new(int)
*i = 1
fmt.Println(*i)
}
// 输出
1(二)new和make都是Golang中分配内存的内建函数,在堆上分配内存,有以下区别:
- new用于任意类型的内存分配,初始化其零值,返回该类型指针;make只用于slice(必须分配大小)、map和channel,返回类型(slice、map和chan)本身。
二、进程、线程和协程的区别?
- 进程是一个具有特定功能的程序运行在一个数据集上的运行活动(动态过程),是操作系统进行资源分配和独立运行的最小单位。
- 线程是操作系统调度(CPU调度)和执行的最小单位,多个线程组成一个进程,每个线程共享父进程的资源。
- 协程是用户态的一种轻量级线程,其调度完全由用户(程序)控制。
三、channel底层是什么?(待补充)
channel是go中的一种数据类型,多个协程可以通过channel进行交互。
channel分为无缓冲区和有缓冲区两种。
channel底层是基于环形队列实现的,
四、defer执行顺序?
defer底层为压栈,执行顺序为“先进后出”。
五、defer、return和返回值的执行逻辑?
return的操作并非原子性的,分为赋值和返回两步。
retrun先将结果写入返回值,defer执行defer后的函数,函数携带返回值退出。
六、如何用两个协程交替打印出123456?
方法一:使用一个无缓存channel
package main
import (
"fmt"
"sync"
)
func main() {
ch := make(chan int)
wg := sync.WaitGroup{}
// 这里设置计数器为1的原因是在i=10时,两个协程的for循环都结束
// 此时已经打印完成,因此只需要执行一次wg.Done()
wg.Add(1)
go func() {
defer wg.Done()
for i := 1; i < 11; i++ {
ch <- 1
if i%2 == 0 {
fmt.Println("偶数:", i)
}
}
}()
go func() {
defer wg.Done()
for i := 1; i < 11; i++ {
<-ch
if i%2 != 0 {
fmt.Println("奇数:", i)
}
}
}()
wg.Wait()
}由于变量ch是一个无缓冲的channel,所以只有读写同时就绪时才不会阻塞。所以两个goroutine会同时进入各自的if语句(此时i是相同的),但是此时只能有一个 if 是成立的,不管哪个go协程快,都会由于读channel或写channel导致阻塞,因此程序会交替打印1-10且有顺序。
方法二:使用两个channel,其中一个有缓存
package main
import (
"fmt"
"sync"
)
func main() {
// 设置缓存的原因是当i=10时,打印奇数的协程1会先退出,打印偶数的协程2打印出10
// 然后会往ch1中写数据,如果ch1不设置缓存,会发生堵塞,协程2会一直无法退出
ch1 := make(chan struct{}, 1)
ch0 := make(chan struct{})
wg := sync.WaitGroup{}
wg.Add(2)
go func() {
defer wg.Done()
for i := 1; i < 11; i++ { // 10
ch1 <- struct{}{}
if i%2 != 0 {
fmt.Println("第一个协程,奇数:", i)
}
ch0 <- struct{}{}
}
}()
go func() {
defer wg.Done()
for i := 1; i < 11; i++ { // 10
<-ch0
if i%2 == 0 {
fmt.Println("第二个协程,偶数:", i)
}
<-ch1
}
}()
wg.Wait()
}
七、数组和切片的区别?
- 数组是定长的,在定义时就确认了长度;切片是变长的,其底层数组实现的,通过append()方法可以扩容。
- 数组是值类型;切片是引用类型。
- 数组计算长度需要遍历整个数组,时间复杂度为O(n);切片本身具有len字段,时间复杂度为O(1)。
八、channel在项目中的使用场景?
