SQLAlchemy ORM指南:简化数据库操作的最佳实践
SQLAIchemy 开发指南
背景:
SQLAlchemy是一个数据库的ORM框架,让我们操作数据库的时候不要再用SQL语句了,跟直接操作模型一样。操作十分便捷,其实SQLAlchemy应该是在Flask和Django应用的特别多,而且在flask中已经集成了flask_sqlalchemy ,好像是 SQLAlchemy的作者和 Flask是同一个,背景了解到这里就可以啦,接下来为大家讲一讲。
环境安装:
pip install SQLAlchemy
conda install SQLAlchemy
当然了你还需要配置好数据库mysql或者mongodb,sqlite等等。
测试连接:
# -*- coding: utf-8 -*-
from sqlalchemy import create_engine
from sqlalchemy import text
# MySQL所在的主机名
HOSTNAME = "127.0.0.1"
# MySQL监听的端口号,默认3306
PORT = 13306
# 连接MySQL的用户名,读者用自己设置的
USERNAME = "root"
# 连接MySQL的密码,读者用自己的
PASSWORD = "xxxxx"
# MySQL上创建的数据库名称
DATABASE = "learning"
DB_URI = f"mysql+pymysql://{USERNAME}:{PASSWORD}@{HOSTNAME}:{PORT}/{DATABASE}"
# 创建数据库引擎
engine = create_engine(DB_URI)
# 所有的类都要继承自`declarative_base`这个函数生成的基类
Base = declarative_base(engine)
#创建连接
with engine.connect() as con:
rs = con.execute('SELECT 1')
# 如果报错的话,加上text() 就不会报错。
# rs = con.execute(text('SELECT 1'))
print(rs.fetchone())

首先从sqlalchemy中导入create_engine,用这个函数来创建引擎,然后用engine.connect()来连接数据库。但是创造引擎要满足固定的格式:db+driver(驱动)/username:password@host:port/database?charset=utf8
- db 为数据库类型,MySQL、PostgreSQL、SQLite,并且转换成小写。
- driver 就是驱动,python会有一些第三方扩展包,连接数据库 ,如果不指定,会选择默认的驱动,MySQL常用的驱动右Mysqldb,pymysql,这里建议大家使用pymysql因为mysqldb这个包很容易报错,版本容易不匹配。
- username是连接数据库的用户名
- password是连接数据库的密码
- host是连接数据库的域名
- port是数据库监听的端口号
- database是连接哪个数据库的名字。
这里为大家主要讲解的是mysql结合SQL alchemy的使用。
原生查询:
#创建连接
with engine.connect() as con:
# rs = con.execute(text('SELECT 1'))
rs=con.execute("show tables")
print(rs.fetchall())

创建表:
class User(Base):
# 定义表名为users
__tablename__ = 'users'
# 将id设置为主键,并且默认是自增长的
id = Column(Integer, primary_key=True, autoincrement=True)
# name字段,字符类型,最大的长度是50个字符
name = Column(String(50))
fullname = Column(String(50))
password = Column(String(100))
# 修改内置方法
def __str__(self):
return "" % (
self.id, self.name, self.fullname, self.password)
# 执行提交命令
Base.metadata.create_all()
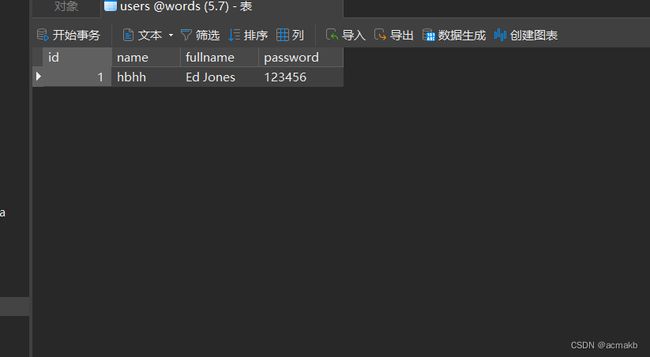
我们回到数据库查看发现,自动生成了一张表:

