《从青铜学到王者》Python工程师之Python基础函数
每天妹子看一遍,学到凌晨都不厌
一、输入输出函数
1、print()函数
输出函数
向屏幕输出指定的汉字
print("hello world")
1
print()函数可以同时输出多个字符串,用逗号“,”隔开
print("hello","how","are","you")
1
print()会依次打印每个字符串,遇到逗号“,”会输出空格,输出的内容是这样的:
hello how are you
1
print()可以打印整数,或者计算结果
>>>print(300)
300
>>>print(100 + 200)
300
1234
我们也可以把打印的结果显示的再漂亮一些
>>>print("100 + 200 =", 100 + 200)
100 + 200 = 300
12
注意:对于字符串"100 + 200 ="它会原样输出,但是对于100+200,python解释器自动计算出结果为300,因此会打印出上述的结果。
字符串相加,进行字符串的连接,且不产生空格
print("hello","你好")
# 使用”,“进行连接
print("he" + "llo")
# 字符串相加,进行字符串的连接,且不产生空格
print(10+30)
# 没有使用引号括起来,默认为数值,若是使用引号括起来,就是字符串
# 若是数值使用加号连接,默认是表达式进行计算,返回计算的结果
print("hello"+1) #会报错
# 不同类型的数据不能使用加号连接
# 不同类型的数据能够使用”,“进行连接
print("1 2 3",2+3)
# 输入
# input()
# 带有提示信息的输入
# name = input("请输入您的姓名:")
# print(name)
1234567891011121314151617181920
python中print之后是默认换行的
要实现不换行要加end参数表明
n = 0
while n <= 100:
print("n =",n,end=' ')
if n == 20:
break
n += 1
输出:
n = 0 n = 1 n = 2 n = 3 n = 4 n = 5 n = 6 n = 7 n = 8 n = 9 n = 10 n = 11 n = 12 n = 13 n = 14 n = 15 n = 16 n = 17 n = 18 n = 19 n = 20
123456789
多个数值进行比较
print('c'>'b'>'a')
print(5>1>2)
输出:
True
False
12345
2、input()函数
输入函数
Python提供了一个input()函数,可以让用户输入字符串,并且存放在变量中,比如输入用户名
>>> name = input()
jean
12
如何查看输入的内容:
>>> name
'jean'
12
或者使用:
>>> print(name)
jean
12
当然,有时候需要友好的提示一下,我们也可以这样做:
>>> name = input("place enter your name")
place input your name jean
>>> print("hello,", name)
hello, jean
1234
二、进制转换函数
1、bin(),oct(),hex()进制转换函数(带前缀)
使用bin(),oct(),hex()进行转换的时候的返回值均为字符串,且带有0b, 0o, 0x前缀.
十进制转换为二进制
>>> bin(10)
'0b1010'
12
十进制转为八进制
>>> oct(12)
'014'
12
十进制转为十六进制
>>> hex(12)
'0xc'
12
2、’{0:b/o/x}’.format()进制转换函数(不带前缀)
十进制转换为二进制
>>>'{0:b}'.format(10)
'1010'
12
十进制转为八进制
>>> '{0:o}'.format(12)
'14'
12
十进制转为十六进制
>>> '{0:x}'.format(12)
'c'
12
注意:hex函数比格式化字符串函数format慢,不推荐使用.
3、int(’’,2/8/16)转化为十进制函数(不带前缀)
二进制转为十进制
>>> int('1010',2)
10
12
八进制转为十进制
>>> int('014', 8)
12
12
十六进制转十进制
>>> int('0xc',16)
12
12
4、’{0:d}’.format()进制转换为十进制函数
二进制转十进制
>>> '{0:d}'.format(0b11)
'3'
12
八进制转十进制
>>> '{0:d}'.format(0o14)
'12'
12
十六进制转十进制
>>> '{0:d}'.format(0x1f)
'31'
12
5、eval()进制转为十进制函数
二进制转十进制
>>> eval('0b11')
'3'
12
八进制转十进制
>>> eval('0o14')
'12'
12
十六进制转十进制
>>> eval('0x1f')
'31'
12
注意:eval函数比int函数慢,不推荐使用
二进制, 十六进制以及八进制之间的转换,可以借助十进制这个中间值,即先转十进制再转其他的进制,也可以直接使用函数进制转换.
#借助十进制
>>> bin(int('fc',16))
'0b11111100'
#利用函数直接转
>>> bin(0xa)
'0b1010'
>>> oct(0xa)
'012'
>>> hex(10)
'0xa'
12345678910
三、求数据类型函数
1、type()
n = "hello world"
n = type(n)
print(n)
输出:
<class 'str'>
12345
2、使用type()判断变量的类型
# int float str bool tuple list dict set
str1 = 'ss'
if type(num) == str:
print('yes')
输出:
yes
123456
str1 = 'ss'
print(isinstance(str1,str))
输出:
True
1234
推荐使用isinstance()
3、isinstance()
功能:判断变量是否属于某一数据类型,可以判断子类是否属于父类。
class A():
pass
class B(A):
def __init__(self):
super(B, self).__init__()
pass
class C(A):
def __init__(self):
A.__init__(self)
n = 0.1
print(isinstance(n,(int,float,str)))
print(isinstance(n,int))
print(isinstance(A,object))
b = B()
print(isinstance(b,A))
c =C()
print(isinstance(c,B))
输出:
True
False
True
True
False
12345678910111213141516171819202122232425
四、关键字函数
1、keyword.kwlist()函数
查看关键字 :
import keyword
print(keyword.kwlist)
输出:
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
12345
五、删除变量/对象函数
1、del() 函数
变量一旦删除,就不能引用,否则会报错
用法1
n = "hello world"
print(n)
del n
123
用法2
n = "hello world"
print(n)
del(n)
print(n)
输出:
hello world
NameError: name 'n' is not defined
1234567
六、数学函数
1、abs(num) 返回num的绝对值
print(abs(-3))
输出:
3
123
2、max(num1,num2,…,numn) 返回给定参数的最大值
num1 = 10
num2 = 20
print(num1 > num2)
print(max(num1,num2,56))
输出:
False
56
12345678
3、min(num1,num2,…,numn) :返回给定参数的最小值
print(min(12,3,34,0))
输出:
0
123
4、pow(x,y) : 求x的y次方,x^y
print(pow(2,3))
输出:
8
123
5、round(num,n) : 四舍五入,
参数一:需要进行四舍五入的数据;
参数二:保留小数的位数。若n不写,默认为0
print(round(123.486,2))
输出:
123.49
1234
6、range()函数
range([start,] stop [,step])
实质:创建了一个可迭代对象;一般情况下与for循环一起连用
1、start 可以不写,默认值是0,若给定则从start开始
2、stop 必须给定;
3、取值范围[start,stop)
4、step:步长,若不给则默认为1
'''
需求:使用for循环计算1*2*3...*20的值
'''
accou = 1
for i in range(1,21):
accou *= i
print(accou)
输出:
2432902008176640000
123456789
七、字符串函数
1、eval(str)函数
功能:将字符串转成有效的表达式来求值或者计算结果
可以将字符串转化成列表list,元组tuple,字典dict,集合set
注意:生成了一个新的字符串,没有改变原本的字符串
# 12-3 --> 9
str1 = "12-3"
print(eval(str1))
print(str1)
print(eval("[1,2,3,4]"))
print(type(eval("[1,2,3,4]")))
print(eval("(1,2,3,4)"))
print(eval('{1:1,2:2,3:3}'))
print(eval('{2,3,5,3}'))
输出:
9
12-3
[1, 2, 3, 4]
<class 'list'>
(1, 2, 3, 4)
{1: 1, 2: 2, 3: 3}
{2, 3, 5}
1234567891011121314151617
2、len(str)函数
功能:获取字符串长度
str1 = "you are good man"
print(len(str1))
输出:
16
1234
3、str.lower()函数
功能:返回一个字符串中大写字母转化成小写字母的字符串
注意:生成了一个新的字符串,没有改变原本的字符串
str1 = "You are good Man"
print(str1.lower())
print(str1)
输出:
you are good man
You are good Man
123456
4、str.upper()函数
功能:返回一个字符串中小写字母转化成大写字母的字符串
注意:生成了一个新的字符串,没有改变原本的字符串
str1 = "You are good man"
print(str1.upper())
print(str1)
输出:
YOU ARE GOOD MAN
You are good man
123456
5、str.swapcase()函数
功能:返回字符串中的大写字母转小写,小写字母转大写的字符串
注意:生成了一个新的字符串,没有改变原本的字符串
str1 = "You are Good man"
print(str1.swapcase())
print(str1)
输出:
yOU ARE gOOD MAN
You are Good man
123456
6、str.capitalize()函数
功能:返回字符串中的首字母大写,其余小写的字符串
注意:生成了一个新的字符串,没有改变原本的字符串
tr1 = "you Are good man"
