Numpy中多维数组创建及其基本属性(一)
数组创建及其基本属性
- 前言
- 一、怎么判断维度?
-
-
-
- 1.一维:
- 2.二维:
- 3.三维:
-
-
- 二、多维数组(ndarray)创建的方法 有主要哪些?
-
-
-
- 1. **array函数**
- 2. **arange函数**
- 3. **linspace函数**
- 4. **logspace函数**
- 5. **eye函数**
- 6. **identity函数**
- 7. **zeros、zeros_like函数**
- 8. **ones、ones_like函数**
- 9. **empty、empty_like函数**
- 10. **diag函数**
-
- 产生随机数需要用到numpy中ramdom模块
-
-
- 11. **rand函数**
- 12. **random函数**
- 13. **randint函数**
- 14. **randn函数**
- 15. **seed函数**
- 16. **permutation函数**
- 17. **shuffle函数**
- 18. **uniform函数**
- 19. **normal函数**
- 20. **poisson函数**
-
-
- 三、多维数组(ndarray)对象的属性 有主要哪些?
-
- 多维数组(ndarray)对象的属性
-
-
- 1. **ndim**
- 2. **shape**
- 3. **size**
- 4. **reshape**
- 5. **dtype**
- 6. **itemsize**
-
- 总结
前言
python中创建数组有一定的限制,而python借助numpy库却有许多扩展,功能更多,那么如何创建呢? 请大家看过来!一、怎么判断维度?
–这里我们主要是通过看外中括号的数判断,当然还有别的方法,会在多维数组(ndarray)对象的属性中讲到的!
1.一维:
arr1 = [1,2,3]
![]()
2.二维:
arr2 = [[1,2,3],[4,5,6]]
![]()
3.三维:
arr3 = [[[1,2,3],[1,2,3]],[[1,2,3],[1,2,3]]]
![]()
二、多维数组(ndarray)创建的方法 有主要哪些?
调用numpy中方法时,注意一定一定要导库!
1. array函数
array(object, dtype=None, copy=True, order=None, subok=False, ndmin=0)
代码如下(示例):

object:接收一个数组对象
dtype:数据类型,你可以设置
copy:对象是否要复制
order: {‘C’, ‘F’},可选。输出应该以行为主(c风格),还是在内存中以列为主(fortran风格)顺序
subok:默认返回一个与基类类型一致的数组
ndmin:设置当前最小的维度
2. arange函数
arange([start,] stop[, step,], dtype=None)
类似于内置的range函数,用于创建数组
arange 中取值左闭右开
代码如下(示例):
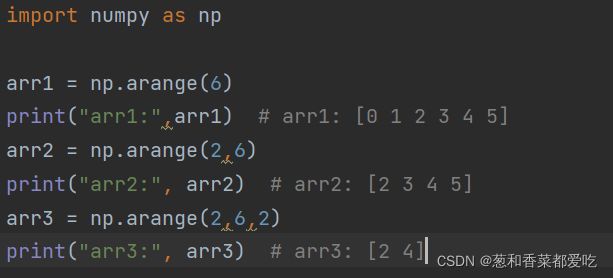
start:开始值,可以省略
stop:结尾值,取不到
step:间隔 取值
dtype:数据类型,你可以设置
3. linspace函数
linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None,
axis=0):
在指定的间隔内返回均匀间隔的数字。
代码如下(示例):

start:开始值
stop: 结尾值
num: 均匀取的个数,50,表示取50个
endpoint:端点,可选。如果为True, ’ stop ‘是最后一个样本就可以取。否则,反之
retstep: bool,可选。如果为True,返回(’ samples ', ’ step ‘),其中’ step '是间距之间的样本
dtype:数据类型,你可以设置
axis:0表示行,1表示列
4. logspace函数
logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None,
axis=0):
创建指定个数的等比数列。
代码如下(示例):

start:开始值
stop: 结尾值
num: 均匀取的个数,50,表示取50个
base: 这个基数的等比数列
endpoint:端点,可选。如果为True, ’ stop '是最后一个样本就可以取。否则,反之
dtype:数据类型,你可以设置
axis:0表示行,1表示列
5. eye函数
eye(N, M=None, k=0, dtype=float, order=‘C’)
可创建正方形的N*N单位矩阵,np.eye可以创建矩形矩阵。
代码如下(示例):

