Android-三方框架的源码
ARouter
Arouter的整体思路是moduelA通过中间人ARouter把路由信息的存到仓库WareHouse;moduleB发起路由时,再通过中间人ARouter从仓库WareHouse取出路由信息,这要就实现了没有依赖的两者之间的跳转与通信。其中涉及Activity的跳转、服务provider的获取、拦截器的处理等。
路由元信息是怎么收集的?
跳转Activity最终必定是走到了 startActivity(intent)方法,而intent是一般需要目标Activity的Class,构建PostCard,继承自路由元信息 RouteMeta,参数group是path的第一级,group的作用是作为路由的默认分组。Warehouse意为仓库,用于存放被 @Route、@Interceptor注释的 路由相关的信息,也就是我们关注的destination等信息。由于进行activity跳转需要目标Activity的class对象来构建intent,所以必须有一个中间人,把路径"/test/activity"翻译成Activity的class对象,然后moduleB才能实现跳转。 Warehouse,它存着所有路由信息。
Warehouse存了哪些信息呢?
class Warehouse {
//所有IRouteGroup实现类的class对象,是在ARouter初始化中赋值,key是path第一级
//(IRouteGroup实现类是编译时生成,代表一个组,即path第一级相同的所有路由,包括Activity和Provider服务)
static Map<String, Class<? extends IRouteGroup>> groupsIndex = new HashMap<>();
//所有路由元信息,是在completion中赋值,key是path
//首次进行某个路由时就会加载整个group的路由,即IRouteGroup实现类中所有路由信息。包括Activity和Provider服务
static Map<String, RouteMeta> routes = new HashMap<>();
//所有服务provider实例,在completion中赋值,key是IProvider实现类的class
static Map<Class, IProvider> providers = new HashMap<>();
//所有provider服务的元信息(实现类的class对象),是在ARouter初始化中赋值,key是IProvider实现类的全类名。
//主要用于使用IProvider实现类的class发起的获取服务的路由,例如ARouter.getInstance().navigation(HelloService.class)
static Map<String, RouteMeta> providersIndex = new HashMap<>();
//所有拦截器实现类的class对象,是在ARouter初始化时收集到,key是优先级
static Map<Integer, Class<? extends IInterceptor>> interceptorsIndex = new UniqueKeyTreeMap<>("...");
//所有拦截器实例,是在ARouter初始化完成后立即创建
static List<IInterceptor> interceptors = new ArrayList<>();
...
}
groupsIndex,所有路由组元信息。是所有IRouteGroup实现类的class对象,是在ARouter初始化中赋值,key是path第一级。IRouteGroup实现类是编译时生成,代表一个组,即path第一级相同的所有路由,包括Activity和Provider服务)。
routes,所有路由元信息。是在LogisticsCenter.completion中赋值,key是path。首次进行某个路由时就会加载整个group的路由,即IRouteGroup实现类中所有路由信息。包括Activity和Provider服务
providers,所有服务provider实例。在LogisticsCenter.completion中赋值,key是IProvider实现类的class
providersIndex,所有provider服务元信息(实现类的class对象)。是在ARouter初始化中赋值,key是IProvider实现类的全类名。用于使用IProvider实现类class发起的获取服务的路由,例如ARouter.getInstance().navigation(HelloService.class)
interceptorsIndex,所有拦截器实现类class对象。是在ARouter初始化时收集到,key是优先级
interceptors,所有拦截器实例。是在ARouter初始化完成后立即创建
其中groupsIndex、providersIndex、interceptorsIndex是ARouter初始化时就准备好的基础信息,为业务中随时发起路由操作(Activity跳转、服务获取、拦截器处理)做好准备。
ARouter 框架的设计是它默认会将注解中注册path路径中第一个路由层级 (例如 "/trade/homePage"中的trade)作为该路由信息所的Group, 相同Group路径的路由信息会合并到最终生成的同一个类 的注册函数中进行同步注册。在大型项目中,对于复杂业务线同一个Group下可能包含上百个注册信息,注册逻辑执行过程耗时较长。
ARouter在编译时生成的帮助类PluginLaunch、RegisterTransform、ScanUtil这三个类,是用于对所有使用@Route、@Interceptor注解的类信息的分组和收集,编译运行时对路由信息仓库Warehouse的填充和使用。这里涉及到的是Annotation Process Tool(APT)技术,即注解处理工具。 除了运行时查找dex,还可以在编译时扫描帮助类信息,并且直接在物流中心LogisticsCenter loadRouterMap()方法中直接插入使用帮助类的代码,这里涉及 Android Gradle Plugin(AGP)技术,即Android的gradle插件相关技术。Android官方的AGP中提供了一个API——Transform,在class文件转为dex文件之前,这个节点可以拿到参与构建的所有class文件,在Transform的中拿到所有class文件后,通过ASM字节码操作框架,使用ASM对源码生产class文件和三方jar中的class文件进行扫描,找到所有帮助类,也就是PluginLaunch、RegisterTransform、ScanUtil这三个类,PluginLaunch,就是自定义的Gradle插件,然后注册了自定义的RegisterTransform。RegisterTransform中的registerList保存着的是各个帮助类的接口。RegisterTransform是自定义的Transform,transform方法会在gradle的执行阶段执行——源码生成class文件之后、class被打进dex文件之前。具体逻辑就是 扫描全部jar(三方库中的class文件)、扫描全部目录(源码生成的class文件),拿到所有目标帮助类,在 LogisticsCenter#loadRouterMap()中插入代码。
Arouter怎么找到这个路由的?
