L-SHADE(Improving the Search Performance of SHADE Using Linear Population Size Reduction)
Abstract
L-SHADE在SHADE的基础上,扩展了线性种群规模缩减(LPSR),即根据线性函数不断减少种群规模。
II SUCCESS-HISTORY BASED ADAPTIVE DE WITH
DE表示为实参向量 x i = ( x 1 , … … , X D ) , i = 1 , … … , N x_i=(x_1,……,X_D),i=1,……,N xi=(x1,……,XD),i=1,……,N, D D D为维度, N N N是种群数。搜索开始时,种群中的向量初始化,重复策略直至终值。
A. Control parameters assignments based on historical memory
SHADE控制DE的参数 C R CR CR、 F F F、 M C R M_{CR} MCR和 M F M_F MF。缩放因子 F ∈ [ 0 , 1 ] F\in [0,1] F∈[0,1]控制差分突变因子, C R ∈ [ 0 , 1 ] CR\in[0,1] CR∈[0,1]是交叉率,开始时 M C R , k M_{CR,k} MCR,k和 M F , k ( k = 1 , … … , H ) M_{F,k}(k=1,……,H) MF,k(k=1,……,H)被初始化为0.5,通过从 [ 1 , H ] [1,H] [1,H]随机选择一个下标 r i r_i ri,生成每个个体的参数:

如果交叉率 C R i CR_i CRi生成了[0,1]之外的值,则生成最近的 0 0 0或 1 1 1。
当 F i > 1 F_i \gt 1 Fi>1时, F i F_i Fi被截断为 1 1 1;当 F i ≤ 0 F_i \leq 0 Fi≤0,重复 ( 2 ) (2) (2)式,以生成有效值。
以上为JADE。
B. Reproduction of trial vectors by using current-topbest/1/bin
在为每个个体 x i , G x_{i,G} xi,G分配了 C R i CR_i CRi和 F i F_i Fi后,通过应用current-to-pbest/1突变策略(即JADE使用的突变策略)和current-to-best/1 策略,生成突变向量,其中贪婪度可以使用 p p p来调整:
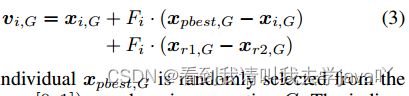
其中,个体 x p b e s t , G x_{pbest,G} xpbest,G是第 G G G次迭代的前 N × p ( p ∈ [ 0 , 1 ] ) N\times p(p\in[0,1]) N×p(p∈[0,1])中随机挑选的, r 1 r_1 r1和 r 2 r_2 r2是从 [ 1 , N ] [1,N] [1,N]中随机挑选的,彼此不同。current-to-pbest/1的贪婪程度取决于控制参数 p p p,小 p p p更加贪婪。
针对每个维度 j j j,若突变向量 x j , i , G x_{j,i,G} xj,i,G在边界 [ x j m i n , x j m a x ] [x^{min}_j,x^{max}_j] [xjmin,xjmax]之外,则应校正:

在生成突变向量 v i , G v_{i,G} vi,G后,将其与父向量 x i , G x_{i,G} xi,G交叉,生成试验向量 u i , G u_{i,G} ui,G,使用如下交叉策略Binomial Crossover:

C. Survival for next generation
选择策略,保留更好的:

D. External archive
在JADE中,外部存档external archive用于维护多样性。
比 u i , G u_{i,G} ui,G差且未被公式 ( 6 ) (6) (6)选择的 x i , G x_{i,G} xi,G保存下来。
当使用存档时,式 ( 3 ) (3) (3)中的 x r 2 , G x_{r_2,G} xr2,G是从集合 P ⋃ A P\bigcup A P⋃A中选取的,其中 P P P是种群, A A A是存档库。
每当存档的大小超过预定的存档大小 ∣ A ∣ |A| ∣A∣时,则随机删除元素再插入新元素。
E. Historical-memory update
在每一次迭代中,经过选择后生成 u i , G u_{i,G} ui,G的 C R i CR_i CRi和 F i F_i Fi要比生成 x i , G x_{i,G} xi,G的 S C R S_{CR} SCR和 S F S_F SF更好,因此更新,此步算法如下:

其中,索引 k ( 1 ≤ k ≤ H ) k(1\leq k \leq H) k(1≤k≤H)决定了更新在内存中的位置。 k k k初始化为 1 1 1,每当有新的元素插入时, k k k增加,在第 G G G次迭代中,内存中第 k k k个元素会被更新。当 k > H k \gt H k>H时, k = 1 k=1 k=1。
当所有个体都不能生成优于 x x x的 u u u时,不更新。
加权Lehmer均值 m e a n W L ( S ) mean_{WL}(S) meanWL(S)由下式计算,适应度改善量 △ f k \bigtriangleup f_k △fk用于影响参数自适应( S S S指 S C R S_{CR} SCR或 S F S_F SF)
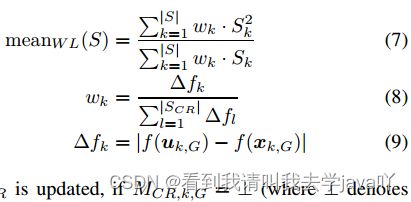
如果 M C R , k , G = ⊥ M_{CR,k,G}=\bot MCR,k,G=⊥或 m a x ( S C R ) = 0 max(S_{CR})=0 max(SCR)=0(例如 S C R S_{CR} SCR的所有元素都为 0 0 0), M C R , k , G + 1 = ⊥ M_{CR,k,G+1}=\bot MCR,k,G+1=⊥。因此如果 M C R = ⊥ M_{CR}=\bot MCR=⊥,则保持此值直至结束,即 C R CR CR一直保持为 0 0 0,这将会减慢收敛速度,对多模态问题有效。
F. Linear Population Size Reduction (LPSR) and L-SHADE algorithm
本文使用线性种群规模缩减(LPSR),即SVPS的简单特化,作为适应度评估函数线性地缩减种群规模。
LPSR不断缩减种群以匹配一个线性函数。在第一次迭代时,种群规模数是 N i n i t N^{init} Ninit,运行结束时种群规模数是 N m i n N^{min} Nmin。在每一次迭代后,下一次迭代的种群规模按如下公式计算:

其中, N m i n N^{min} Nmin被设置为可能的最小值。在L-SHADE中, N m i n = 4 N^{min}=4 Nmin=4,因为current-to-pbest突变策略需要 4 4 4个个体。
N F E NFE NFE是当前适应度评价的个数, M A X N F E MAXNFE MAXNFE是适应度评价的最大个数。
当 N G + 1 < N G N_{G+1} \lt N_G NG+1<NG时, ( N G − N G + 1 ) (N_G-N_{G+1}) (NG−NG+1)个排名最差的个体从种群中删除。

在上图算法中,行21-24加入了LPSR,在行24中,参数 ∣ A ∣ |A| ∣A∣被重新调整,性能优于 ∣ A ∣ = N i n i t |A|=N^{init} ∣A∣=Ninit。