print(str1.capitalize())
print(str1)
str2 = "You are a good Man"
print(str2.capitalize())
输出:
You are good man
you Are good man
12345678
7、str.title()函数
功能:返回一个每个单词首字母都大写的字符串
注意:生成了一个新的字符串,没有改变原本的字符串
str1 = "you Are good man"
print(str1.title())
print(str1)
str2 = "You are a good Man"
print(str2.title())
输出:
You Are Good Man
you Are good man
You Are A Good Man
123456789
8、str.center(width[,fillchar])函数
功能:返回一个指定宽度的居中字符串
参数一:指定的参数【必须有】
参数二:fillchar填充的字符,若未指定,则默认使用空格
注意:生成了一个新的字符串,没有改变原本的字符串
str1 = "you Are good man"
print(str1.center(20,"*"))
print(str1)
输出:
you Are good man
**you Are good man**
you Are good man
1234567
9、str.ljust(width[,fillchar])函数
功能:返回一个指定宽度左对齐的字符串
参数一:指定字符串的宽度【必须有】
参数二:填充的字符,若不写则默认为空格
注意:生成了一个新的字符串,没有改变原本的字符串
str1 = "you Are good man"
print(str1.ljust(20,"*"))
print(str1)
输出:
you Are good man****
you Are good man
123456
10、str.rjust(width[,fillchar])函数
功能:返回一个指定宽度右对齐的字符串
参数一:指定字符串的宽度【必须有】
参数二:填充的字符,若不写则默认为空格
注意:生成了一个新的字符串,没有改变原本的字符串
str1 = "you Are good man"
print(str1.rjust(20,"*"))
print(str1)
输出:
****you Are good man
you Are good man
123456
11、str.zfill(width)函数
功能:返回一个长度为width的字符串,原字符右对齐,前面补0
注意:生成了一个新的字符串,没有改变原本的字符串
str1 = "you Are good man"
print(str1.zfill(20))
print(str1)
输出:
0000you Are good man
12345
12、str2.count(str1,start,end])函数
功能:返回str1在str2中出现的次数,可以指定一个范围,若不指定则默认查找整个字符串
区分大小写
注意:生成了一个新的字符串,没有改变原本的字符串
str1 = "hello"
str2 = "Hello hello1 Hello2 hi haha helloa Are good man"
print(str2.count(str1,0,20))
输出:
1
12345
13、str2.find(str1,start,end)函数
功能:从左往右检测str2,返回str1第一次出现在str2中的下标
若找不到则返回-1,可以指定查询的范围,若不指定则默认查询整个字符串
注意:生成了一个新的字符串,没有改变原本的字符串
str1 = "hello"
str2 = "Hello hello1 Hello2 hi haha helloa Are good man"
print(str2.find(str1,5,20))
输出:
6
12345
14、str2.rfind(str1,start,end)函数
功能:从右往左检测str2,返回str1第一次出现在str2中的小标,若找不到则返回-1,可以指定查询的范围,若不指定则默认查询整个字符串
注意:生成了一个新的字符串,没有改变原本的字符串
str1 = "hello"
str2 = "Hello hello1 Hello2 hi haha helloa Are good man"
print(str2.rfind(str1,10,35))
输出;
28
12345
15、str2.index(str1,start,end)函数
功能:和find()一样,不同的是若找不到str1,则会报异常
ValueError:substring not found
注意:生成了一个新的字符串,没有改变原本的字符串
str1 = "hello"
str2 = "Hello hello1 Hello2 hi haha helloa Are good man"
print(str2.index(str1,2,25))
print(str2.index(str1,24,25))
输出:
6
ValueError: substring not found
1234567
16、str.lstrip(char)函数
功能:返回一个截掉字符串左侧指定的字符,若不给参数则默认截掉空字符: \n \r \t 空格
注意:生成了一个新的字符串,没有改变原本的字符串
str3 = " \n\r \t ni hao ma"
print(str3)
print(str3.lstrip())
str4 = "****ni hao ma****"
print(str4.lstrip('*'))
输出;
ni hao ma
ni hao ma
ni hao ma****
123456789
17、str.rstrip()函数
功能:返回一个截掉字符串右侧指定的字符,若不给参数则默认截掉空字符: \n \r \t 空格
注意:生成了一个新的字符串,没有改变原本的字符串
str3 = " ni hao ma \n\r \t"
print(str3.rstrip())
str4 = "****ni hao ma****"
print(str4.rstrip('*'))
输出:
ni hao ma
****ni hao ma
1234567
18、str2.split(str1,num) 分离字符串
功能:返回一个列表,列表的元素是以str1作为分隔符对str2进行切片,
若num有指定值,则切num次,列表元素个数为num+1
若不指定则全部进行切片
若str1不指定,则默认为空字符(空格、换行\n、回车\r、制表\t)
注意:生成了一个新的字符串,没有改变原本的字符串
str2 = "22hello nihao hi hello haha ello2 hello3 hello"
print(str2.split(' ',3))
str3 = "[email protected]"
print(str3.split('@'))
list1 = str3.split('@')
print(list1[1].split('.'))
输出:
['22hello', 'nihao', 'hi', 'hello haha ello2 hello3 hello']
['1257309054', 'qq.com']
['qq', 'com']
12345678910
19、str2.splitlines()
功能:返回一个列表,列表的元素是以换行为分隔符,对str2进行切片
注意:生成了一个新的字符串,没有改变原本的字符串
str2 = '''
22
23
hello
'''
print(str2.splitlines())
输出:
['', '22', ' 23', ' hello']
12345678
20、str1.join(seq)函数 字符串连接
功能:以指定字符串作为分隔符,将seq中的所有元素合并成为一个新的字符串
seq:list、tuple、string
list1 = ["hello","nihao"]
print(" ".join(list1))
输出:
hello nihao
1234
str1 = "how are you , i am fine thank you"
str3 = "*".join(str1)
print(str3)
输出:
h*o*w* *a*r*e* *y*o*u* *,* *i* *a*m* *f*i*n*e* *t*h*a*n*k* *y*o*u
12345
21、ord() 求字符的ASCLL码值函数
print(ord("a"))
输出:
97
123
22、chr() 数字转为对应的ASCLL码函数
print(chr(97))
输出:
a
123
23、 max(str) min(str)获取最大最小字符
**max(str) **功能: 返回字符串str中最大的字母
str1 = "how are you , i am fine thank you"
print(max(str1))
输出:
y
1234
min(str) 功能:返回字符串str中最小字母
str1 = "how are you , i am fine thank you"
print(min(str1))
输出:
' '
1234
24、str.replace(old , new [, count]) 字符串的替换
str.replace(old , new [, count])
功能:使用新字符串替换旧字符串,若不指定count,则默认全部替换,
若指定count,则替换前count个
str1 = "you are a good man"
print(str1.replace("good","nice"))
输出:
you are a nice man
1234
25、字符串映射替换
参数一:要转换的字符 参数二:目标字符
dic = str.maketrans(oldstr, newstr)
str2.translate(dic)
str1 = "you are a good man"
dic = str1.maketrans("ya","32")
print(str1.translate(dic))
结果:
3ou 2re 2 good m2n
12345
26、str.startswith(str1,start.end) 判断字符串的开头
str.startswith(str1,start.end)
功能:判断在指定的范围内字符串str是否以str1开头,若是就返回True,否则返回False
若不指定start,则start默认从开始,
若不指定end,则默认到字符串结尾
str1 = "hello man"
print(str1.startswith("h",0,6))
输出:
True
1234
27、str.endswith(str1,start.end) 判断字符串的结尾
str.endswith(str1,start.end)
功能:判断在指定的范围内字符串str是否以str结束,若是就返回True,否则返回False
若不指定start,则start默认从开始,
若不指定end,则默认到字符串结尾
str1 = "hello man"
print(str1.endswith("man"))
输出:
True
1234
28、str.encode(编码格式)
对字符串进行编码 默认是utf-8
编码:str.encode()
解码:str.encode().decode()
注意:encode()的编码格式与decode()的编码格式必须保持一致
str4 = "你好吗"
print(str4.encode())
print(str4.encode().decode())
print(str4.encode("gbk"))
print(str4.encode("gbk").decode("gbk"))
输出:
b'\xe4\xbd\xa0\xe5\xa5\xbd\xe5\x90\x97'