具体的扫描过程是使用ScanUtil类,插入代码是RegisterCodeGenerator类。首先是拿到jar中LogisticsCenter.class文件的输入流,接着使用ASM自定义MyClassVisitor在visitMethod()方法中找到要插入代码的方法-loadRouterMap()。然后在自定义RouteMethodVisitor的visitInsn()方法中,确保在return之前插入代码。遍历所有帮助类,把帮助类路径中的"/“换成”." 。 LogisticsCenter 在loadRouterMap方法主动注册插件 会在此处插入代码。调用此方法就注册了全部的 Routers、Interceptors、Provider。
如何使用编译时生成的帮助类呢?
https://juejin.cn/post/7201879428086513720#heading-0
Gradle开发,APT采集页面路由信息:https://blog.csdn.net/weixin_46039528/article/details/132930598
https://blog.csdn.net/weixin_46039528/article/details/133105627
Gradle开发(三),字节码插桩,编译期间自动注册收集页面路由信息的映射表类并汇总:
https://blog.csdn.net/weixin_46039528/article/details/133366126
Android编译优化系列-kapt篇:https://juejin.cn/post/7070849501166059551
APT(Annotation Processing Tool),即 注解处理器,是javac中提供的编译时扫描和处理注解的工具,它对源代码文件进行检测找出其中的注解,然后使用注解进行额外的处理。
注解就像是一个标签,有很多类型,可以贴在某些元素上面进行标记,并且标签上可以写一些信息。APT就是用来处理标签的工具,在编译开始后,可以拿到自己所关心的类型的所有标签,然后根据标签信息和被标记的元素信息,做一些事情。做那些事呢,这就看你如何写APT了,你让他干啥他就干啥,通常都是会生成一些帮助类——帮助完成你的目的的类。 后面无论对这种标签的使用是增加、减少了,每次编译都会重新走这一过程,而上一次的处理结果会被清空。
宏观上理解,APT就是javac提供给开发者在编译时处理注解的一种技术;微观上,具体到实例中就是指 继承自javax.annotation.processing.AbstractProcessor 的实现类,即一个处理特定注解的处理器。(下文提到的APT都是宏观上理解,具体的处理器简称为Processor)
使用了APT,只要使用注解进行标记即可,无论使用者怎么标记,每次编译时都由APT统一处理,不会出错、也不担心有遗漏。
APT还有两个特点:
1、获取注解及生成代码都是在代码编译时候完成的,相比反射在运行时处理注解大大提高了程序性能。
2、注意APT并不能对源文件进行修改,只能获取注解信息和被注解对象的信息,然后做一些自定义的处理,例如生成java类。
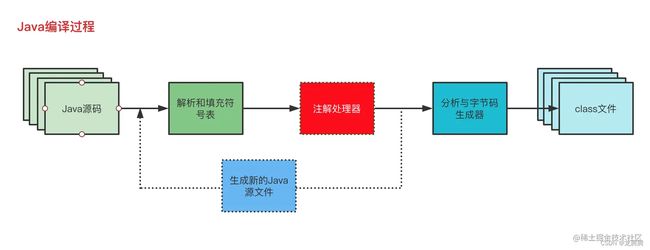
在Java源码到class文件之间,需要经过注解处理器的处理,注解处理器生成的代码也同样会经过这一过程,最终一起生成class文件。在Android中,class文件还会被打进Dex文件中,最后生成APK文件。
在编译流程进入Processor前,APT会对整个Java源文件进行扫描,这样就会获取到 所有添加了的注解和对应被注解的类。 注解和被注解的类,一起被视为一个元素,即TypeElement,就是process()方法参数annotations的数据类型。 通过TypeElement,我们可以获取注解的所有信息、被注解类的所有信息,这样就可以根据这些信息来生成 我们需要的帮助类了。
最重要的就是 process()方法的实现:拿到所有关注的注解元素后,就是每个Processor的独自的逻辑——解析注解并生成需要的java文件。
Java文件要如何生成呢?这里就要介绍 javepoet 这个库了,通常APT框架中生成Java类都是使用javepoet。这里也不展开介绍,下面结合我添加的注释即可理解。
Gradle:一个自动化构建框架;在Android开发中,用来编译打包输出apk,还可以用来添加三方依赖。
Apk打包流程包括很多环节:源码文件经过JavaCompiler转为class文件、class经过dex操作变为dex文件、dex和资源等打包成apk、签名 等等一系列步骤,这就需要Google使用Gradle把这些操作都串联起来。
https://juejin.cn/post/7129157665732689934
LeakCanary
为弱引用指定一个引用队列,当弱引用指向的对象被回收时,此弱引用就会被添加到这个队列中,我们可以通过判断这个队列中有没有这个弱引用,来判断该弱引用指向的对象是否被回收了。
精简流程如下所示:
1、LeakCanary.install(application);此时使用application进行
2、registerActivityLifecycleCallbacks,从而来监听Activity的何时被destroy。
3、在onActivityDestroyed(Activity activity)的回调中,去检测Activity是否被回收,检测方式如以下步骤:
使用一个弱引用WeakReference指向这个activity,并且给这个弱引用指定一个引用队列queue,同时创建一个key来标识该activity。
然后将检测的方法ensureGone()投递到空闲消息队列。
当空闲消息执行的时候,去检测queue里面是否存在刚刚的弱引用,如果存在,则说明此activity已经被回收,就移除对应的key,没有内存泄漏发生。
如果queue里不存在刚刚的弱引用,则手动进行一次gc。
gc之后再次检测queue里面是否存在刚刚的弱引用,如果不存在,则说明此activity还没有被回收,此时已经发生了内存泄漏,直接dump堆栈信息并打印日志,否则没有发生内存泄漏,流程结束。