决策树在商业保险中的应用
决策树在商业保险中的应用
- 决策树在商业保险中的应用
-
- ⼀、业务背景
- 二、数据探索性分析
-
- 2.1、导入数据和安装包
- 2.2了解数据特征的分布情况
- 2.3了解数据特征与标签之间的相关性强弱
- 三、数据清洗
-
- 3.1 删除不需要的列
- 3.2 拆分训练集和测试集
- 3.3 空值填充
-
- 3.3.1 对训练集数据进行填补
- 3.3.1 对测试集数据进行填补
- 3.4 数据编码
- 四、建立决策树模型
-
- 4.1没有进行任何参数设置的决策树模型
- 4.2调参
-
- 4.1学习曲线对单个参数进行调参
- 4.2网格搜索对多个参数进行调参
决策树在商业保险中的应用
⼀、业务背景
- 业务环境
1.概览
受保险⾏业结构转型时期影响,互联⽹保险整体发展受阻,2018年⾏业保费收⼊为1889亿元, 较去年基本持平,不同险种发展呈现分化格局,其中健康险增⻓迅猛,2018年同⽐增⻓108%,主要由短期医疗险驱动。
格局
供给端专业互联⽹保险公司增⻓迅速,但过⾼的固定成本及渠道费⽤使得其盈利问题凸显,加上发展现状强,⾃营渠道建设及科技输出是未来的破局⽅法,渠道端形成第三⽅平台为主,官⽹为辅的格局,第三⽅平台逐渐发展出B2C、B2A、B2B2C等多种创新业务模式。
模式
互联⽹保险不仅仅局限于渠道创新,其核⼼优势同样体现在产品设计的创新和服务体验的提升。 - 发展趋势
竞合格局
随着⼊局企业增多,流量争夺更加激烈,最终保险公司与第三⽅平台深度合作将成为常态。
保险科技
当前沿科技不断应⽤于保险⾏业,互联⽹保险的概念将会与保险科技概念⾼度融合。 - 衡量指标

- 业务⽬标
针对保险公司的健康险产品的⽤户,制作⽤户画像,然后进⾏精准保险营销。
5.数据分析的流程
1 读入数据
1.1 了解数据
2 了解我们的特征
3 探索特征和响应数据之间的比例关系
4 数据清洗
4.1 删除不需要的列
4.2 拆分训练集和测试集
4.3 空值统计
4.4 空值填充
4.5 数据编码
4.6 测试集相同编码方式
4.7 重复值检查和删除
5 建模
5.1 调参
5.2 网格搜索
二、数据探索性分析
2.1、导入数据和安装包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv("保险行业决策树案例\data\ma_resp_data_temp.csv")
df.head()
df.shape
df.info()

![]()
在我们正式建模型之前,我们需要对我们的数据进行描述性统计,这样我们就能知道整个数据的大致分布是什么样的,做到心里有数,然后能够数据大致的全貌有一定的了解。
2.2了解数据特征的分布情况
def value_counts(column):
"""函数功能: 传入列名, 返回该列的计数统计
绘制柱状图"""
df[column].value_counts().plot(kind='bar');
return df[column].value_counts()
#查看购买保险人数
value_counts("resp_flag")

#查看性别分布
value_counts("GEND")
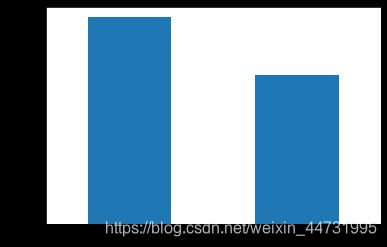
#查看是否大学毕业分布
value_counts("COLLEGE")