你好吗
b'\xc4\xe3\xba\xc3\xc2\xf0'
你好吗
12345678910
29、str1.isalpha() 字符串为字母
功能:判断字符串【至少含有一个字符】中的所有的字符是否都是字母【a~z A~Z 汉字】
若符合条件则返回True,否则返回False
str5 = "hello你二"
print(str5.isalpha())
str5 = "hello "
print(str5.isalpha())
输出:
True
False
1234567
30、str5.isalnum()
功能:判断字符串【至少含有一个字符】中的所有字符都是字母或者数字【09,Az,中文】
str5 = "helloA标红"
print(str5.isalnum())
print("12aaa".isalnum())
print("aaa".isalnum())
print(" 111".isalnum())
print("111".isalnum())
print("$$%%qwqw11".isalnum())
print("你好".isalnum())
print( "IV".isalnum())
print('Ⅳ'.isalnum())
输出;
True
True
True
False
True
False
True
True
True
1234567891011121314151617181920
31、str.isupper()
功能:判断字符串中所有字符是不是大写字符
print("WWW".isupper())
print("wWW".isupper())
print("123".isupper())
print("一二三".isupper())
输出;
True
False
False
False
123456789
31、str.islower()
功能:判断字符串中所有字符是不是小写字符
print("WWW".islower())
print("wWW".islower())
print("123".islower())
print("一二三".islower())
print("qwww".islower())
输出:
False
False
False
False
True
1234567891011
32、str.istitle()
功能:判断字符串是否是标题化字符串【每个首字母大写】
print("U Wss".istitle())
print("wWW ".istitle())
print("123 ".istitle())
print("一二三".istitle())
print("qwww".istitle())
输出:
True
False
False
False
False
1234567891011
33、 str.isdigit()
isdigit()
True: Unicode数字,byte数字(单字节),全角数字(双字节)
False: 汉字数字, ,罗马数字
Error: 无
print("123".isdigit())
print("123".isdigit())
print(b"1".isdigit())
print("Ⅳ".isdigit())
print("123.34".isdigit())
print("一".isdigit())
输出;
True
True
True
False
False
False
12345678910111213
34、str.isspace()
功能:判断字符串中是否只含有空格
print("ddd".isspace())
print("".isspace())
print("a ddd".isspace())
print(" aaa".isspace())
print(" ".isspace())
输出;
False
False
False
False
True
1234567891011
35、str.isnumeric()
功能:若字符串中只包含数字字符,则返回True,否则返回False
isnumeric() True: Unicode数字,全角数字(双字节),汉字数字 False: 罗马数字, Error: byte数字(单字节) 1234
36、str.isdecimal()
功能:检查字符串是否只包含十进制字符【0,9】,如果是返回True,否则返回False
isdecimal() True: Unicode数字,,全角数字(双字节), False: 罗马数字,汉字数字 Error: byte数字(单字节) 1234
print("123".isdecimal())
print("123z".isdecimal())
#结果
True
False
12345
八、list列表函数
1、list.append(元素)
功能:在列表末尾添加新的元素,只要是python中的数据类型都可以添加,如列表,元组、字典等
list1 = [1,2,3,4]
list2 = ["good","nice","beautiful"]
list1.append("hello")
print(list1)
list1.append(list2)
print(list1)
输出:
[1, 2, 3, 4, 'hello', ['good', 'nice', 'beautiful']]
123456789
2、list1.extend()
功能:在列表的末尾一次性追加另一个列表中的多个值
注意:extend()中的值,只能是列表、元组、字符串、字典(可迭代的对象)
123
2、list1.extend()
功能:在列表的末尾一次性追加另一个列表中的多个值
注意:extend()中的值,只能是列表、元组、字符串、字典(可迭代的对象)
list1 = [1,2,3,4]
list2 = ["good","nice","beautiful"]
list1.extend(list2)
print(list1)
list1.extend({'h':2,'e':3})
print(list1)
输出:
[1, 2, 3, 4, 'good', 'nice', 'beautiful']
[1, 2, 3, 4, 'good', 'nice', 'beautiful', 'h', 'e']
12345678910
什么时候使用append,什么时候用extend?
当我们需要在原本的列表中追加像number类型后者Boolean类型的时候,
可以使用append,
或者是我们需要把另外一个列表当成一个元素追加到原本的列表中去的时候,
这时候也可以使用append
当我们需要在原本的列表中插入一个新的列表中的所有的元素的时候,
这时候我们需要使用extend
12345678
3、str.insert(下标值,object)
功能:在下标处插入元素,不覆盖原本的数据,原数据向后顺延
它与append非常类似,不同之处:append默认把新的元素添加在列表的末尾
而insert可以指定位置进行添加【插入】
list1 = [1,2,3,4]
list2 = ["good","nice","beautiful"]
list1.insert(0,list2)
print(list1)
输出:
[['good', 'nice', 'beautiful'], 1, 2, 3, 4]
1234567
4、list.pop()
功能:移除列表最后一个元素,并且返回移除元素的值
list.pop(index)
index:下标值
功能:移除指定下标处的元素,并且返回移除元素的值
注意:pop一次,list元素个数减1,index的取值为[0,len(list)),若超出取值范围则会报错
IndexError: pop index out of range
list2 = ["good","nice","beautiful"]
list2.pop()
print(list2)
list1 = [1,2,3,4]
list2.pop(0)
print(list2)
list2.extend(list1)
print(list2)
输出:
['good', 'nice']
['nice']
['nice', 1, 2, 3, 4]
12345678910111213
5、list.remove(元素)
功能:移除列表中指定元素的第一个匹配成功的结果
没有返回值
list2 = [2,"good","nice","beautiful",2]
list2.remove(2)
print(list2.remove(2))
print(list2)
输出:
None
['good', 'nice', 'beautiful']
12345678
6、list.clear()
功能:清除列表中的所有元素,但不删除列表,没有返回值
list2 = [2,"good","nice","beautiful",2]
list2.clear()
print(list2.clear())
print(list2)
输出:
None
[]
12345678
7、del list
功能:删除列表
list2 = [2,"good","nice","beautiful",2]
del list2
print(list2)
输出:
NameError: name 'list2' is not defined
因为列表已经删除了,所以不能再访问,否则会出错
123456
8、list.index(元素,start,end)
功能:返回从指定的范围内[start,end)的列表中查找到第一个与元素匹配的元素的下标
若不指定范围,则默认为整个列表。
注意:若在列表中查不到指定的元素,则会报错
ValueError: 4 is not in list
list1 = ['h','e','l','l','o']
print(list1.index('e'))
输出:
1
1234
9、list.count(元素)
功能:返回元素在列表中出现的次数
list1 = [1,2,3,4,5,1]
print(list1.count(1))
输出:
2
1234
10、len(list)
功能:返回列表元素的个数
list1 = [1,2,3,4,5,[1,3,4]]
print(len(list1))
输出:
6
1234
11、max(list)、min(list)
功能;返回列表中的最大值,若是字符串比较ASCII码
注意:数据类型不同的不能进行比较
min(list)
功能: 返回列表中的最小值,若是字符串则比较ASCII码
list1 = [1,2,3,4,5]
print(max(list1))
print(min(list1))
list2 = ['hello','he','hl','hl','ho']
print(max(list2))
print(min(list2))
输出:
5
1
ho
he
1234567891011
12、list.reverse()
功能:列表倒叙
注意:操作的是原本的列表
list3 = [2,1.22,3,6,33]
list4 = ['hello','nihao','how are you']
list3.reverse()
list4.reverse()
print(list3)
print(list4)
输出:
[33, 6, 3, 1.22, 2]
['how are you', 'nihao', 'hello']
12345678910
13、list.sort()
功能:列表排序,默认升序
注意:操作的是原本的列表
list4 = ['hello','nihao','how are you']
list4.sort()
print(list4)
list4 = [2,3,1,2,4]
list4.sort()
print(list4)
输出:
['hello', 'how are you', 'nihao']
[1, 2, 2, 3, 4]
12345678910
降序:list.sort(reverse=True)
list1 = [1,3,2,4,5,6]
list1.sort(reverse=True)