(一)信号通知(无缓冲的通道)
当信息收集完成,通知下游开始计算数据:
package main
import (
"log"
"time"
)
func collectMsg(isOver chan struct{}) {
log.Println("开始采集")
time.Sleep(3000 * time.Millisecond)
log.Println("完成采集")
isOver <- struct{}{}
}
func calculateMsg() {
log.Println("开始进行数据分析")
}
func main() {
isOver := make(chan struct{})
go func() {
collectMsg(isOver)
}()
<-isOver
calculateMsg()
}
输出结果
2022/04/13 15:19:17 开始采集
2022/04/13 15:19:20 完成采集
2022/04/13 15:19:20 开始进行数据分析如果只是单纯的使用通知操作,那么最好将空结构体放入通道。因为空结构体在go中是不占用内存空间的。
res := struct{}{} fmt.Println(unsafe.Sizeof(res)) // 结果为0
(二)执行任务超时控制(通过select机制)
使用select和time.After,看操作和定时器哪个先返回,处理先完成的,就达到了超时控制的效果。
package main
import (
"log"
"time"
)
func doWork() <-chan struct{} {
ch := make(chan struct{})
go func() {
// 处理耗时任务
log.Println("开始处理任务")
time.Sleep(2 * time.Second)
ch <- struct{}{}
}()
return ch
}
func main() {
select {
case <-doWork():
log.Println("任务在规定时间内结束")
case <-time.After(1 * time.Second):
log.Println("任务处理超时")
}
}输出结果
2022/04/13 17:24:17 开始处理任务
2022/04/13 17:24:18 任务处理超时(三)控制并发数(通过设置缓冲区大小)
经常会写一些脚本,在凌晨的时候对内或者对外拉取数据,但是如果不对并发请求加以控制,往往会导致 groutine 泛滥,进而占满CPU资源。往往不能控制的东西意味着不好的事情将要发生。对于我们来说,可以通过channel来控制并发数。
package main
import (
"fmt"
"time"
)
func job(index int) {
// 耗时任务
time.Sleep(2 * time.Second)
fmt.Printf("任务:%d 已完成\n", index)
}
func main() {
limit := make(chan struct{}, 10)
jobCount := 100
for i := 0; i < jobCount; i++ {
go func(index int) {
limit <- struct{}{}
job(index)
<-limit
}(i)
}
time.Sleep(30 * time.Second)
}
以上程序最多同时开启10个协程。
- 消息传递、消息过滤
- 信号广播
- 事件订阅与广播
- 请求、响应转发
- 任务分发
九、使用channel的注意事项?
channel可以声明为只读或者只写,默认是读写都可用。
使用channel完成后记得注意关闭,不关闭阻塞会导致deadlock。
当需要不断从channel读取数据时,最好使用for-range读取channel,这样既安全又便利,当channel关闭时,for循环会自动退出,无需主动监测channel是否关闭,可以防止读取已经关闭的channel,造成读到数据为通道所存储的数据类型的零值。
十、对channel的哪些操作会产生panic?
重复关闭通道、关闭一个nil的通道、往一个关闭的通道发送数据。
1. 重复关闭channel
package main
func main() {
ch := make(chan struct{})
close(ch)
close(ch)
}输出结果
panic: close of closed channel
goroutine 1 [running]:
main.main()
/home/jason/go/src/test.go:6 +0x39
exit status 22. 关闭一个nil值的channel
package main
func main() {
var ch chan struct{}
close(ch)
}
输出结果
panic: close of nil channel
goroutine 1 [running]:
main.main()
/home/jason/go/src/test.go:5 +0x1b
exit status 23. 往一个已经关闭的channel写数据
package main
func main() {
ch := make(chan struct{})
close(ch)
ch <- struct{}{}
}输出结果
panic: send on closed channel
goroutine 1 [running]:
main.main()
/home/jason/go/src/test.go:6 +0x3e
exit status 2十一、Golang相比其他语言有哪些优势?
go从语言层面实现并发编程。很多语言支持多进程、多线程,但实现和控制比较麻烦。go语言天生支持并发和协程,可以轻松启动成千上万个协程。
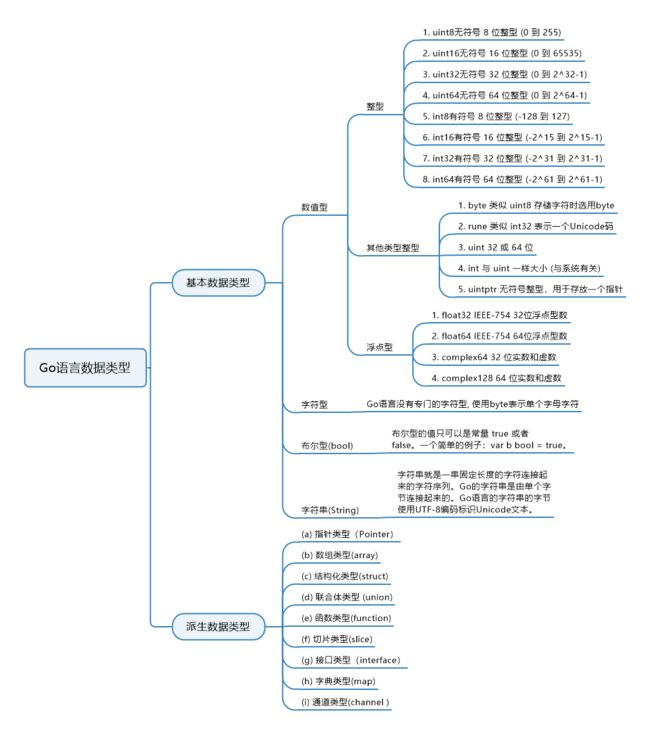
十二、Golang的数据类型?
