Elasticsearch基本查询
目录
一、简介
ES与关系型数据库对比
文本分析
倒排索引
二、基本查询
空查询
相关性
查询与过滤
1. 查询与"first blog"字段最佳匹配的文档
2. 搜索博客等级(level)大于等于2, 同时发布日期(post_date)是2018-11-11的博客
结构化搜索
1. 精确值查找(term)
2. 多个精确值查找(terms)
3. range(范围过滤)
4. 组合查询(bool)
5. 处理null值(exists)
全文搜索
1. match
2. bool(组合查询)
3. match_phrase(短语匹配)
分页(深度分页)from+size
排序
游标查询(scroll)
模糊查询
三、聚合分组
执行顺序及聚合写法
指标聚合(Metrics)
1. max、min、sum、avg
2. Value count
3. cardinality
4. stats
5.Extended stats
桶聚合(Buckets)
1. Terms Aggregation
2. Filter Aggregation
3. Filters Aggregation
4. Top_hits Aggregation
5. Date_histogram Aggregation
一、简介
Elasticsearch(ES):一款基于Apache Lucene(TM)的开源的全文检索和分析引擎。通过简单的RESTful API来隐藏其复杂性、同时也做了分布式相关的工作。
Lucene:使用Java实现的一套搜索引擎库。
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
ES与关系型数据库对比
Elasticsearch集群可以包含多个索引(数据库),每一个索引可以包含多个类型(表),每一个类型包含多个文档(行),然后每个文档包含多个字段(列)
| 关系型数据库 |
数据库 |
表 |
行 |
列 |
| ElasticSearch |
索引(index) |
类型(type) |
文档 |
字段 |
相关概念:
- 集群(cluster):一个集群就是由一个或多个节点组织在一起,它们共同持有你整个的数据,并一起提供索引和搜索功能。
- 节点(node):一个节点就是集群中的一个服务器,作为集群的一部分,参与集群的索引和搜索功能。
- 索引(index): 一个索引就是一个具有相似特征的文档集合,相当于一个数据集。
- 类型(type):在一个索引中,你可以定义一种或多种类型,相当于对一个索引中数据的逻辑划分(ES官方文档明确说明不推荐使用type,即建议一个索引只有一个type。ES7.0已经废弃了type)。
- 文档(document): 一个文档是一个可被索引的基础信息单元,就是索引里面的一条数据,使用JSON格式来表示。
- 域(field): 文档中的一个数据字段。一个文档由多个域组成。
- 分片(shards):分片是索引的一部分,一个索引由多个分片组成。每个分片可以分布在不同的节点上,ES会根据文档id(也可以指定其他字段)做hash,使用得到的hash值将文档路由到指定分片上。分片是ES做Data Rebalance的最小单元。
- 副本(replicas):创建索引时可以为索引指定0个或者多个副本。副本是分片级别的,即索引的分片由1个主分片(primary shard)和0个或者多个副本分片(replica shard)组成。primary shard可以接受读取和写入请求,replica shard只能接受读取请求。所以副本只能提高数据的可用性和并发读取能力。当primary shard所在服务器的节点挂掉以后,ES会通过leader选举机制将replica shard为primary shard。
文本分析
将文本转换成一系列单词(Term or Token)的过程,用于创建和查询倒排索引
分词器:是ES中专门处理分词的组件,由一下三部分组成
- Character Filters:针对原始文本进行处理,比如去除html标签
- Tokenizer:将原始文本按照一定规则切分为单词
- Token Filters:针对Tokenizer处理的单词进行再加工,比如转小写、删除或增新等处理
内置分词器:
- Standard Analyzer:默认分词器,按词切分,小写处理,删除大多标点符号
- Simple Analyzer:按照非字母切分、小写处理
- Whitespace Analyzer:按照空白字符分割
- Keyword Analyzer:不分词
分词查看
POST /_analyze
{
"analyzer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}结果
{
"tokens": [{
"token": "the",
"start_offset": 0,
"end_offset": 3,
"type": "",
"position": 0
},
{
"token": "2",
"start_offset": 4,
"end_offset": 5,
"type": "",
"position": 1
},
...
