【Linux】进程地址空间
文章目录
- C语言地址空间回顾
- 进程地址空间概念
- Linux是如何管理每个进程的地址空间?
- 为什么要有进程地址空间和页表?
- 页表的细节
C语言地址空间回顾
我们在讲C语言的时候,老师给大家画过这样的空间布局图
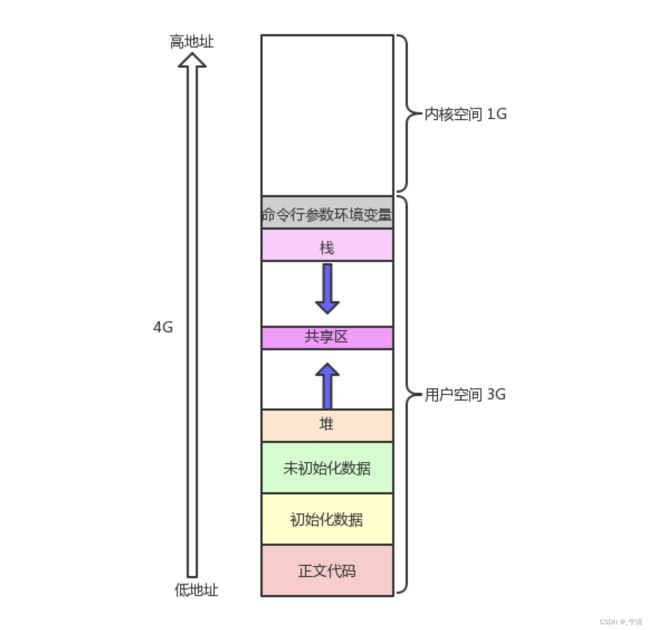
C/C++内存分布简图:
+------------------+ 高地址
| |
| 栈 | <- 本地变量,函数调用信息等
| |
+------------------+
| |
| 堆 | <- 动态分配的变量(malloc/new)
| |
+------------------+
| |
| 未初始化数据段 |
| (BSS 段) | <- 未初始化的静态和全局变量
| |
+------------------+
| |
| 已初始化数据段 | <- 已初始化的静态和全局变量
| (数据段) |
| |
+------------------+
| |
| 常量数据段 | <- 字面量,常量字符串等
| |
+------------------+
| |
| 代码段 | <- 程序代码(虚函数和普通函数)
| |
+------------------+ 低地址
可是我们对他并不理解,我们可能误把它理解为了实际物理地址!
[!Question] 为什么下面的代码中,同一个变量,同一个地址,内容却不同?
#include#include int main() { int data = 42; pid_t pid; pid = fork(); if (pid == -1) { // 错误处理 perror("fork"); return 1; } else if (pid == 0) { // 子进程 printf("I am a Child process: PID=%d, PPID=%d\n", getpid(), getppid()); // 修改子进程的数据 data = 84; printf("Child process: Modified data=%d ,address:%p\n", data, &data); } else { // 父进程 printf("I am a Parent process: PID=%d, Child PID=%d\n", getpid(), pid); // 父进程休眠等待子进程执行完毕 sleep(2); // 父进程访问未修改的数据 printf("Parent process: Original data=%d ,address:%p\n", data, &data); } return 0; } 运行结果:
答:因为子进程继承了父进程的虚拟地址空间,而不是物理地址空间。C语言中所谓地址不是实际物理地址,而是进程的虚拟地址空间里的地址。虚拟地址通过页表映射到物理地址。
写时拷贝机制在虚拟地址层面运作。