N:输出的行数
M:输出的列数
K:对角线的索引,默认为0。0时就是对角线,值大于0时对角线往上走,值小于0时对角线往下走
dtype:数据类型,你可以设置
order: {‘C’, ‘F’},可选。输出应该以行为主(c风格),还是在内存中以列为主(fortran风格)顺序
6. identity函数
identity(n, dtype=None)
可创建正方形的N*N单位矩阵,np.identity 只能 创建方形矩阵,
代码如下(示例):
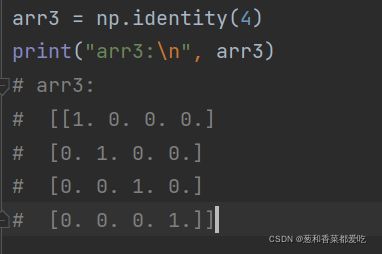
n:几行几列
dtype:数据类型,你可以设置
7. zeros、zeros_like函数
zeros(shape, dtype=None, order=‘C’)
zeros_like(a, dtype=None, order=‘K’, subok=True, shape=None)
创建全0数组
zeros_like以另一个数组为参考,根据其形状和dtype创建全0数组
代码如下(示例):
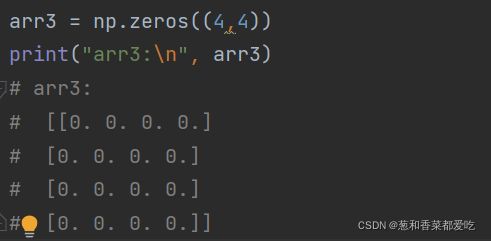
shape:一个数组
dtype:数据类型,你可以设置
order: {‘C’, ‘F’},可选。输出应该以行为主(c风格),还是在内存中以列为主(fortran风格)顺序

a:接收另一个数组,以它为参考
8. ones、ones_like函数
ones(shape, dtype=None, order=‘C’)
ones_like(a, dtype=None, order=‘K’, subok=True, shape=None)
创建全1数组
ones_like以另一个数组为参考,根据其形状和dtype创建全1数组
代码如下(示例):

shape:一个数组
dtype:数据类型,你可以设置
order: {‘C’, ‘F’},可选。输出应该以行为主(c风格),还是在内存中以列为主(fortran风格)顺序
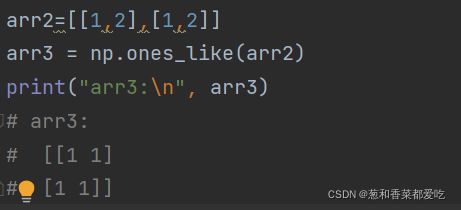
a:接收另一个数组,以它为参考
9. empty、empty_like函数
empty(shape, dtype=None, order=‘C’)
empty_like(a, dtype=None, order=‘K’, subok=True, shape=None)
同上。创建没有具体值的数组(垃圾值)
代码如下(示例):
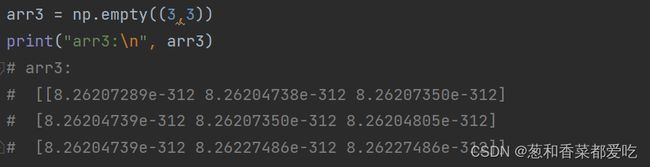
shape:一个数组
dtype:数据类型,你可以设置
order: {‘C’, ‘F’},可选。输出应该以行为主(c风格),还是在内存中以列为主(fortran风格)顺序

a:接收另一个数组,以它为参考
10. diag函数
diag(v, k=0)
以一维数组的形式返回方阵的对角线(或非对角线)元素,或将一维数组转换成方阵(非对角线元素为0).两种功能角色转变取决于输入的v。
代码如下(示例):

v : array_like.
如果v是2D数组,返回k位置的对角线。
如果v是1D数组,返回一个v作为k位置对角线的2维数组。
k : int, optional
产生随机数需要用到numpy中ramdom模块
既然是随机数每次运行产生的结果是不一样的(为什么了,请看到seed函数部分!)
11. rand函数
rand(d0, d1, …, dn)
产生均匀分布的样本值(在0~1中取随机数)
代码如下(示例):

d0, d1, …, dn:填数字,填1个是一维,2个是二维,以此类推
12. random函数
random(size=None)
产生随机数(在0~1中取随机数)
代码如下(示例):
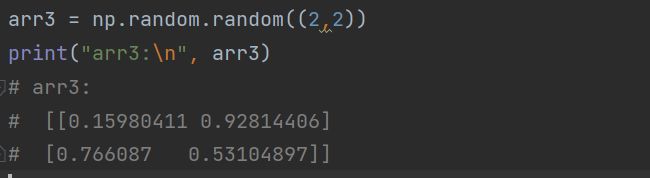
size:一个数组
13. randint函数
randint(low, high=None, size=None, dtype=None)
给定范围内取随机整数。
代码如下(示例):
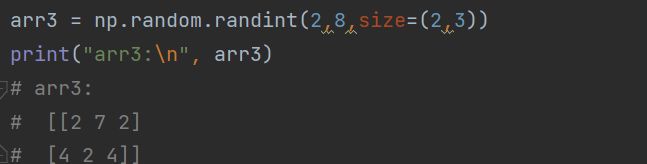
low:最小值
high:最大值
size:一个数组
dtype:数据类型
14. randn函数
randn(d0, d1, …, dn)
产生正态分布的样本值。
代码如下(示例):