Go语言的数据类型可以分为:基本数据类型和派生数据类型。
基本数据类型包括数值型(整形、浮点型、其他类型)、字符串、字符型、布尔型。
派生数据类型包括结构体、数组、指针、映射、切片、通道、函数、接口、联合体。
十三、Golang程序中的包是什么?
包的本质是创建不同的文件夹,来存放程序文件。
十四、Golang支持什么形式的类型转换?
Go支持显式类型转换以满足其严格的类型要求。
十五、什么是Goroutine,如何停止它?
Goroutine是用户态的一种更轻量级的线程,其调度由用户(程序)控制而不是由内核控制。
十六、两个接口之间可以存在什么关系?
如果A和B有想同的方法列表,那么接口A和B就是等价的,可以相互赋值;如果接口A的方法是接口B的子集,那么接口B可以赋值给接口A,因为B实现了A接口的所有方法。
十七、同步锁有什么特点?作用是什么?
十八、channel有什么特点,需要注意什么?
从类型、模式和状态总结channel的特点。
类型:channel分为有缓冲和无缓冲两种类型。
模式:只读模式、只写模式和读写模式。
ch1 := make(chan<- int) // 只读chan
ch2 := make(<-chan int) // 只写chan
ch3 := make(chan int) // 读写chan状态:未初始化、正常和关闭
| 未初始化 | 正常 | 关闭 | |
| 关闭 | panic | 正常关闭 | panic |
| 发送 | 永远堵塞导致deadlock | 堵塞或成功 | panic |
| 接收 | 永远堵塞导致deadlock | 堵塞或成功 | 缓冲区为空接收类型零值,否则正常 |
注意点:
- 重复关闭channel会panic。
- 如果多个goroutine监听同一个channel,那么channel中的数据可能被随机的一个goroutine取走。
- 如果多个goroutine监听同一个channel,那么channel被关闭,所有goroutine都能收到退出信号。
十九、channel缓冲有什么特点?
无缓冲的Channel是同步的,有缓冲的Channel是非同步的。
二十、cap函数可以作用于哪些内容?
数组、切片和通道。
二十一、Printf(),Sprintf(),FprintF()都是格式化输出,有什么不同?
- Printf格式化的字符串并输出到标准输出,一般为屏幕。
- Sprintf格式化的字符串并返回给变量。
- Fprintf格式化字符串并输出到文件中。
二十二、值传递和引用传递的区别?
- 值传递是将变量的值拷贝一份传入相应的函数,在函数中对其进行修改不会影响到函数外。
- 引用传递是将变量的地址传入到相应的函数,在函数中的修改会影响到函数外。
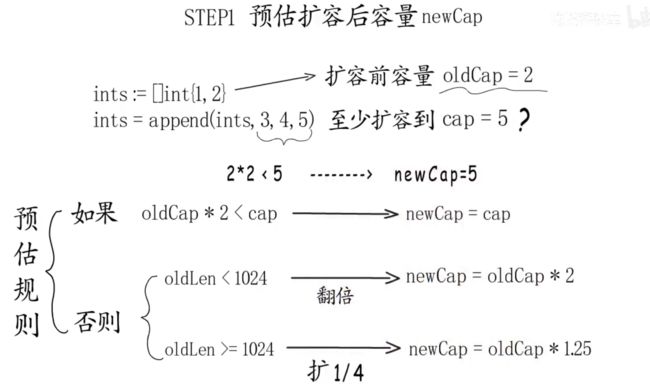
二十三、切片的扩容是如何实现的?
切片有三个域:数组指针、大小和容量。
- 首先判断,如果新申请容量大于 2 倍的旧容量,最终容量就是新申请的容量
- 否则判断,如果旧切片的长度小于 1024,则最终容量就是旧容量的两倍
- 否则判断,如果旧切片长度大于等于 1024,则最终容量从旧容量开始循环增加原来的1/4, 直到最终容量大于等于新申请的容量
二十四、defer的常用场景?
defer常用在成对的操作上,如打开、关闭、连接、断开连接、加锁、解锁。
二十五、切片的底层实现?
切片的底层是通过数组实现的,基于数组实现使得底层的内存是连续分配的。
切片对象非常小,是因为它是只有3个字段的数据结构: 指向底层数组的指针、切片的长度、切片的容量。