print(list1)
输出:
[6, 5, 4, 3, 2, 1]
12345
list1 = [1,3,2,4,5,6]
y = list1.copy()
x = list1[:]
print(sorted(list1,reverse=True))
print(list1)
print(y)
print(id(list1))
print(id(y))
print(x)
print(id(x))
输出:
[6, 5, 4, 3, 2, 1]
[1, 3, 2, 4, 5, 6]
[1, 3, 2, 4, 5, 6]
3232179914952
3232179037832
[1, 3, 2, 4, 5, 6]
3232179914824
1234567891011121314151617181920
14、浅拷贝、深拷贝
list1 = list2
注意:浅拷贝是引用拷贝,类似于快捷方式
深拷贝【内存拷贝】
list3 = list1.copy()
注意:重新开辟了一个新的内存空间,存储的数据于list1相同
list1 = ['hello','nihao','how are you']
list2 = list1
print(id(list1))
print(id(list2))
list3 = list1.copy()
print(id(list3))
输出;
1670426304008
1670426304008
1670426233032
1234567891011
15、list(元组)
功能:将元组转为列表。
list1 = list((1,2,3))
print(list1)
输出:
[1, 2, 3]
12345
九、元组函数
1、len(tuple)
获取元组的长度
2、max(tuple)
获取元组的最大值
3、min(tuple)
获取元组的最小值
注意:使用max和min的时候,元组中的元素若是不同类型的数据则不能进行比较
4、tuple(列表)
将列表转为元组
tuple4 =(1,3,2,4,5,3)
print(len(tuple4))
print(max(tuple4))
print(min(tuple4))
print(tuple([1, 2, 3, 4, 6]))
输出:
6
5
1
(1, 2, 3, 4, 6)
12345678910
十、dict字典函数
1、value= 字典名.get(key)
获取字典中关键字对应的值,如果key不存在,返回None
dict1 = {"key1":1,"key2":2}
print(dict1.get("key1"))
输出:
1
1234
2、dict.pop(key) 删除元素
通过key删除元素,返回被删除元素的值,pop一次,dict长度减1
dict1 = {"key1":1,"key2":2}
print(dict1.pop("key1"))
print(dict1.pop("key2"))
print(dict1)
输出:
1
2
{}
12345678
十一、set集合函数
1、set1.add(元素) 添加元素
可以添加重复的元素但是没有效果
不能添加的元素【字典,列表,元组【带有可变元素的】】
set1 = {'key1','key2'}
set1.add('key1')
set1.add('key3')
print(set1)
输出;
{'key1', 'key2', 'key3'}
123456
2、set.update() 添加seq元素
功能:插入整个list【一维】,tuple,字符串打碎插入
set1 = {'key1','key2'}
set1.update(['key3','key4'])
set1.update(('hello',True))
set1.update('key5')
print(set1)
输出;
{'key3', True, '5', 'key1', 'y', 'key4', 'key2', 'k', 'hello', 'e'}
12345678
3、set.remove(元素)删除元素
功能:删除集合中的元素,若元素不存在则会报错,删除一次,set长度减1
set1 = {'key1','key2'}
set1.remove('key1')
print(set1)
set1.remove('key3')
输出;
{'key2'}
报错:KeyError: 'key3'
1234567
十二、栈和队列
1、 栈 stack
特点:先进先出[可以抽象成竹筒中的豆子,先进去的后出来] 后来者居上
mystack = []
#压栈[向栈中存数据]
mystack.append(1)
print(mystack)
mystack.append(2)
print(mystack)
mystack.append(3)
print(mystack)
#出栈[从栈中取数据]
mystack.pop()
print(mystack)
mystack.pop()
print(mystack)
1234567891011121314
2、 队列 queue
特点: 先进先出[可以抽象成一个平放的水管]
#导入数据结构的集合
import collections
queue = collections.deque([1, 2, 3, 4, 5])
print(queue)
#入队[存数据]
queue.append(8)
print(queue)
queue.append(9)
print(queue)
#取数据
print(queue.popleft())
print(queue)
1234567891011121314
模块函数
一、math模块
在使用math模块时要先导入
# 导入模块
import math
123
1、math.ceil(num):对num进行向上取整
number1 = 12.045
num1 = math.ceil(number1)
print(num1)
输出:
13
12345
2、math.floor(num) :对num进行向下取整
number2 = 12.823
num2 = math.floor(number2)
print(num2)
输出:
12
12345
3、math.modf(num) :返回一个元组类型的数据,数据包含小数部分和整数部分
# python默认处理的数据长度是无限大,但由于计算机的数据长度有限,所以处理浮点数会出现误差值
number1 = 12.045
number2 = 12.823
print(math.modf(number1))
print(math.modf(number2))
输出:
(0.04499999999999993, 12.0)
(0.8230000000000004, 12.0)
123456789
4、math.sqrt(num) : 返回num的开平方根,返回一个浮点数
开方
print(math.sqrt(4))
输出:
2.0
123
二、随机函数
# 导入模块
import random
123
1、random.choice(列表/元组/字符串) ,在列表或者元组中随机挑选一个元素,若是字符串则随机挑选一个字符
num1 = random.choice(['hello',True,1,[1,4,5]])
print(num1)
输出(每次输出的结果不一定一样):
1
1234
2、random.randrange([start,end),step) : 返回一个从[start,end)并且步长为step的一个随机数
若start不写,默认为0
多step不写,默认为1
但是end一定要有num2 =
random.randrange(100)
print(num2)# 去头去尾
num3 = random.randrange(80,100,2)
print(num3)# 取一个1~6的随机数
print(random.randrange(1,7))
输出(每次输出的结果不一定一样):
83
84
6
123456789
3、random.random(): 返回一个[0,1)的随机数,结果是一个浮点数
num4 = random.random()
print(num4)
输出(每次输出的结果不一定一样):
0.8073295394931393
1234
4、random.shuffle(列表) :将序列中所有的元素进行随机排序,直接操作序列【序列发生变化】,没有返回值
list1 = [1,2,3,5,6,7]
random.shuffle(list1)
print(random.shuffle(list1)) # 返回结果为None
print(list1)
输出(每次输出的结果不一定一样):
None
[1, 7, 5, 6, 3, 2]
1234567
5、random.uniform(m,n) : 随机产生一个[m,n]的浮点数
print(random.uniform(5,4))
输出(每次输出的结果不一定一样):
4.697767338612918
123
6、random.randint(m,n)
随机产生一个[m,n]的整数
print(random.randint(-1,4))
输出(每次输出的结果不一定一样):
0
123
三、OS模块
在自动化测试中,经常需要查找操作文件,比如查找配置文件(从而读取配置文件的信息),查找测试报告等等,经常会对大量文件和路径进行操作,这就需要依赖os模块。
1. os.getcwd()
功能:查看当前所在路径
import os
print(os.getcwd())
12
2. os.listdir()
列举目录下所有的文件,返回的是列表类型
import os
print(os.listdir("c:\file"))
12
3. os.path.abspath(path)
功能:返回path的绝对路径
绝对路径:【路径具体的写法】“D:\Learn\python\qianfeng\day15”
相对路径:【路径的简写】 :"."
import os
print(os.path.abspath("."))
12
4. os.path.split(path)
功能: 将路径分解为(文件夹,文件名),返回的是元组类型
注意:若路径字符串最后一个字符是,则只有文件夹部分有值,若路径字符串中均无,则只有文件名部分有值,若路径字符串有\且不在最后,则文件夹和文件名都有值,且返回的结果不包括\
import os
print(os.path.split(r"D:\python\file\hello.py"))
#结果
('D:\python\file','hello.py')
print(os.path.split("."))
#结果
('','.')
os.path.split('D:\\pythontest\\ostest\\')
#结果
('D:\\pythontest\\ostest', '')
os.path.split('D:\\pythontest\\ostest')
('D:\\pythontest', 'ostest')
123456789101112131415
5. os.path.join(path1,path2,…)
将path进行组合,若其中有绝对路径,则之前的path将会被删除.
>>> import os
>>> os.path.join(r"d:\python\test",'hello.py')
'd:\pyhton\test\hello.py'
>>> os.path.join(r"d:\pyhton\test\hello.py",r"d:\pyhton\test\hello2.py")
'd:\pyhton\test\hello2.py'
123456
6. os.path.dirname(path)
返回path中文件夹部分,不包括""
>>> import os
>>> os.path.dirname(r"d:\pyhton\test\hello.py")
'd:\pyhton\test'
>>> os.path.dirname(".")