]
} 详情点击跳转官方文档查看
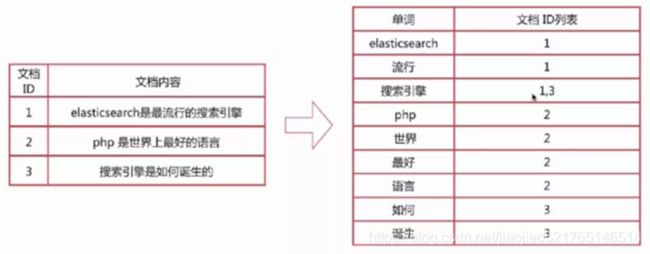
倒排索引
ES把文档中的数据进行分析后,将词和文档之间建立映射关系。
组成:倒排索引由文档中不重复词的列表+每个词被包含的文档ID列表
查询过程:
- 搜索词“搜索引擎”,获得对应的文档ID列表,1,3
- 通过正排索引查询1和3的完整内容
- 返回最终结果
二、基本查询
空查询
GET /_search
{}
GET /_search
{
"query": {
"match_all": {}
}
}字段详解

相关性
根据ES的相似度算法(TF/IDF)得出的结果,具体值由_score字段表示,根据以下维度计算得出
- 检索词频率: 检索词在该字段出现的频率,频率越高,权重越大。字段中出现过 5 次要比只出现过 1 次的相关性高。
- 反向文档频率:检索词在使用中出现的频率,频率越高,权重越低。检索词出现在多数文档中会比出现在少数文档中的权重更低。
- 字段长度准则:字段长度越长,权重越低
// 请求后增加explain=true即可
GET /_search
{
"explain":true,
"query" : { "match" : { "name" : "John Smith" }}
}查询与过滤
| Query |
Filter |
|
| 争对问题 |
该文档匹不匹配这个查询,它的相关度高么❓ |
这篇文档是否与该查询匹配❓ |
| 相关度处理 |
先查询符合搜索条件的文档数,然后计算每个文档对于搜索条件的相关度分数,再根据评分倒序排序 |
只根据搜索条件过滤出符合的文档, 不进行评分, 忽略TF/IDF信息 |
| 性能 |
性能较差, 有排序 , 并且没有缓存功能(有倒排索引来弥补) |
性能更好, 无排序; 会缓存比较常用的filter的数据 |
| 栗子 |
❗ 查询与“first blog”字段最佳匹配的文档 ❗ |
❗ 搜索博客等级(level)大于等于2, 同时发布日期(post_date)是2018-11-11的博客 ❗ |
1. 查询与"first blog"字段最佳匹配的文档
// query
GET /_search
{
"query": {
"match": {
"desc": "four blog"
}
}
}
// filter
GET /_search
{
"query": {
"bool": {
"filter": {
"match": {
"desc": "four blog"
}
}
}
}
}2. 搜索博客等级(level)大于等于2, 同时发布日期(post_date)是2018-11-11的博客
// query
GET /_search
{
"query": {
"bool": {
"must": [
{ "match": { "post_date": "2018-11-11" } },
{ "range": { "level": { "gte": 2 } } }
]
}
}
}
// filter
GET /_search
{
"query": {
"bool": {
"must": {
"match": { "post_date": "2018-11-11" }
},
"filter": {
"range": { "level": { "gte": 2 } }
}
}
}
}结构化搜索
插入测试数据
POST /my_store/_bulk
{ "index": { "_id": 1 }}
{ "price" : 10, "productID" : "XHDK-A-1293-#fJ3" }
{ "index": { "_id": 2 }}
{ "price" : 20, "productID" : "KDKE-B-9947-#kL5" }
{ "index": { "_id": 3 }}
{ "price" : 30, "productID" : "JODL-X-1937-#pV7" }
{ "index": { "_id": 4 }}
{ "price" : 30, "productID" : "QQPX-R-3956-#aD8" }查看索引详情
GET /my_store1. 精确值查找(term)
查询价格20的所有产品
SQL:SELECT * FROM products WHERE price = 20
GET /_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"price" : 20
}
}
}
}
}
// constant_score关键字将trem查询转化为filter
GET /_search
{
"query":{
"bool": {
"filter": {
"term": {
"price": 20
}
}
}
}
}查询productID为XHDK-A-1293-#fJ3的文档
SQL:SELECT * FROM products WHERE productID = "XHDK-A-1293-#fJ3"
GET /_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"productID" : "XHDK-A-1293-#fJ3"
}
}
}
}
}
// 查看分词结果
GET /my_store/_analyze
{
"field": "productID",
"text": "XHDK-A-1293-#fJ3"
}总结:term会拿"XHDK-A-1293-#fJ3",去倒排索引中找,但倒排索引表里只有"xhdk","a","1293","fj3",因此查不到
解决办法1
GET /_search
{
"query" : {
"match_phrase" : {
"productID" : "XHDK-A-1293-#fJ3"
}
}
}解决办法2
// 1.删除索引
DELETE /my_store