添加数据:
# 对于数据的增减删查 我们依靠session对象,session即会话对象
Session = sessionmaker(bind=engine)
# 创建以一个会话对象
session = Session()
# 创建一个对象
ed_user = User(name='hbhh', fullname='Ed Jones', password='123456') #
# 添加到会话
session.add(ed_user)
# 添加到数据库
session.commit()
关于会话的理解:
可能大家有这样的疑问?为什么我要想对会话做操作,然后在对数据库进行修改呢,个人的理解是因为安全,就是假如我们真的做错了,数据库信息已经改变了,那么我们只能对数据库进行修改了,这显然不符合软件开发,如果我前面做错了,我可以回滚啊,就是撤销的意思,会话就是一个很好的解决方式,我们可以先将操作提交到缓存上,然后再对数据库进行相应的操作。
# 创建一个新的用户
fake_user = User(name='fakeuser',fullname='Invalid',password='12345')
session.add(fake_user)
# 判断`fake_user`是否在`session`中存在
print(fake_user in session) # True
session.rollback() # 回滚
print(fake_user in session) # False
但是你到数据库是查不到这个fake_user的,因为之前说了目前只在session层面做了操作,没用对数据库做操作,所以你也找不到。
查询:
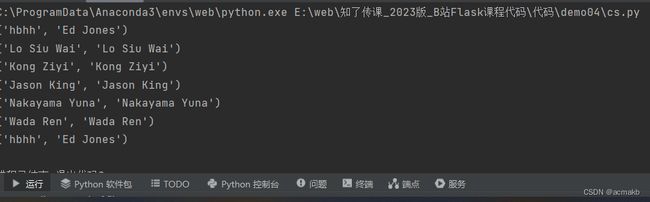
for demo in session.query(User).order_by(User.id).all():
# all() 是获取所有结果集 one() 是获取一个
print(demo)

for instance in session.query(User.name).all():
print(instance)

for instance in session.query(User.name,User.fullname).all():
print(instance) # 输出所有的查找结果
过滤查询:
如果想对结果进行过滤,可以使用filter_by和filter两个方法,这两个方法都是用来做过滤的,区别在于,filter_by是传入关键字参数,filter是传入条件判断,并且filter能够传入的条件更多更灵活。
# query() 参数就是想要的结果
for name in session.query(User.name).filter_by(fullname='Kong Ziyi').all():
print(name)
for name in session.query(User.name).filter(User.fullname=='Kong Ziyi').all():
print(name)

过滤条件:
相等:
query.filter(User.name == 'ed')
不相等:
query.filter(User.name != 'ed')
模糊:
query.filter(User.name.like('%ed%'))
for user in session.query(User).filter(User.name.like('%o%')).all():
print(user)

在:
query.filter(User.name.in_(['ed','Venti','Klee']))# 同时,in也可以作用于一个Query
query.filter(User.name.in_(session.query(User.name).filter(User.name.like('%o%'))))
不在:
query.filter(~User.name.in_(['ed','Venti','Klee']))
print(session.query(User).filter(~User.name.in_(['ed','Venti','Klee'])))
空值:
query.filter(User.name==None)# 或者是
query.filter(User.name.is_(None))
非空:
query.filter(User.name != None)# 或者是
query.filter(User.name.isnot(None))
与:
from sqlalchemy import and_
query.filter(and_(User.name=='ed',User.fullname=='Ed Jones'))# 或者是传递多个参数
query.filter(User.name=='ed',User.fullname=='Ed Jones')# 或者是通过多次filter操作
query.filter(User.name=='ed').filter(User.fullname=='Ed Jones')
或者:
from sqlalchemy import or_
query.filter(or_(User.name=='ed',User.name=='Venti'))
结果筛选:
query = session.query(User).filter(User.name.like('%o%')).order_by(User.id)
print(query.all()) # 结果集全部
# print(query.one()) # 结果集只有一个才能用,不然会报错
print(query.first()) # 结果集第一个
print(query.count()) # 结果集数量
session.query(User).filter(User.name.like('%ed%')).count()