''
>>> os.path.dirname(r"d:\pyhton\test\")
'd:\pyhton\test'
>>> os.path.dirname(r"d:\pyhton\test")
test
123456789
7. os.path.basename(path)
功能:返回path中文件名
>>> import os
>>> os.path.basename(r"d:\pyhton\test\hello.py")
'hello.py'
>>> os.path.basename(".")
'.'
>>> os.path.basename(r"d:\pyhton\test\")
''
>>> os.path.basename(r"d:\pyhton\test")
'test'
123456789
8. os.path.getsize(path)
功能: 获取文件的大小,若是文件夹则返回0
>>> import os
>>> os.path.getsize(r"d:\pyhton\test\hello.py")
38L
>>> os.path.getsize(r"d:\pyhton\test")
0L
12345
9. os.path.exists(path)
功能:判断文件是否存在,若存在返回True,否则返回False
>>> import os
>>> os.listdir(os.getcwd())
['hello.py','test.txt']
>>> os.path.exists(r"d:\python\test\hello.py")
True
>>> os.path.exists(r"d:\python\test\hello1.py")
False
1234567
10.os.path.isdir(path)
功能:判断该路径是否为目录
>>> import os
>>>os.path.isdir(r"C:\Users\zhangjiao\PycharmProjects\day01")
True
>>>os.path.isdir(r"C:\Users\zhangjiao\PycharmProjects\day01\hello.py")
False
12345
11.os.path.isfile(path)
功能:判断该路径是否为文件
import os
print(os.path.isfile(r'C:\360用户文件'))
print(os.path.isfile(r'C:\core.dmp'))
输出:
False
True
123456
四、sys模块
1 sys模块
sys 主要是针对于黑屏终端的库
1.1 sys.argv
sys.argv 获取当前正在执行的命令行参数的参数列表
sys.argv:实现程序外部向程序内部传递参数,返回一个列表
argv[0]:当前的完整路径
argv[1]:传入的第一个参数…
import sys
#实现从程序外部向程序传递参数
print(sys.argv)
#当前程序名
sys.argv[0]
#第一个参数
sys.argv[1]
1234567
1.2 sys.platform
获取当前执行环境的平台
#mac
>>> import sys
>>> sys.platform
'darwin'
1234
1.3 sys.path
path是一个目录列表,供python从中查找第三方扩展模块,在python启动时,sys.path根据内建规则,PATHPATH变量进行初始化
>>> import sys
>>> sys.path
['', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/lib-dynload', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages']
123
五、Image模块
1、使用Image模块
有了PIL,处理图片易如反掌,随便找个图片生成缩略图
# 引入了第三方库
from PIL import Image
#打开图片,路径需要注意
im = Image.open("test.png")
#查看图片的信息
print(im.format, im.size, im.mode)
# 设置图片的大小,注意:图片的大小给定的是个元组
im.thumbnail((200, 100))
#保存成新的图片
im.save("thum.jpg","JPEG")
输出:
PEG (497, 325) RGB
123456789101112
六、time模块
时间格式
'''
%a 本地(local) 简化星期名称
%A 本地完整星期名称
%b 本地简化月份名称
%B 本地完整月份名称
%c 本地相应的日期和时间表示
%d 一个月中的第几天(01-31)
%H 一天中的第几个小时(24小时制00-23)
%I 第几个小时(12小时制01-12)
%j 一年中的第几天(001-366)
%m 月份(01-12)
%M 分钟数(00-59)
%p 本地am或pm的相应符
%S 秒(01-60)
%U 一年中的星期数。(00-53 星期天是一个星期的开始)第一个星期天之前的所有天数都放在第0周
%w 一个星期中的第几天(0-6 0是星期天)
%W 和%U基本相同,不同的是%W以星期一为一个星期的开始
%x 本地相应日期
%X 本地相应时间
%y 去掉世纪的年份(00-99)
%Y 完整的年份
%z 时区的名字
%% '%'字符
'''
import time
time1 = time.time()
lt = time.localtime(time1)
st = time.strftime('''a: %a |A: %A |b: %b |B: %B |c: %c |d: %d
H: %H |I: %I |j: %j |m: %m |M: %M |p: %p
S: %S |U: %U |w: %w |W: %W |x: %x |X: %X
y: %y |Y: %Y |z: %z |%% ''',lt)
print(st)
输出:
a: Thu |A: Thursday |b: Apr |B: April |c: Thu Apr 12 17:15:19 2018 |d: 12
H: 17 |I: 05 |j: 102 |m: 04 |M: 15 |p: PM
S: 19 |U: 14 |w: 4 |W: 15 |x: 04/12/18 |X: 17:15:19
y: 18 |Y: 2018 |Z: +0800 |%
12345678910111213141516171819202122232425262728293031323334353637
1.1 名词解释
UTC :格林威治天文时间,世界标准时间,在中国为UTC+8
DST:夏令时是一种节约能源而人为规定的时间制度,在夏季调快一小时.
1.2 时间的表示形式
1.时间戳
以整数或浮点型表示的是一个秒为单位的时间间隔,这个时间的基础值1970.1.1的零点开始算起
2.元组格式
采用python的数据结构表示,这个元组有9个整型内容,分别表示不同含义
year month day hours minutes seconds weekday Julia days flag[1 夏令时 -1 根据当前时间判断 0 正常表示]
3.格式化字符串
导入时间模块
import time
1
1、time.clock()
以浮点数计算秒数,返回程序运行的时间。
print(time.clock())
time.sleep(2)
print(time.clock())
输出:
0.0
2.0007889054974255
123456
print(time.clock())
输出:
4.665319322446344e-07
123
用处:可用来计算一段程序运行的时间
import time
start = time.clock()
for cock in range(5,101,5): # 公鸡
for hen in range(3,101 - cock,3): #母鸡
for chick in range(1,101 - cock - hen): #小鸡
if cock // 5 + hen // 3 + chick * 3 == 100 and cock + hen + chick == 100:
pass
end = time.clock()
time2 = end - start
print("方案二所花时间",time2)
输出:
方案二所花时间 0.0041665966868768296
12345678910111213
2、time.sleep(seconds)
程序休眠seconds再执行下面的语句。单位s
3、time.time() 时间戳
返回一个浮点型数据
格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总秒数。通俗的讲, 时间戳是一份能够表示一份数据在一个特定时间点已经存在的完整的可验证的数据。 它的提出主要是为用户提供一份电子证据, 以证明用户的某些数据的产生时间。
time1 = time.time()
print(time1)
输出:
1523427779.9672592
1234
4、time.gmtime(时间戳)
把时间戳转成格林尼治时间,返回一个时间元组
time1 = time.time()
gm = time.gmtime(time1)
print(gm)
输出:
time.struct_time(tm_year=2018, tm_mon=4, tm_mday=11, tm_hour=6, tm_min=22, tm_sec=59, tm_wday=2, tm_yday=101, tm_isdst=0)
123456
5、time.localtime(时间戳)
把时间戳转成本地时间,返回一个时间元组。(如中国时区,加上8个小时)
time1 = time.time()
lm = time.localtime(time1)
print(lm)
输出:
time.struct_time(tm_year=2018, tm_mon=4, tm_mday=11, tm_hour=14, tm_min=22, tm_sec=59, tm_wday=2, tm_yday=101, tm_isdst=0)
123456
6、time.mktime(时间元组)
把时间元组转成时间戳,返回一个浮点数。
lm2 = time.localtime(1523328000)
time2 = time.mktime(lm2)
print(time2)
输出:
1523328000.0
12345
7、time.asctime(时间元组)
将时间元组转成一个字符串。
lm2 = time.localtime(1523328000)
st = time.asctime(lm2)
print(st)
输出:
Tue Apr 10 10:40:00 2018
12345
8、time.ctime(时间戳)
将时间戳转成一个字符串。
time1 = time.time()
ct = time.ctime(time1)
print(ct)
输出:
Wed Apr 11 15:18:35 2018
12345
9、time.strftime(format,时间元组)
将时间元组转成指定格式的字符串。
time1 = time.time()
lm = time.localtime(time1)
sct = time.strftime("%Y-%m-%d %X",lm)
print(sct)
输出:
2018-04-11 15:18:35
123456
10、time.strptime(字符串,format)
将指定格式的字符串转成时间元组。
strp = time.strptime('2018-04-10 11:12:57',"%Y-%m-%d %X")
print(strp)
输出:
time.struct_time(tm_year=2018, tm_mon=4, tm_mday=10, tm_hour=11, tm_min=12, tm_sec=57, tm_wday=1, tm_yday=100, tm_isdst=-1)
12345
七、datetime模块
1.1 概述
datetime比time高级了不少,可以理解为datetime基于time进行了封装,提供了更多的实用的函数,datetime的接口更加的直观,更容易调用
1.2 模块中的类
datetime:同时有时间与日期
timedelta:表示时间间隔,即两个时间点的间隔:主要用于计算时间的跨度
tzinfo: 时区相关的信息
date : 只关注日期
2、获取系统当前时间
datetime.datetime.now()
先导入模块:
import datetime
12