//2.指定productID字段使用keyword规则
PUT /my_store
{
"mappings": {
"properties": {
"price": {
"type": "long"
},
"productID": {
"type": "text",
"analyzer": "keyword"
}
}
}
}2. 多个精确值查找(terms)
查找price为20 && 30 的文档
GET /my_store/_search
{
"query" : {
"constant_score" : {
"filter" : {
"terms" : {
"price" : [20, 30]
}
}
}
}
}3. range(范围过滤)
gt:> lt:< gte:>= lte:<=
查找price大于20且小于40的产品
SQL:SELECT * FROM products WHERE price BETWEEN 20 AND 40
GET /my_store/_search
{
"query" : {
"constant_score" : {
"filter" : {
"range" : {
"price" : {
"gte" : 20,
"lt" : 40
}
}
}
}
}
}日期范围查询 now data||+1M
GET /website/_search
{
"query" : {
"constant_score" : {
"filter" : {
"range" : {
"post_date": {
"gte" : "2020-01-01",
"lt": "2020-09-09||+1h"
}
}
}
}
}
}4. 组合查询(bool)
SQL:SELECT * FROM products WHERE (price = 20 OR productID = "XHDK-A-1293-#fJ3") AND (price != 30)
GET /my_store/_search
{
"query" : {
"constant_score" : {
"filter" : {
"bool" : {
"should" : [
{ "term" : {"price" : 20}},
{ "term" : {"productID" : "XHDK-A-1293-#fJ3"}}
],
"must_not" : {
"term" : {"price" : 30}
}
}
}
}
}
}SQL:SELECT * FROM products WHERE productID = "KDKE-B-9947-#kL5" OR (productID = "JODL-X-1937-#pV7" AND price = 30)
GET /my_store/_search
{
"query" : {
"constant_score" : {
"filter" : {
"bool" : {
"should" : [
{ "term" : {"productID" : "KDKE-B-9947-#kL5"}},
{ "bool" : {
"must" : [
{ "term" : {"productID" : "JODL-X-1937-#pV7"}},
{ "term" : {"price" : 30}}
]
}}
]
}
}
}
}
}5. 处理null值(exists)
插入测试数据
POST /posts/_bulk
{ "index": { "_id": "1" }}
{ "tags" : ["search"] }
{ "index": { "_id": "2" }}
{ "tags" : ["search", "open_source"] }
{ "index": { "_id": "3" }}
{ "other_field" : "some data" }
{ "index": { "_id": "4" }}
{ "tags" : null }
{ "index": { "_id": "5" }}
{ "tags" : ["search", null] }存在查询
SQL:SELECT tags FROM posts WHERE tags IS NOT NULL
GET /posts/_search
{
"query" : {
"constant_score" : {
"filter" : {
"exists" : { "field" : "tags" }
}
}
}
}缺失查询
SQL:SELECT tags FROM posts WHERE tags IS NULL
GET /posts/_search
{
"query" : {
"constant_score" : {
"filter" : {
"bool": {
"must_not":{"exists" : { "field" : "tags" }}
}
}
}
}
}全文搜索
插入测试数据
POST /my_index/my_type/_bulk
{ "index": { "_id": 1 }}
{ "title": "The quick brown fox" }
{ "index": { "_id": 2 }}
{ "title": "The quick brown fox jumps over the lazy dog" }
{ "index": { "_id": 3 }}
{ "title": "The quick brown fox jumps over the quick dog" }
{ "index": { "_id": 4 }}
{ "title": "Brown fox brown dog" }1. match
单个词查询
执行过程:
- 检查字段类型
- 分析查询字符串
- 调用term查询,去倒排索引中查询包含quick的文档
- 为每个文档评分并排序
GET /my_index/_search
{
"query": {
"match": {
"title": "QUICK!"