2.3了解数据特征与标签之间的相关性强弱
1.了解每一个学历下购买的人数占比情况
d = df.groupby("c210mys")["resp_flag"].mean()
plt.figure(dpi = 100)
d.plot(kind = "bar")
plt.xlabel("学历")
plt.ylabel("每一学历购买保险的占比")
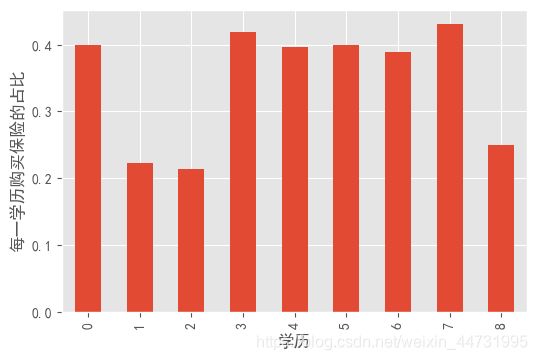
从图中可以看到学历等级的高低与购买保险并无太多相关性
2.了解社会经济评分购买保险的人数占比情况
plt.figure(dpi =500)
df.groupby("c210kses")["resp_flag"].count().plot(kind = "kde")

从概率密度曲线图可以得出,购买保险人数最多的主要集中在社会经济地位评分-100至500分左右。
3.家庭排名与购买保险之间的相关性
plt.figure(dpi = 100)
df.groupby("zhip19")["resp_flag"].mean().plot(kind = "bar")
plt.xlabel("家庭排名")
plt.ylabel("家庭排名购买保险的占比")

同样也并无很多相关性的关系。
对数据有了基本的了解后,接下来,我们对数据进行清洗。
三、数据清洗
数据的清洗流程
1、删除不需要的列
2、拆分训练集和测试集
3、空值填充
4、数据编码
5、重复值检查, 重复值删除
6、离散化(连续数据,年龄, 65-70, 71-75, 76-80…)
3.1 删除不需要的列
#KBM_INDV_ID, NAH19, N65P, U18,
df.drop(columns=['KBM_INDV_ID', 'NAH19', 'N65P', 'U18'],
inplace=True)
# 拆分X, y
y = df.pop('resp_flag')
y
# 复制一个新的作为X
X = df.copy()
3.2 拆分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=100)
3.3 空值填充
#统计空值数量
X_train.isnull().sum()
#只看空值部位0的即可
null = X_train.isnull().sum()
#过滤出有空值的列, 从多到少排序
null[null>0].sort_values(ascending=False)
temp = X_train[null[null>0].sort_values(ascending=False).index]
temp
因为列名的个数太多,一个一个填充的话太费时间了,因此我们要对其进行批量的填充。
思路:对于objct型的数据我们可以采用众数进行填充,对于float类型的数据我们可以采用中位数进行填充。我们首先可以将我们所需要填充的列的数据类型分为两类,一类是objct型的,一类是float型的,然后通过select_dtypes这个函数筛选出两个类型的数据,对它们进行批量的填充。
查看有缺失值的数据类型
temp.info()

value_counts(“LIVEWELL”)