t1 = datetime.datetime.now()
print(t1)
输出:
2018-04-11 19:52:06.180339
1234
3、获取指定时间
datetime.datetime(参数列表)
time2 = datetime.datetime(2018, 3, 28, 21, 59, 7, 95015)
print(time2)
print(type(time2))
输出:
2018-03-28 21:59:07.095015
<class 'datetime.datetime'>
123456
4、将时间转为字符串
time1 = datetime.datetime.now()
time3 = time1.strftime("%Y-%m-%d")
print(time3)
输出:
2018-04-11
12345
5、时间相减,返回一个时间间隔的对象
import datetime
import time
time1 = datetime.datetime.now()
time.sleep(3)
time2 = datetime.datetime.now()
time3 = time2 -time1
print(time1)
print(time2)
print(time3)
print(type(time3))
#间隔天数
print(time3.days)
# 间隔天数之外的时间转为秒
print(time3.seconds)
输出:
2018-04-11 20:06:11.439085
2018-04-11 20:06:14.440052
0:00:03.000967
<class 'datetime.timedelta'>
0
3
123456789101112131415161718192021
八、calendar模块
1、calendar模块有很广泛的方法用来处理年历和月历
导入模块
import calendar
1
2、calendar.month(year.month)
返回指定年月的日历【字符串类型】
print(calendar.month(2018,4))
print(type(calendar.month(2018,4)))
输出:
April 2018
Mo Tu We Th Fr Sa Su
1
2 3 4 5 6 7 8
9 10 11 12 13 14 15
16 17 18 19 20 21 22
23 24 25 26 27 28 29
30
<class 'str'>
1234567891011121314
3、calendar.calendar(year)
返回指定年的日历【字符串类型】
4、calendar.firstweekday()
返回当前每周起始日期的设置
print(calendar.firstweekday())
输出:
0
123
5、calendar.isleap(year)
返回指定的年份是否为闰年,若是返回True,否则返回False
print(calendar.isleap(2016))
输出:
True
123
6、calendar.leapdays(year1,year2)
返回[year1,year2)之间闰年的总和。
print(calendar.leapdays(2000,2020))
输出:
5
123
7、calendar.monthrange(year,month)
返回一个元组(参数一,参数二)
参数一:当月的天数
参数二:当月第一天的日期码[0,6][周一,周日]
1234
print(calendar.monthrange(2018,1))
print(calendar.monthrange(2018,2))
print(calendar.monthrange(2018,3))
print(calendar.monthrange(2018,4))
输出:
(0, 31)
(3, 28)
(3, 31)
(6, 30)
123456789
8、calendar.monthlendar(year,month)
返回指定月份以每一周为元素的一个二维列表。
print(calendar.monthcalendar(2018,4))
输出:
[[0, 0, 0, 0, 0, 0, 1], [2, 3, 4, 5, 6, 7, 8], [9, 10, 11, 12, 13, 14, 15], [16, 17, 18, 19, 20, 21, 22], [23, 24, 25, 26, 27, 28, 29], [30, 0, 0, 0, 0, 0, 0]]
1234
9、calendar.weekday(year,month,day)
返回指定日期的日期码。
print(calendar.weekday(2018,4,1))
输出:
6
123
九、IO模块
1、open()读/写文件
f = open(r"文件地址",“读取方式”,encoding=“utf-8”,errors=“ignore”)
str1 = f.read() #一次性读取文件全部内容
f.close()#关闭流
“r”:以只读文本方式读取文件
“rb”:以只读二进制方式读取文件
“w”:以文本方式覆盖文件
“wb”:以二进制方式覆盖文件
“a”:以文本方式追加写进文件
“ab”:以二进制方式追加写进文件
encoding:读取的编码格式
errors=“ignore”:遇到编码错误跳过,继续读取文件
r"文件地址":不让转义字符“\”起作用
with open(r"文件地址",“读取方式”,encoding=“utf-8”) as f:
str1 = f.read()
f.read(size) 按字节size大小读取
f.readline() 读取一行
f.readlines() 以行的方式全部读取文件
print(f.readline())
for line in f.readlines():
print(line.strip() #去掉换行符
123
2、StringIO读写内存字符串
stirngIO顾名思义就是在内存中读写str
from io import StringIO
f = StringIO()
f.write("hello")
f.write(" ")
f.write('world')
#获取写入后的str
print(f.getvalue())
输出:
hello world
123456789
要读取StringIO,可以用一个str初始化StringIO,然后,像读文件一样读取:
from io import StringIO
f = StringIO("Hello\nHi\nGoodBye!")
while True:
s = f.readline()
if s == '':
break
# 去掉换行符
print(s.strip())
输出:
Hello
Hi
GoodBye!
123456789101112
3、BytesIO读写内存二进制
BytesIO实现了在内存中读写bytes,我们创建一个BytesIO,然后写入一些bytes:
from io import BytesIO
f = BytesIO()
f.write("中文".encode('utf-8'))
print(f.getvalue())
输出:
b'\xe4\xb8\xad\xe6\x96\x87'
123456
注意:写入的不是str,而是经过UTF-8编码的bytes
和StringIO类似,可以用一个bytes初始化BytesIO,然后,像读文件一样读取:
from io import BytesIO
f = BytesIO(b'\xe4\xb8\xad\xe6\x96\x87')
d = f.read()
print(d)
print(d.decode())
输出:
b'\xe4\xb8\xad\xe6\x96\x87'
中文
12345678
StringIO和BytesIO是在内存中操作str和bytes的方法,使得读写文件具有一致的接口.
4、序列化
在这里我们把变量从内存中变成可存储或者传输的过程称之为序列化,在python中叫picking,序列化之后,我们就可以把序列化后的内容写入磁盘,或是通过网络传输到别的机器上。反之,把变量内容从序列化的对象重新读取到内存里称之为反序列化,即unpicking。
python提供了pickle模块来实现序列化。
import pickle
d = dict({"name":"lili","age":18})
#pickle.dumps()方法把任意对象序列化成一个bytes,然后就可以把bytes写入文件
print(pickle.dumps(d))
#把序列化后的对象写入文件
f = open("t1.txt",'wb')
#参数一:要写入的对象, 参数二:写入文件的对象
pickle.dump(d,f)
f.close()
#从文件中读取序列化后的对象
f2 = open("t1.txt","rb")
#pickle.load()反序列化对象
d = pickle.load(f2)
f2.close()
print(d)
print(type(d))
输出:
{'name': 'lili', 'age': 18}
<class 'dict'>
12345678910111213141516171819202122
注意:pickle只能用于python,并且不同版本的python彼此都不兼容,因此,只能用pickle保存一些不重要的数据,这样即使不能成功的反序列化也没什么关系。
5、Json
如果我们需要在不同的编程语言之间传递对象,那么我们必须把对象序列化成标准化格式,比如xml,但是更好的方法是json,因为json表现出来就是一个字符串,可以被所有的语言读取,也方便存储到磁盘或者网络传输,json不仅是标准模式,并且速度也比xml更快,还可以在web中读取,非常方便。把python的dict对象变成一个json
import json
dict1 = {"name":"lili","age":18}
ji = json.dumps(dict1)
print(type(ji))
with open("dd.txt","w") as f:
json.dump(dict1,f)
with open("dd.txt","r",encoding="utf-8") as f:
du = json.load(f)
print(du)
print(type(du))
输出:
<class 'str'>
{'name': 'lili', 'age': 18}
<class 'dict'>
12345678910111213141516
将一个class对象序列化为json
import json
class Student(object):
def __init__(self, name, age, score):
self.name = name
self.age = age
self.score = score
# 将student对象转换为dict
def student2dict(std):
return {
'name': std.name,
'age': std.age,
'score': std.score
}
s = Student('Bob', 20, 88)
# 参数一:要传入的对象 参数二:将对象转为dict的函数
d = json.dumps(s, default=student2dict)
# 将dict转为对象
def dict2student(d):
return Student(d['name'], d['age'], d['score'])
jsonStr = '{"age": 20, "score": 88, "name": "Bob"}'
# json反序列化为一个对象
# 参数一:json字符串,参数二:dict转为对象的函数
print(json.loads(jsonStr, object_hook=dict2student))
# 写入文件
with open("t1.txt","w") as f:
f.write(d)
# 读取文件
with open("t1.txt","r",encoding="utf-8") as f:
du = json.load(f,object_hook=dict2student)
print(du)
输出:
<__main__.Student object at 0x000002CA795AA0F0>
<__main__.Student object at 0x000002CA7975B0F0>
12345678910111213141516171819202122232425262728293031323334353637383940
6、读写csv文件
6.1、读csv文件
csv文件本身就是个纯文本文件,这种文件格式经常用来作为不同程序之间的数据交互的格式.