}
}
}检查字段类型
GET /_analyze
{
"text": "QUICK!"
}分析查询字符串,调用term查询,去倒排索引中查询包含quick的文档
GET /my_type/_search
{
"query": {
"term": {
"title": "quick"
}
}
}多词查询
GET /my_index/_search
{
"query": {
"match": {
"title": "BROWN DOG!"
}
}
}
GET /my_index/_search
{
"query": {
"bool": {
"should": [
{"term": {"title": "brown"}},
{"term":{"title":"dog"}}
]
}
}
}为每个文档评分并排序
总结:被匹配的此项越多,文档越相关,排名越靠前
operator:修改匹配关系
GET /my_index/_search
{
"query": {
"match": {
"title": {
"query": "BROWN DOG!",
"operator": "and"
}
}
}
}
GET /my_index/_search
{
"query": {
"bool": {
"must": [
{"term": {"title": "brown"}},
{"term":{"title":"dog"}}
]
}
}
}2. bool(组合查询)
查询包含quick,但不包含lazy的所有文档,如果包含should里的字段,则该文章相关度更高
GET /my_index/_search
{
"query": {
"bool": {
"must": { "match": { "title": "quick" }},
"must_not": { "match": { "title": "lazy" }},
"should": [
{ "match": { "title": "brown" }},
{ "match": { "title": "dog" }}
]
}
}
}3. match_phrase(短语匹配)
GET /my_index/_search
{
"query": {
"match_phrase": {
"title": "quick brown fox"
}
}
}分页(深度分页)from+size
缺点:
- 效率低。比如from=5000,size=100,es需要在各个分片上匹配排序并得到5000+100条有效数据,然后在结果集中取最后100条结果。
- 最大可查询条数为1W条。ES目前默认支持的skin值max_result_window=10000,当from+size>max_result_window时,ES就会返回错误。
- 解决办法:使用scroll(游标查询)
{
"query": {
"match_all": {}
},
"from": 0,
"size": 1
}from:从第几个商品开始查,最开始是 0
size:要查几个结果
排序
根据主文档字段排序
{
"query": {
"match_all": {
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}内嵌文档字段排序
主查询中的过滤条件并不会把不符合条件的内部嵌套文档过滤掉,以至于排序嵌套文档时,还是按照全部的嵌套文档排序
{
"query": {
"nested": {
"path": "shgx",
"query": {
"range": {
"shgx.age": {
"lt": 50
}
}
}
}
},
"sort": [
{
"shgx.age": {
"nested_path": "shgx",
"order": "desc",
"nested_filter": {
"range": {
"shgx.age": {
"lt": 50
}
}
}
}
}
]
}游标查询(scroll)
启动游标查询
CET /host/_search?scroll=1mscroll=1m表示游标查询窗口保持1分钟,如果一次取的数据量大可以设置大一些的时间;返回字段包含一个scroll_id,接下来用这个字段获取后续值
循环获取余下值
GET /_search/scroll
{
"scroll": "1m",
"scroll_id": scroll_id
}python操作
from elasticsearch import Elasticsearch
es = Elasticsearch(['localhost:9200'])
