后端开发面试必会:数据库基础知识及常见面试问题
1、如何设计一个数据库?
分为 8 个模块:
1、存储管理,管理存储的数据。
2、缓存机制,一次加载多个,增加下次查找的效率。
3、sql解析,解析输入的sql语句。
4、日志管理,记录数据库的操作。
5、权限划分,设定不同用户的不同权限。
6、容灾机制,出问题后恢复数据的能力。
7、索引管理,优化数据查询效率。
8、锁管理,使数据库支持并发操作。
注意:索引、索 是面试的重点。

2、索引有哪些数据结构?各有哪些优缺点?
首先,索引是排好序的数据结构。
1、二叉搜索树,不适合处理递增的链式数据,深度过大。
2、红黑树(平衡后的二叉搜索树,不平衡时自动旋转保存平衡,减少索引次数),不适合存储大量数据,树深度巨大。
3、hash,key-value对应,查询速度快;
但无法进行范围查找,无法用来避免数据的排序操作,无法避免表扫描,运到同key的多value时不一定速度快。
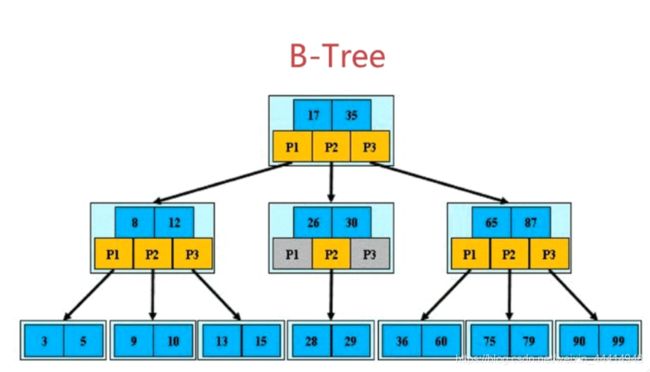
4、B树,一种多叉平衡搜索树,扩展了每层节点的分叉数目,存更多的data,非叶子节点也存data(但此存储方式存储索引数量远少于B+)。
叶子间无双向指针,范围查找效率低。
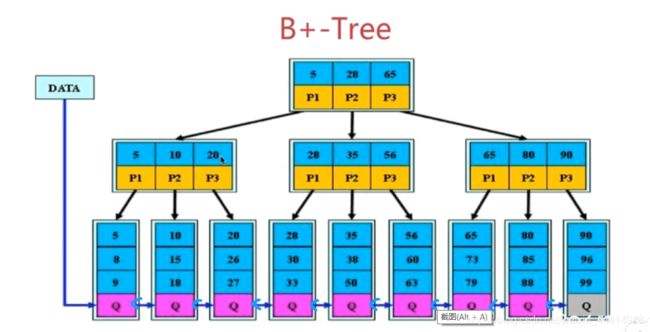
5、B+树(多叉平衡搜索树),
(1)非叶子节点不存data,只存索引,可以放更多索引;
(2)叶子节点包含所有索引字段;
(3)叶子节点用双向指针连接,提高区间的访问性能。
为帮助理解,附上B树、B+树的示例图:
3、聚集索引与非聚集索引的区别
聚集索引(密集索引):索引和数据放在一起,比如InnoDB格式的表,底层包含. frm(存表的形式)和. idb(存索引和数据)两个文件。相对于MyISAM少加载一次数据文件,速度更快。
非聚集索引(稀疏索引):索引和数据分开放,比如MyISAM格式的表,底层包含. frm、. MYI(索引)、. MYD(数据)三个文件。
4、MyISAM 和 InnoDB 的应用场景
MyISAM适合场景:频繁执行全表count语句;对数据进行增删改的频率不高,查询十分频繁;没有事务。
InnoDB适合场景:数据增删改查都相当频繁;可靠性要求比较高,要求支持事物。
5、InnoDB为什么做项目时一定要建主键?为什么推荐使用整型自增主键?
1、InnoDB一定建主键,没有主键时,mysql会自动查找无重复的列作为主键,效率低下。
且不便后期维护查找。
2、uuid字符串主键不推荐(比较大小时效率低,占用空间大),自增支持范围查找(B+树的叶子节点间的双向指针)。
同时自增可以减少树的分裂平衡操作的概率。
6、什么是联合索引?不按联合索引查找会怎么样?
联合索引,mysql以索引顺序设置优先级,优先按前一个索引进行排序,查询时也要按照原本顺序才能进行查找。从底层原理看就是,B+树叶子节点的排序是按照原本索引顺序依次排序连接,即最左前缀匹配原则(比如name、age、position,优先以name进行排序),不按原本索引顺序进行查找会直接走全表扫描。
联合索引示例图如下:

7、索引是否建立地越多越好?
数据量小的表不需要额外索引,更多索引意味着更多的索引开销。数据变更需要维护索引,索引多意味着维护成本高。
8、锁是如何划分的?解释一下?
1、按锁的粒度划分,可分为表级锁、行级锁、页级锁。
MyISAM仅支持表级锁,InnoDB支持表级锁、行级锁。
2、按锁的级别划分,可分为共享锁、排它锁。
共享锁执行中允许其他共享锁执行,其余情况的两锁都冲突,必须等待前面锁解开才能开始执行。
3、按加锁方式划分,可分为自动锁、显式锁。
自动锁就是sql语句运行时自动加上的锁,显式锁是执行锁语句的锁。
4、按操作划分,可分为DML锁、DDL锁。
DML锁是执行增删改查时加上的锁,DDL锁是更改表结构加上的锁。
5、按使用方式划分,可分为乐观锁、悲观锁。
乐观锁全程不主动加锁只记录操作,悲观锁是全程加上排它锁。
9、数据库事务的特性
1、原子性(指commit时提交所有操作,rollback时取消所有操作);
2、一致性(指不管如何并发操作,最后结果应该一致);
3、隔离性(指各并发操作应该不相互干扰);
4、持久性(指一个操作一旦commit,结果改变就是持久的)。
10、数据库的四个事务发生原因及如何解决?
隔离级别:READ-UNCOMMITED(未提交读) < READ-COMMITED(已提交读) < REPEATABLE-READ(可重复读) < SERIALIZABLE(串行化)
1、更新丢失:
多个操作并发执行,某并发操作rollback,导致当前操作丢失信息。
mysql所有事务隔离级别在数据库层面上均可避免。
2、脏读:
当前操作读取到了其他并发操作的未commit的执行过程,导致当前操作结果不可信。
READ-COMMITTED事务隔离级别以上可避免。
3、不可重复读:
因不可重读读取当前操作的数据改变,导致其他并发操作引发的结果未及时更新。
REPEATABLE-READ事务隔离级别以上可避免。
4、幻读:
与不可重复读类似,侧重于数据增加或删除。
SERIALIZABLE事务隔离级别可避免。

11、什么是当前读、快照读?
1、当前读:读取当前数据的最新状态,同时在该语句执行完成前,加上排他锁(容易触发幻读)。
语句包括update、delete、insert。
2、快照读:读取当前数据的状态(不一定是最新的),不加锁。
语句包括select。
一般实现InnoDB的非阻塞,来提高数据库的并发性。(即实现操作的快照读)