Python中的字符串
目录
1 字符串基础
1.1 声明字符
1.2 单、双引号
1.3 链接字符
1.4 三引号
1.5 转义字符
2 字符串遍历
2.1 字符串的拼接
2.2 获取字符串的索引
2.3 字符串的遍历
3 字符串常见操作
3.1 常见
3.1.1 format——格式化字符串
3.1.2 strip——剔除
3.1.3 count ——计数
编辑
3.2 切割与拼接
3.2.1 拼接
3.2.2 分隔
3.3 查找与替换
3.3.1 查找
3.3.2 替换
3.4 转换大小写
3.5 对齐
3.6 编码与解码
3.7 字符判断
3.8 开始和结尾
1 字符串基础
1.1 声明字符
可以使用单引号,也可以使用双引号
# 声明字符串
s0 = "hello world"
print(type(s0))
s1 = 'hello world'
print(type(s1))
1.2 单、双引号
若一行中要出现引号,单引号、双引号要搭配使用
# 假如字符串中有引号符号
s2 = "'i' am a girl"
print(s2)
s2 = '"i" am a girl'
print(s2)

1.3 链接字符
PEP8规范要求单行字符不超过120个字符,字符过多时,可以使用 “ \ ” 连接,打印后仍未同一行字符
# 使用\连接字符串
s3 = "abcdefg" \
"a2543153+-*/" \
".zbfzfbzdb!" \
"@##$" \
"%%^&&*()_"
print(s3)
1.4 三引号
(1)用于带格式的字符串
# 三引号打印带格式的字符串
s4 = """ this is china。
1235
4568
8963
"""
print( s4)
(2)用于文档注释或者类注释,一般放于开头,不输出任何东西。
"""
这里是文档注释
字符串是基本数据类型
str()可以将任意数据类型转换为字符串
单引号、双引号都可以声明字符串
三引号生命特殊格式字符串,以及文档注释,以及类注释
"""
(3)获取某模块的文档注释方法
例如:获取math模块的文档注释,
# 需要先导入模块
import math
# 获取random模块的文档注释
print(math.__doc__)输出如下图所示:

打开math模块的.py文件可以看到该模块的文档注释:

1.5 转义字符
转义字符 \ 会将后续内容转义
例如:输入网址:\\192.168.10.55
要想输出\符号,需要用到转义字符,告诉计算机这只是一个简单的符号
Python中“\n”表示换行,要想打印该字符就要用转义字符进行转移
其他有意义符号部分如下:
| \n | 换行符 |
| \t | 制表符 |
| \” |
双引号 |
| \' | 单引号 |
| \b | 退格键 |
# 转义字符\ 会将后续内容转义
s7 = "网盘的链接地址是 \\\\192.168.10.55"
print(s7)
s8 = "想要换行输入\\n就可以了"
print(s8)
s9 = "想要使用制表符输入\\t就可以了"
print(s9)
s10 = "想要输入双引号输入\"\"就可以了"
print(s10)
s11 = '想要输入单引号输入\'\'就可以了'
print(s11)
s12 = "哎呦喂奥恩"
print(s12)
2 字符串遍历
2.1 字符串的拼接
简单拼接,使用“ + ”号进行拼接,
字符串*数字 还可以输出多次该字符串
# 拼接
s0 = "hello"
s1 = "world"
s2 = s1 + s0
print(s2)
print(s2 * 3)
2.2 获取字符串的索引
(1)查看字符串的长度,及某个位置的字符
# 索引:下标
# 从首字符开始
s0 = "hello world"
print(len(s0))
# [0, len-1]
print(s0[0], s0[6], s0[10])