进程地址空间概念
实际上操作系统会给每一个进程都创建一个独立的虚拟地址空间,然后通过页表将虚拟地址空间与物理内存一一对应 (映射),我们用户只能得到虚拟地址空间中的虚拟地址,当我们修改虚拟地址中的数据时,操作系统会先通过页表找到对应的物理内存,然后修改物理内存中的数据。
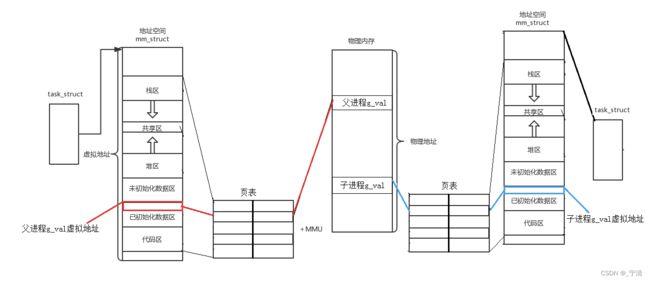
OS 为每个进程都创建独立的地址空间就相当于给每个进程都画了一张一样的"大饼",即告诉每个进程:“你享有计算机中的所有资源,整个系统内存都是你的,你快来用吧!” 而实际上,一旦某个进程申请的内存过大时,OS 会直接拒绝进程的请求。
Linux是如何管理每个进程的地址空间?
重提“管理”
- 管理的本质是对数据进行管理
- 管理的方法是先描述,再组织
所以,和管理进程一样,操作系统会使用一种内核数据结构来对地址空间进行管理,Linux中用于 管理地址空间的内核数据结构叫做 mm_struct,操作系统会为每个进程创建一个 mm_struct 对象,然后通过管理结构体对象来间接管理进程地址空间。

查看mm_struct的定义:
struct mm_struct
{
// ...
unsigned long total_vm, locked_vm, shared_vm, exec_vm;
unsigned long stack_vm, reserved_vm, def_flags, nr_ptes;
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
// ...
};
total_vm:可能表示虚拟内存的总量。locked_vm:可能表示被锁定,不能被换出的虚拟内存的数量。shared_vm:可能表示被多个进程共享的虚拟内存的数量。exec_vm:可能表示可执行的虚拟内存的数量。stack_vm:可能表示栈内存的虚拟内存的数量。reserved_vm:可能表示已预留但尚未使用的虚拟内存的数量。def_flags:可能表示默认的内存区域标志。nr_ptes:可能表示页表条目的数量。start_code,end_code:可能表示代码段的开始和结束位置。start_data,end_data:可能表示数据段的开始和结束位置。start_brk,brk:可能表示堆的开始位置和当前位置。start_stack:可能表示栈的开始位置。arg_start,arg_end:可能表示命令行参数的开始和结束位置。env_start,env_end:可能表示环境变量的开始和结束位置。
可以看到,进程地址空间其实也是进程属性的一种,我们可以通过进程的 task_struct 来找到/管理进程对应的地址空间。
为什么要有进程地址空间和页表?
- 因为有了进程地址空间和页表,物理内存空间上不连续、无序的空间就可以通过页表这一映射关系联系在一起,让进程以统一的视角看待内存。
- 有了进程地址空间和页表后,每个进程都认为自己在独占内存,这样能更好的保障进程的独立性以及合理使用内存空间(当实际需要使用内存空间的时候再在内存进行开辟),并能将进程管理与内存管理进行解耦合。
- 地址空间+页表的设计是保护内存安全的重要手段!
页表的细节
页表其实不光存放虚拟地址和物理内存地址,还有其他的属性,比如会存放权限属性。

我们平时写代码时常量不可修改究竟是谁决定的?
其实就是操作系统在页表中该数据的权限属性上放置的是’r’,当你要对该数据进行修改时(写入)时,首先需要进行虚拟地址与物理地址的转化,转化的过程中操作系统发现权限为只读,所以才不可修改不可写入。物理内存没有不可修改一说。
那const修饰的数据是不是也是由页表决定的呢?
不是!const与系统没有任何关系,const是编译器检查前后语法的问题。const的意义是将可能在未来运行时出现的错误提前在编译阶段发现并报错。所以我们说const能加则加,是一种好的编程习惯,防御性编程。