聚合查询:
group_by(分组字段)
from sqlalchemy import func
# query(func.count(User.name),User.name) 两个参数 就相当于sql 得到的两个查询字段
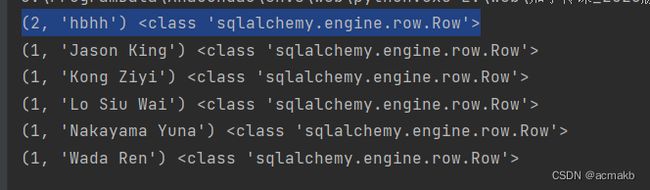
for user in session.query(func.count(User.name),User.name).group_by(User.name).all():
print(user,type(user))
session.query(User.gender,func.count(User.id)).group_by(User.gender).all()
温馨提示:
所有的查询得到:都是类似一个sql语句的东西:如下
print(session.query(User.name).filter(User.fullname=='Kong Ziyi'))

如果我们想得到相应的对象,必须加all()、one() 才可以得到真正意义上的对象。
print(session.query(User.name).filter(User.fullname=='Kong Ziyi').one())

文本SQL:
SQLAlchemy还提供了使用****文本SQL****的方式来进行查询,这种方式更加的灵活。与数据库对接比较紧密。
但是需要将sql语句放在text() 中。
from sqlalchemy import text
from sqlalchemy import text
# text() 中的内容 就是sql语句
for user in session.query(User).filter(text("id<10")).order_by(text("id")).all():
print(user.name)

上面这种写法有一个缺陷就是写死了,如果我们传递的是一个变量呢?
session.query(User).filter(text("id<:value and name=:name")).params(value=224,name='ed').order_by(User.id)
# value是变量 name也是变量
在文本SQL中的变量前面使用了:来区分,然后使用params方法,指定需要传入进去的参数。
这样的写法有一点麻烦,及要写过滤的函数还要写 条件函数,我们可以采取下面分方法:
sesseion.query(User).from_statement(text("select * from users where name=:name")).params(name='ed').all()
for user in session.query(User).from_statement(text("select * from users where name=:name")).params(name='hbhh').all():
print(user)
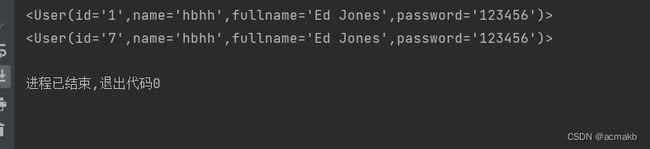
from_statement 返回的是一个text里面的查询语句,最后一定要使用all() ,获取结果集。
Column常用参数:
- default:默认值。
- nullable:是否可空。
- primary_key:是否为主键。
- nique:是否唯一。
- autoincrement:是否自动增长。
- onupdate:更新的时候执行的函数。
- name:该属性在数据库中的字段映射。
数据类型:
sqlalchemy常用数据类型:
- Integer:整形。
- Float:浮点类型。
- Boolean:传递True/False进去。
- DECIMAL:定点类型。
- enum:枚举类型。
- Date:传递datetime.date()进去。
- DateTime:传递datetime.datetime()进去。
- Time:传递datetime.time()进去。
- String:字符类型,使用时需要指定长度,区别于Text类型。
- Text:文本类型。
- LONGTEXT:长文本类型。
总结:
在这篇博客中,你详细介绍了 SQLAlchemy 的相关使用,包括增删改查操作以及创建表等内容。这些知识对于学习 Flask 和 Django 构建 Web 应用程序提供了坚实的基础。
通过掌握 SQLAlchemy,你可以更加灵活地操作数据库,轻松实现数据的持久化和查询。这为你开发功能丰富、可靠的 Web 应用程序提供了强大的工具和技术支持。
同时,理解 SQLAlchemy 的工作原理和核心概念,例如 ORM(对象关系映射)模式,可以帮助你更好地组织和管理应用程序的数据层。这样,你可以专注于业务逻辑的开发,而无需过多关注底层数据库的细节。
在未来的学习和实践中,你可以进一步探索 SQLAlchemy 的高级功能和技巧,如复杂查询、关联关系、事务处理等。这些深入的知识将使你能够构建更加灵活、高效的数据库驱动应用程序。
综上所述,通过本文中对 SQLAlchemy 的详细讲解,你已经打下了坚实的基础,为进一步学习和应用 Flask 和 Django 提供了有力的支持。继续努力学习和实践,相信你将在 Web 开发领域取得更大的成就。祝你在未来的学习和项目中取得成功!