(2)若查看的位数超过字符的长度,会显示索引越界
![]()
2.3 字符串的遍历
(1)遍历字符串,使用for循环
# 遍历
input_str = input("输入字符串")
# 简单适合只是获取字符串内容
for c in input_str:
print(c)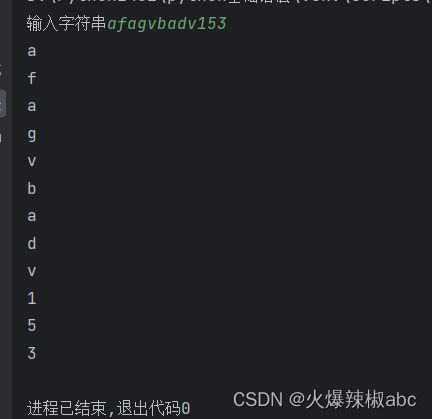
input_str = input("输入字符串")
for i in range(len(input_str)):
print(i, input_str[i])
小练习:输入一个字符串判断字符串是否对称
# abcdcba
s = input("输入字符串")
# 获取字符串的长度整除2 只需判断一般就可以知道是否对称
# 整除是因为奇数的话最中间的数不用看
for i in range(len(s) // 2):
if s[i] != s[len(s)-1-i]:
break
else:
print("是")3 字符串常见操作
3.1 常见
3.1.1 format——格式化字符串
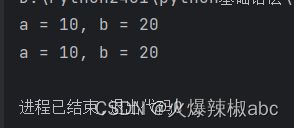
a = 10
b = 20
print(f"a = {a}, b = {b}")
# 格式化字符串 默认按照顺序赋值 也可以指定参数位置
print("a = {}, b = {}".format(a, b))
3.1.2 strip——剔除
默认剔除空格,也可以指定剔除字符
print(" 你好 ".strip())
print("****你好=====".lstrip("*"))
print("****你好=====".rstrip("="))
3.1.3 count ——计数
统计字符串出现次数, 默认到结尾,也可指定开始 和 结束位置
print("123123123123123".count("123"))
print("123123123123123".count("123", 3, 9))
3.2 切割与拼接
3.2.1 拼接
使用指定的字符串将可迭代(使用for循环遍历)内容拼接
print("+".join("hello world"))
print("+".join(["1", "2", "3", "4", "5"]))
3.2.2 分隔
# 分隔
print("中华人民共和国合同法".split("共"))
3.3 查找与替换
3.3.1 查找
(1)find
返回该字符出现位置,可以指定查找起始位置和最后位置
print("123123123123".find("2"))
print("123123123123".find("123", 5, 9))
print("123123123123".rfind("123", 5, 9))

(2)index
类似于find,但是若查找不到会报错
# 类似find找不到直接报错
print("23123123123123".index("123"))
print("23123123123123".rindex("123", 2))
3.3.2 替换
3.4 转换大小写
# 首字母大写
print("hello world".capitalize())
# 全部大写
print("hello world".upper())
# 全部小写
print("ABCDEFG".lower())
# 大小写切换
print("AaBbCcDd".swapcase())
# 每个单词首字母都大写
print("hello world".title())
3.5 对齐
在指定宽度下居中 默认使用空格也可以指定字符
# 在指定宽度下居中 默认使用空格也可以指定字符
print("登录".center(20, "*"))
# 居左
print("登录".ljust(20, "*"))
# 居右
print("登录".rjust(20, "*"))
# 居右填充0
print("登录".zfill(20))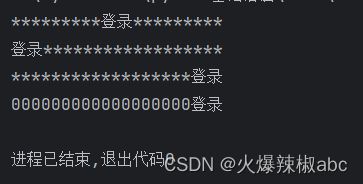
3.6 编码与解码
# encode编码
print("中国".encode())
str_encode = "中国".encode()
print(str_encode)
# decode解码
print(str_encode.decode())
3.7 字符判断
# 是否全是字母
print("print".isalpha())
# 是否全是数字
print("123".isnumeric())
# 是否是数字或字母
print("123sdv".isalnum())
3.8 开始和结尾
# startswith 开始 endswith 结束
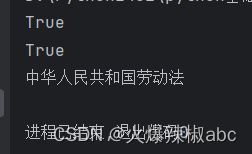
print("中华人民共和国合同法".endswith("合同法"))
print("中华人民共和国合同法".startswith("中"))
print("中华人民共和国合同法".replace("合同法", "劳动法"))