# 1.启动游标
queryData = es.search("internal_isop_log", body=dsl_body, scroll='1m', size=1000)
# 获取scroll_id
hits_list = queryData.get("hits").get("hits")
scroll_id = queryData['_scroll_id']
# 2.循环获取
total = queryData.get("hits").get("total").get('value')
for i in range(int(total / 1000)):
ss = {'scroll': '1m', 'scroll_id': scroll_id}
res = self.es.scroll(body=ss)
模糊查询
创建索引,设置postcode字段使用keyword规则 ❗模糊查询会匹配倒排表里的字段 ❗
PUT /address
{
"mappings": {
"properties": {
"postcode": {
"type": "text",
"analyzer": "keyword"
}
}
}
}导入测试数据
PUT /address/_bulk
{ "index": { "_id": 1 }}
{ "postcode": "W1V 3DG" }
{ "index": { "_id": 2 }}
{ "postcode": "W2F 8HW" }
{ "index": { "_id": 3 }}
{ "postcode": "W1F 7HW" }
{ "index": { "_id": 4 }}
{ "postcode": "WC1N 1LZ" }
{ "index": { "_id": 5 }}
{ "postcode": "SW5 0BE" }倒排表
| Term |
Doc IDs |
| "SW5 0BE" |
5 |
| "W1F 7HW" |
3 |
| "W1V 3DG" |
1 |
| "W2F 8HW" |
2 |
| "WC1N 1LZ" |
4 |
前缀匹配(prefix)
匹配postcode字段以“W1”开头的文档
GET /address/_search
{
"query": {
"prefix": {
"postcode": "W1"
}
}
}通配符查询(wildcard)
GET /address/_search
{
"query": {
"wildcard": {
"postcode": "W?F*HW"
}
}
}正则匹配(regexp)
GET /address/_search
{
"query": {
"regexp": {
"postcode": "W[0-9].+"
}
}
}不配置分词规则带来的影响
栗子:title字段为“Quick brown fox” ,倒排索引中会生成: quick 、 brown 和 fox
| { "regexp": { "title": "br.*" }} |
可以匹配 |
| { "regexp": { "title": "Qu.*" }} |
匹配不到:quick为小写 |
| { "regexp": { "title": "quick br*" }} |
匹配不到:quick和brown是分开的 |
三、聚合分组
ElasticSearch除了致力于搜索之外,也提供了聚合实时分析数据的功能,透过聚合,我们可以得到一个数据的概览,分析和总结全套的数据
对相同的数据进行 搜索/过滤 + 分析,两个愿望一次满足
聚合的两个主要的概念,分别是 桶 和 指标
桶(Buckets) : 满足特定条件的文档的集合
- 当聚合开始被执行,每个文档会决定符合哪个桶的条件,如果匹配到,文档将放入相应的桶并接着进行聚合操作(比如一个员工属于男性桶或者女性桶)
- 桶可以被嵌套在其他桶里面(北京能放在中国桶里)
指标(Metrics) : 对桶内的文档进行统计计算
- 桶能让我们划分文档到有意义的集合, 但是最终我们需要的是对这些桶内的文档进行一些指标的计算
- 指标通常是简单的数学运算(像是min、max、avg、sum)
执行顺序及聚合写法
当query和aggs一起存在时,会先执行query的主查询,主查询query执行完后会搜出一批结果,而这些结果才会被拿去aggs拿去做聚合
伪代码结构
{
"query": { ... },
"size": 0,
"aggs": {
"custom_name1": { // 自定义桶1名称
"桶": { ... } // 桶1查询语句
},
"custom_name2": { // 一个aggs里可以有多个聚合
"桶": { ... }
},
"custom_name3": {
"桶": {
.....