演示:
需求:读取001.scv文件
说明:可以直接打印,然后定义list
import csv
def readCsv(path):
#列表
infoList = []
#以只读的形式打开文件
with open(path, 'r') as f:
#读取文件的内容
allFileInfo = csv.reader(f)
#将获取到的内容逐行追加到列表中
for row in allFileInfo:
infoList.append(row)
return infoList
path = r"C:\Users\xlg\Desktop\001.csv"
info = readCsv(path)
123456789101112131415
6.2、写csv文件
演示:
需求:向002.csv文件中写入内容
import csv
#以写的方式打开文件
def writeCsv(path,data)
with open(path,'w',newline='') as f:
writer = csv.writer(f)
for rowData in data:
print("rowData =", rowData)
#按行写入
writer.writerow(rowData)
path = r"C:\Users\xlg\Desktop\002.csv"
writeCsv(path,[[1,2,3],[4,5,6],[7,8,9]])
123456789101112
7、读取pdf文件
pip是一个安装和管理python包的工具
在进行代码演示之前,首先进行安装和pdf相关的工具
a.在cmd中输入以下命令: pip list [作用:列出pip下安装的所有的工具]
b.安装pdfminer3k,继续输入以下命令:pip install pdfminer3k
c.代码演示
import sys
import importlib
importlib.reload(sys)
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter #解释器
from pdfminer.converter import PDFPageAggregator #转换器
from pdfminer.layout import LTTextBoxHorizontal, LAParams #布局
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed #是否允许pdf和text转换
def readPDF(path, toPath):
#以二进制形式打开pdf文件
f = open(path, "rb")
#创建一个pdf文档分析器
parser = PDFParser(f)
#创建pdf文档
pdfFile = PDFDocument()
#链接分析器与文档对象
parser.set_document(pdfFile)
pdfFile.set_parser(parser)
#提供初始化密码
pdfFile.initialize()
#检测文档是否提供txt转换
if not pdfFile.is_extractable:
raise PDFTextExtractionNotAllowed
else:
#解析数据
#数据管理器
manager = PDFResourceManager()
#创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(manager, laparams=laparams)
#解释器对象
interpreter = PDFPageInterpreter(manager, device)
#开始循环处理,每次处理一页
for page in pdfFile.get_pages():
interpreter.process_page(page)
layout = device.get_result()
for x in layout:
if (isinstance(x, LTTextBoxHorizontal)):
with open(toPath, "a") as f:
str = x.get_text()
#print(str)
f.write(str+"\n")
path = r"0319开始.pdf"
toPath = r"n.txt"
readPDF(path, toPath)
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950
十、高阶函数
1.MapReduce
MapReduce主要应用于分布式中。
大数据实际上是在15年下半年开始火起来的。
分布式思想:将一个连续的字符串转为列表,元素类型为字符串类型,将其都变成数字类型,使用分布式思想【类似于一件事一个人干起来慢,但是如果人多呢?效率则可以相应的提高】,同理,一台电脑处理数据比较慢,但是如果有100台电脑同时处理,则效率则会快很多,最终将每台电脑上处理的数据进行整合。
python的优点:内置了map()和reduce()函数,可以直接使用。
#python内置了map()和reduce()函数
'''
def myMap(func,li):
resList = []
for paser in li:
res = func(paser)
resList.append(res)
'''
12345678
2、map()函数
功能:将传入的函数依次作用于序列中的每一个元素,并把结果作为新的Iterator(可迭代对象)返回
语法:
map(func, lsd)
参数1是函数,参数2是序列
#一、map()
#原型 map(func, lsd)
#将单个字符转成对应的字面量整数
def chrToint(chr):
return {"0":0,"1":1,"2":2,"3":3,"4":4,"5":5,"6":6,"7":7,"8":8,"9":9}[chr]
list1 = ["2","1","4","5"]
res = map(chrToint, list1)
#[chr2int("2"),chr2int("1"),chr2int("4"),chr2int("5")]
print(res)
print(list(res))
#将整数元素的序列,转为字符串型
#[1,2,3,4] --》[“1”,“2”,“3”,“4”]
l = map(str,[1,2,3,4])
print(list(l))
输出:
<map object at 0x0000028288E76780>
[2, 1, 4, 5]
['1', '2', '3', '4']
1234567891011121314151617181920
练习:使用map函数,求n的序列[1,4,9,…,n^2]
num = int(input("请输入一个数:"))
map1 = map(lambda n: n*n,range(1,num+1))
print(list(map1))
输出:
请输入一个数:4
[1, 4, 9, 16]
123456
3、reduce()函数
功能:一个函数作用在序列上,这个函数必须接受两个参数,reduce把结果继续和序列的下一个元素累计运算
语法:reduce(func,lsd)
参数1为函数,参数2为列表
reduce(f,[1,2,3,4])等价于f(f(f(1,2),3),4),类似于递归
from functools import reduce
#需求,求一个序列的和
list2 = [1, 2, 3, 4]
def mySum(x,y)
return x+y
r = reduce(mySum,list2)
print("r=",r)
输出:
r= 10
123456789
练习1,将字符串转成对应字面量数字
from functools import reduce
#将字符串转成对应字面量数字
def strToint(str1)
def fc(x, y):
return x*10 + y
def fs(chr):
return {"0":0,"1":1,"2":2,"3":3,"4":4,"5":5,"6":6,"7":7,"8":8,"9":9}[chr]
return reduce(fc,map(fs,list(str1)))
a = strToint("12345")
print(a)
print(type(a))
#模拟map()函数
def myMap(func,li):
resList = []
for n in li:
res = func(n)
resList.append(res)
输出:
12345
<class 'int'>
123456789101112131415161718192021
练习2,求1!+2!+3!+…+n!之和。【使用map与reduce函数】
from functools import reduce ''' 求1!+2!+3!+...+n!之和 ''' num = int(input("请输入一个正数:")) def jiecheng(n): ji = 1 for i in range(1,n+1): ji *= i return ji list1 = reduce(lambda x,y: x + y ,map(jiecheng,range(1,num+1))) print(list1) 输出: 请输入一个正数:5 153 12345678910111213141516
4、filter()函数
作用:把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留该元素还是丢弃该元素【通过一定的条件过滤列表中的元素】
'''
语法:
filter(func,lsd)
参数一:函数名
参数二:序列
功能:用于过滤序列
简单理解:把传入的函数依次作用于序列的每一个元素,根据返回的True还是False,决定是否保留该元素。
'''
#需求:将列表中的偶数筛选出来。
list1 = [1,2,3,4,5,6,7,8]
#筛选条件
def func(num):
#保留偶数元素
if num%2 == 0:
return True
#剔除奇数元素
return False
list2 = filter(func,list1)
print(list2)
print(list(list2))
print(list1)
输出:
<filter object at 0x0000026E74106B38>
[2, 4, 6, 8]
[1, 2, 3, 4, 5, 6, 7, 8]
12345678910111213141516171819202122232425
注意:使用filter()这个高阶函数,关键在正确实现一个“筛选”函数,filter()函数返回的是一个Iterator,也就是一个惰性序列,所以要强迫filter完成计算结果,需要使用list()函数获取所有的结果并且返回list.