d0, d1, …, dn:填数字,填1个是一维,2个是二维,以此类推
15. seed函数
seed(self, seed=None)
随机数种子。(随机数每次运行产生的结果是不一样的,但有了seed函数可以让输出的结果是一样的)之前没有设置种子数,每运行一次随机数种子数都会变。所有随机数每次运行产生的结果是不一样的!
代码如下(示例):

seed:种子数
16. permutation函数
permutation(x)
对一个序列随机排序,不改变原数组
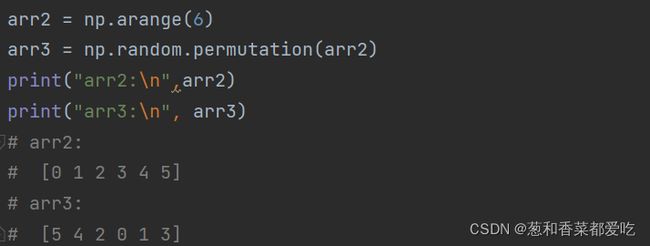
x:加入一个数组(变量)
代码如下(示例):
17. shuffle函数
shuffle(x)
对一个序列随机排序,改变原数组。
代码如下(示例):
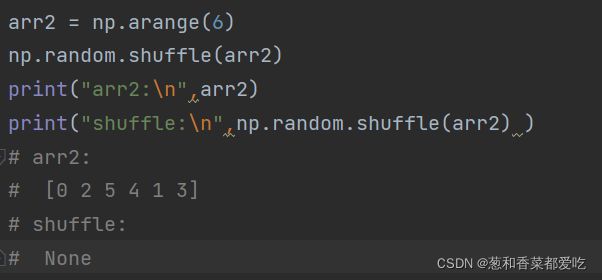
x:加入一个数组(变量)(为什么shuffle返回none?
因为在这个函数中的return的值是none)
18. uniform函数
uniform(low=0.0, high=1.0, size=None)
产生具有均匀分布的数组
代码如下(示例):

low:起始值
high:结束值
size:形状,一个数组
19. normal函数
normal(loc,scale,size)
产生具有正态分布的数组
代码如下(示例):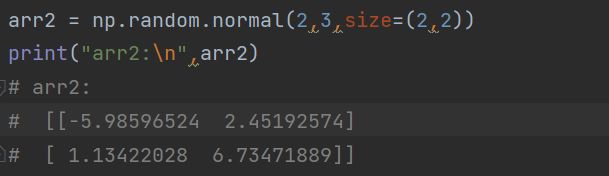
loc:均值
scale:标准差。
size:形状,一个数组
20. poisson函数
poisson(lam,size)
产生具有泊松分布的数组
代码如下(示例):

lam随机事件发生率
size:形状,一个数组
三、多维数组(ndarray)对象的属性 有主要哪些?
多维数组(ndarray)对象的属性
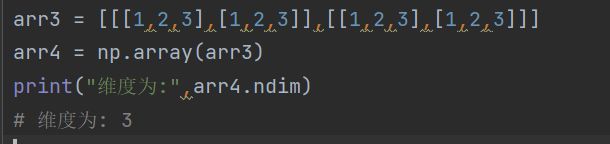
1. ndim
表示数据轴的个数,即数组的维度(这里也可以判断维度)
代码如下(示例):
2. shape
表示数组的尺寸,返回一个元组,为几行几列(这里也可以判断维度)
代码如下(示例):

这是什么意思呢?
我们看括号里数字,括号里有几位数就是几维!
如:(2,2,3)有3个数 表示为三维数组
(2,2,3)表示是一个三维数组,里面有2个二维数组,每二维数组中有2个一维数组,每一维数组中有3个数!
还没理解 再看下一个例子:
(3,4,5,2)表示是一个四维数组,里面有3个三维数组,每三维数组中4个二维数组,每二维数组中有5个一维数组,每一维数组中有2个数!
这下该明白了吧!=><=
3. size
表示元素的总数(就是一个数组中有几个数)
代码如下(示例):

4. reshape
可以改变数组的维度 但要保持个数一样
代码如下(示例):

开始是一个2行3列,该后成了3行2列!
5. dtype
表示数据类型
代码如下(示例):
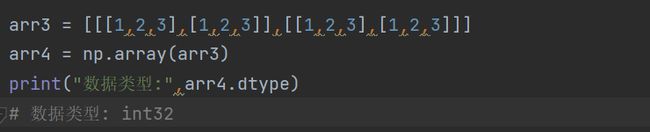
这里默认的数据类型是 int32, 可以通过astype来改变数据类型
代码如下(示例):

6. itemsize
表示数组中每个元素的字节大小

arr4数组的数据类型是int32 ,对于计算机而言,1个字节是8位,所以arr4的itemsize属性值为4!(32/8=4)
如果是arr4数组的数据类型是int64,arr4的itemsize属性值为8!(64/8=8)
总结
Numpy中多维数组创建及其基本属性还有许多,我只写了一些基础的。很多写的也没那么好,如果有写错了的,希望大家能指出!谢谢了!抱拳!抱拳!