我们注意到LIVEWELL幸福水平应该是属于objct型的,但是在原始数据中它是float型的,因此我
们需要对其更改数据类型将其转化成objct型的。
#先把LIVEWELL改成object型
temp.LIVEWELL = temp.LIVEWELL.astype('object')
#根据类型筛选数据
#include= 提取的类型, exclude=排除类型
#这些列名就是所有我们需要用中位数填充的列
temp.select_dtypes(include='float64').columns
#筛选出不是float64的列, 就是我们需要用众数填充的
temp.select_dtypes(exclude='float64').columns
#保存成变量
float64_type = temp.select_dtypes(include='float64').columns
object_type = temp.select_dtypes(exclude='float64').columns
3.3.1 对训练集数据进行填补
# 填充所有离散型的用众数的
for column in object_type:
# 采用每一列的众数填充这一列
X_train[column].fillna(X_train[column].mode()[0],
inplace=True)
# 填充所有连续型的用中位数
for column in float64_type:
#print(column)
# 对每一列采用这一列的中位数填充
X_train[column].fillna( X_train[column].median(),
inplace=True)
3.3.1 对测试集数据进行填补
# 填充所有连续型的用中位数
for column in float64_type:
# 对每一列采用这一列的中位数填充
X_test[column].fillna( X_train[column].median(),
inplace=True)
# 填充所有离散型的用众数的
for column in object_type:
# 采用每一列的众数填充这一列
X_test[column].fillna(X_train[column].mode()[0],
inplace=True)
填充完后,现在我们要对数据进行编码。
刚才我们将LIVEWELL转化成了objct型的,但是我们知道幸福水平是有大小之分的,填充完空值之后,因此我们需要将LIVEWELL转化成整数型
# LIVEWELL 改成整数型
X_train.LIVEWELL= X_train.LIVEWELL.astype('int')
X_test.LIVEWELL= X_test.LIVEWELL.astype('int')
空值填补完成后,接下来我们对数据进行编码
3.4 数据编码
将所有object类型分成2分类的和多分类.
思路:对于object类型的我们也是通过批量来对数据进行编码,因此我们需要对每一列进行去重
然后,查看每一列的分类数目。然后对其采用for循环进行批量的更改数据类型。
# 提取所有object数据类型
X_train_object = X_train.select_dtypes('object')
X_train_object
# 将统计结果保存到一个Series中,
# 索引是列名, 值就是及分类
t = pd.Series() # 空的
for column in X_train_object.columns:
# 添加一条数据
t[column] = X_train[column].nunique()
t
# 为了防止弄错, 先备份一个
X_train_copy = X_train.copy()
X_test_copy = X_test.copy()
对训练集进行编码
t[t==2].index # 对这些列进行遍历, 编码
# 编码
d = {'N':0, 'Y':1, 'M':0, 'F':1}
for column in t[t==2].index:
# 对所有2分类列进行编码
X_train[column].replace(d, inplace=True)
# 完成多分类的编码
for column in t[t>2].index:
# 构建一个列的修改字典
d = {}
for i in range(len(X_train[column].unique())):
d[X_train[column].unique()[i]] = i
# 替换
X_train[column].replace(d, inplace=True)
```bash
对测试集进行编码
# 编码
d = {'N':0, 'Y':1, 'M':0, 'F':1}
for column in t[t==2].index:
# 对所有2分类列进行编码
X_test[column].replace(d, inplace=True)
> # 完成多分类的编码 for column in t[t>2].index:
> # 构建一个列的修改字典
> d = {}
> for i in range(len(X_test[column].unique())):
> d[X_test[column].unique()[i]] = i
> # 替换
> X_test[column].replace(d, inplace=True) ```
编码完成之后然后我们对数据进行去重
# 没有完全一样的重复值存在
X_train[X_train.duplicated(keep=False)]
X_test[X_test.duplicated(keep=False)]
对数据进行编码完成后,接下来我们对数据建立决策树模型
四、建立决策树模型
4.1没有进行任何参数设置的决策树模型
#导包
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
clf= DecisionTreeClassifier()
clf.fit(X_train,y_train)
clf.score(X_train,y_train)

clf.score(X_test,y_test)

clf.get_depth()

这是没有进行任何调参后得到的决策树模型分类准确率
接下来我们对该模型进行调参
4.2调参
4.1学习曲线对单个参数进行调参
选择最大深度max_depth 进行调参
test_score = []
train_score = []
cv_score = []
for i in range(2,42):
dtc = DecisionTreeClassifier(max_depth=i,random_state=100)
dtc.fit(X_train,y_train)
cv_score.append(cross_val_score(dtc,X_train,y_train,cv = 5,n_jobs = -1).mean())
train_score.append(dtc.score(X_train,y_train))
test_score.append(dtc.score(X_test,y_test))
plt.figure(dpi = 150)
plt.plot(range(2,42),test_score,label = "test_score")
plt.plot(range(2,42),train_score,label = "train_score")
plt.plot(range(2,42),cv_score,label = "cv_score ")
plt.legend()
plt.show()

print("最优分数为:{}".format(np.max(cv_score)),"最优深度:{}".format(np.argmax(cv_score)+2))
![]()
4.2网格搜索对多个参数进行调参
dd = {'max_depth':range(3, 10),
'max_features':['sqrt', 'log2', None],
'max_leaf_nodes':range(20, 100, 5)}
grid = GridSearchCV(dtc,dd, n_jobs=-1, cv=5,
verbose=10)
grid.fit(X_train, y_train)
grid.best_score_

grid.best_params_

grid.score(X_train, y_train)

grid.score(X_test, y_test)

注:业务的应用在此不方便透露,如想知道请在下方进行留言,本人收到回立即回复。