},
"aggs": { // aggs可以嵌套在别的aggs里面
"in_name": { // 记得使用aggs需要先自定义一个name
"桶": { ... } // in_name的桶作用的文档是custom_name3的桶的结果
}
}
}
}
}指标聚合(Metrics)
1. max、min、sum、avg
例:查询所有记录中年龄的最大值
POST /book1/_search?pretty
{
"size": 0,
"aggs": {
"maxage": {
"max": {
"field": "age"
}
}
}
}结果
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 41,
"max_score": 0,
"hits": []
},
"aggregations": {
"maxage": {
"value": 54
}
}
}例:查询所有记录的平均年龄是多少,并对平均年龄加10
POST /book1/_search?pretty
{
"size":0,
"aggs": {
"avg_age": {
"avg": {
"script": {
"source": "doc.age.value"
}
}
},
"avg_age10": {
"avg": {
"script": {
"source": "doc.age.value + 10"
}
}
}
}
}结果:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 41,
"max_score": 0,
"hits": []
},
"aggregations": {
"avg_age": {
"value": 7.585365853658536
},
"avg_age10": {
"value": 17.585365853658537
}
}
}例:为缺失值指定值。如未指定,缺失该字段值的文档将被忽略
POST /book1/_search?pretty
{
"size":0,
"aggs": {
"sun_age": {
"avg": {
"field":"age",
"missing":15
}
}
}
}结果
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 41,
"max_score": 0,
"hits": []
},
"aggregations": {
"sun_age": {
"value": 12.847826086956522
}
}
}2. Value count
统计某字段有值的文档数
POST /book1/_search?size=0
{
"aggs":{
"age_count":{
"value_count":{
"field":"age"
}
}
}
}结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 41,
"max_score": 0,
"hits": []
},
"aggregations": {
"age_count": {
"value": 38
}
}
}3. cardinality
去重计数
POST /book1/_search?size=0
{
"aggs":{
"age_count":{
"value_count":{
"field":"age"
}
},
"name_count":{
"cardinality":{
"field":"age"
}
}
}
}结果
{
"took": 16,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 41,
"max_score": 0,
"hits": []
},
"aggregations": {
"name_count": {
"value": 11
},
"age_count": {
"value": 38
}
}
}4. stats
统计 count max min avg sum 5个值
POST /book1/_search?size=0
{
"aggs":{
"age_count":{
"stats":{
"field":"age"
}
}
}
}结果
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 41,
"max_score": 0,
"hits": []
},
"aggregations": {
"age_count": {
"count": 38,
"min": 1,
"max": 54,
"avg": 12.394736842105264,
"sum": 471
}
}
}5.Extended stats
高级统计,比stats多4个统计结果: 平方和、方差、标准差、平均值加/减两个标准差的区间。
POST /book1/_search?size=0
{
"aggs":{
"age_stats":{
"extended_stats":{
"field":"age"
}
}
}
}结果
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 41,
"max_score": 0,
"hits": []
},
"aggregations": {
"age_stats": {
"count": 38,
"min": 1,
"max": 54,
"avg": 12.394736842105264,
"sum": 471,
"sum_of_squares": 11049,
"variance": 137.13365650969527,
"std_deviation": 11.710408041981085,
"std_deviation_bounds": {
"upper": 35.81555292606743,
"lower": -11.026079241856905
}
}
}
}桶聚合(Buckets)
1. Terms Aggregation
针对某个field的值进行分组,field有几种值就分成几组
- terms桶在进行分组时,会爲此field中的每种值创建一个新的桶
- 要注意此 "terms桶" 和平常用在主查询query中的 "查找terms" 是不同的东西
测试数据
{ "color": "red" }
{ "color": "green" }
{ "color": ["red", "blue"] }dsl语句
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"my_name": {
"terms": {
"field": "color" //使用color来进行分组
}
}
}
}结果
"aggregations": {
"my_name": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "blue",
"doc_count": 1
},
{
"key": "red",
"doc_count": 2 //表示color为red的文档有2个,此例中就是 {"color": "red"} 和 {"color": ["red", "blue"]}这两个文档
},
{
"key": "green",
"doc_count": 1
}
]
}
}2. Filter Aggregation
对满足过滤查询的文档进行聚合计算
要注意此处的 "filter桶" 和用在主查询query的 "过滤filter" 的用法是一模一样的,都是过滤,不过差别是 "filter桶" 会自己给创建一个新的桶,而不会像 "过滤filter" 一样依附在query下,因为filter桶毕竟还是一个聚合桶,因此他可以和别的桶进行嵌套,但他不是依附在别的桶上
测试数据同上
dsl语句
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"my_name": {
"filter": { //因为他用法跟一般的过滤filter一样,所以也能使用bool嵌套
"bool": {
"must": {
"terms": { //注意此terms是查找terms,不是terms桶
"color": [ "red", "blue" ]
}
}
}
}
}
}
}结果
"aggregations": {
"my_name": {
"doc_count": 2 //filter桶计算出来的文档数量
}
}3. Filters Aggregation
多个过滤组聚合计算
例:分别统计包含‘test’,和‘里’的文档的个数
POST book1/_search?size=0
{
"aggs":{
"age_terms":{
"filters":{
"filters":{
"test":{
"match":{"name":"test"}
},
"china":{
"match":{"name":"里"}
}
}
}
}
}
}结果:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 41,
"max_score": 0,
"hits": []
},
"aggregations": {
"age_terms": {
"buckets": {
"china": {
"doc_count": 13
},
"test": {
"doc_count": 5
}
}
}
}
}4. Top_hits Aggregation
在某个桶底下找出这个桶的前几笔hits,返回的hits格式和主查询query返回的hits格式一模一样
参数
- from、size
- sort : 设置返回的hits的排序
- 要注意,假设在主查询query里已经对数据设置了排序sort,此sort并不会对aggs里面的数据造成影响,也就是说主查询query查找出来的数据会先丢进aggs而非先经过sort,因此就算主查询设置了sort,也不会影响aggs数据里的排序因此如果在top_hits桶里的返回的hits数据想要排序,需要自己在top_hits桶里设置sort
- 如果没有设置sort,默认使用主查询query所查出来的_score排序
- _source : 设置返回的字段
测试数据
{ "color": "red", "price": 100 }
{ "color": ["red", "blue"], "price": 1000 }使用terms桶分组,再使用top_hits桶找出每个group里面的price最小的前5笔hits
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"my_name": {
"terms": {
"field": "color"
},
"aggs": {
"my_top_hits": {
"top_hits": {
"size": 5,
"sort": {
"price": "asc"
}
}
}
}
}
}
}结果
"aggregations": {
"my_name": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "red",
"doc_count": 2, //terms桶计算出来的color为red的文档数
"my_top_hits": {
"hits": { //top_hits桶找出color为red的这些文档中,price从小到大排序取前5笔
"total": 2,
"max_score": null,
"hits": [
{
"_score": null,
"_source": { "color": "red", "price": 100 },
"sort": [ 100 ]
},
{
"_score": null,
"_source": { "color": [ "red", "blue" ], "price": 1000 },
"sort": [ 1000 ]
}
]
}
}
},
{
"key": "blue",
"doc_count": 1, //terms桶计算出来的color为blue的文档数
"my_top_hits": {
"hits": { //top_hits桶找出的hits
"total": 1,
"max_score": null,
"hits": [
{
"_source": {
"color": [ "red", "blue" ], "price": 1000 },
"sort": [ 1000 ]
}
]
}
}
}
]
}
}5. Date_histogram Aggregation
时间直方图(柱状)聚合
参数
- time_zone:"+08:00":设置市区(东八区),不指定会影响分组时间错误
- interval:聚合时间间隔
- year(1y)年
- quarter(1q)季度
- month(1M)月份
- week(1w)星期
- day(1d)天
- hour(1h)小时
- minute(1m)分钟
- second(1s)秒
- format:指定返回时间格式
dsl语句
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
// 自己取的聚合名字
"group_by_grabTime": {
// es提供的时间处理函数
"date_histogram": {
// 需要聚合分组的字段名称, 类型需要为date, 格式没有要求
"field": "@timestamp",
// 按什么时间段聚合, 这里是5分钟, 可用的interval在上面给出
"interval": "5m",
// 设置时区, 这样就相当于东八区的时间
"time_zone": "+08:00",
// 返回值格式化,HH大写,不然不能区分上午、下午
"format": "yyyy-MM-dd HH",
// 为空的话则填充0
"min_doc_count": 0,
// 需要填充0的范围
"extended_bounds": {
"min": 1533556800000,
"max": 1533806520000
}
},
// 聚合
"aggs": {
// 自己取的名称
"group_by_status": {
// es提供
"terms": {
// 聚合字段名
"field": "LowStatusOfPrice"
}
}
}
}
}
}