练习
需求;将爱好为“无”的数据剔除掉
data= [["姓名","年龄","爱好"],["tom", 25, "无"],["hanmeimei", 26, "金钱"]] 1 data= [["姓名","年龄","爱好"],["tom", 25, "无"],["hanmeimei", 26, "金钱"]] def filterWu(list1): for i in list1: if i == "无": return False return True dataFilter = list(filter(filterWu,data)) print(dataFilter) 输出: [['姓名', '年龄', '爱好'], ['hanmeimei', 26, '金钱']] 123456789101112
练习2,需求:打印2000到2020之内的闰年[使用filter函数]
import calendar print(list(filter(calendar.isleap,range(2000,2020)))) 输出: [2000, 2004, 2008, 2012, 2016] 1234
5、sorted()函数
sorted(iterable,key,reverse)作用:实现对列表的排序。 1iterable:是可迭代类型;
cmp:用于比较的函数,比较什么由key决定;
key:用列表元素的某个属性或函数作为关键字,有默认值,迭代集合中的一项;
reverse:排序规则. reverse = True 降序 或者 reverse = False 升序,默认值为False。
返回值:是一个经过排序的可迭代类型,与iterable一样。
#排序
#第一类:冒泡 选择
#第二类:快速,插入,计数器
#注意:如果数据量小的情况下,上述两类用法的效率基本相同,但是,如果数据量大的情况下,第一类的效率很低
#1.普通排序
list1 = [4,3,5,6,1]
#默认为升序排序
list2 = sorted(list1)
print(list2)
#2.按绝对值大小排序
list3 = [4,-3,5,2,-9]
#key接受函数来实现自定义排序规则
#abs表示通过绝对值进行排序
list4 = sorted(list3, key=abs)
#利用map可以实现取绝对值之后的排序
list5 = sorted(map(abs,list3))
print(list3)
print(list4)
print(list5)
#3.降序排序
list5 = [2,1,4,5,6,7]
#通过设置reverse=True来表示反转
list6 = sorted(list5,reverse=True)
print(list5)
print(list6)
list7 = ['a','b','c','d']
list8 = sorted(list7)
print(list7)
#同样也可以实现升序排列,结果为abcd,排序依据为ASCII值
print(list8)
#自定义函数:按照字符串的长短来进行排序
def myLen(str1):
return len(str1)
list7 = ['sddd','dded','et54y5','6576986oy','sa','sda']
#使用自定义函数,进行排序,key=函数名
list8 = sorted(list7, key = myLen)
print(list7)
print(list8)
输出:
[1, 3, 4, 5, 6]
[4, -3, 5, 2, -9]
[2, -3, 4, 5, -9]
[2, 3, 4, 5, 9]
[2, 1, 4, 5, 6, 7]
[7, 6, 5, 4, 2, 1]
['a', 'b', 'c', 'd']
['a', 'b', 'c', 'd']
['sddd', 'dded', 'et54y5', '6576986oy', 'sa', 'sda']
['sa', 'sda', 'sddd', 'dded', 'et54y5', '6576986oy']
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354
class Student(object):
def __init__(self,name,age):
self.name = name
self.age = age
def __str__(self):
return self.name +" "+ str(self.age)
stu1 = Student('lili1',18)
stu2 = Student('lili2',19)
stu3 = Student('lili3',17)
stu4 = Student('lili4',20)
stu5 = Student('lili5',20)
list2 = [stu1,stu2,stu3,stu4,stu5]
def com(Student):
return Student.age
list3 = sorted(list2,key=lambda Student: Student.age)
for i in list3:
print(i)
输出:
lili3 17
lili1 18
lili2 19
lili4 20
lili5 20
12345678910111213141516171819202122232425
十一、排列组合(破解密码)
1.排列
itertools.permutations(iterable,n)
参数一:要排列的序列,
参数二:要选取的个数
返回的是一个迭代对象,迭代器中的每一个元素都是一个元组
import itertools #概念:从n个不同元素中取出m(m≤n)个元素,按照一定的顺序排成一列,叫做从n个元素中取出m个元素的一个排列(Arrangement)。特别地,当m=n时,这个排列被称作全排列(Permutation) ''' 1 2 3 4 假设从中取出3个数字 123 132 213 231 321 312 ''' #需求:从[1,2,3,4]4个数中随机取出3个数进行排列 mylist = list(itertools.permutations([1,2,3,4], 3)) print(mylist) print(len(mylist)) ''' 规律总结: 4 - 3 24 4 - 2 12 4 - 1 4 排列的可能性次数:n! / (n-m)! ''' 123456789101112131415161718192021222324252627
2.组合
itertools.combinations(iterable,n)
参数一:可迭代对象
参数二:要选取的个数
返回值:返回一二迭代器,迭代器中的每一个元素都是一个元组
import itertools #概念:从m个不同的元素中,任取n(n≤m)个元素为一组,叫作从m个不同元素中取出n个元素的进行组合 ''' 1 2 3 4 5 中选4个数的组合方式有几种? ''' mylist = list(itertools.combinations([1,2,3,4,5], 4)) print(mylist) print(len(mylist)) ''' 规律总结: m n 5 - 5 1 5 - 4 5 5 - 3 10 5 - 2 10 5! 120/120(m-n)! 120/24(m-n)! 120/6(m-n)! m!/(n!x(m-n)!) ''' 12345678910111213141516171819202122232425
3.排列组合
itertools.product(iterable,repeat=1)
参数一:可迭代对象,参数二:重复的次数,默认为1
import itertools ''' _ _ _ _ _ ''' mylist = list(itertools.product("0123456789QWERTYUIOPASDFGHJKLZXCVBNMqwertyuiopasdfghjklzxcvbnm", repeat=6)) #可以尝试10,有可能电脑会卡住 #多线程也不行,电脑内存不够,咋处理都白搭 #print(mylist) print(len(mylist)) 1234567891011
扩展:现在但凡涉及到密码,一般都会进行加密处理,常用的加密方式有MD5,RSA,DES等
4.疯狂破解密码
伤敌一千自损一万的破解方式
import time import itertools #mylist = list(itertools.product("0123456789", repeat=10)) passwd = ("".join(x) for x in itertools.product("0123456789QWERTYUIOPASDFGHJKLZXCVBNMqwertyuiopasdfghjklzxcvbnm", repeat=6)) #print(mylist) #print(len(mylist)) while True: #先直接实现,然后再添加异常 try: str = next(passwd) time.sleep(0.5) print(str) except StopIteration as e: break 1234567891011121314
十二、正则表达式
1.常用需求
1.1判断qq号
需求:设计一个方法,传入一个qq号,判断这个qq号是否合法
""" 分析 1.全数字 2.位数:5~12 3.第一位不能为0 """ def checkQQ(str): #不管传入的str是否合法,我们假设合法 result = True #寻找条件推翻最初的假设 try: #判断是否是全数字 num = int(str) #判断位数 if len(str) >= 4 and len(str) <= 11: #判断是否以数字0开头 if str[0] == '0': result = False else: result = False except BaseException: result = False return result print(checkQQ("1490980463434")) 1234567891011121314151617181920212223242526272829 考虑:如果要用正则表达式实现上述需求,该怎么做? 12
1.2判断手机号码
需求:设计一个方法,传入一个手机号码,判断这个手机号码是否合法
""" 分析: 1.全数字 2.位数:11位 3.开头只能是1 4.第二位可以为3,4,5,6,7,8 """ def checkPhone(str): result = True try: #判断是否是全数字 int(str) #判断位数 if len(str) == 11: #判断开头是否为1 if str[0] == '1': #判断第二位的数字 if str[1] != '3' and str[1] != '4' and str[1] != '5' and str[1] != '6' and str[1] != '7' and str[1] != '8': result = False else: result = False else: result = False except BaseException: result = False return result print(checkPhone("18501970795")) 12345678910111213141516171819202122232425262728293031 考虑:如果要用正则表达式实现上述需求,该怎么做? 12
2.正则概述
正则表达式(英语:Regular Expression,在代码中常简写为regex、regexp或RE)使用单个字符串来描述、匹配一系列符合某个句法规则的字符串搜索模式。
搜索模式可用于文本搜索和文本替换。
正则表达式是由一个字符序列形成的搜索模式。
当你在文本中搜索数据时,你可以用搜索模式来描述你要查询的内容。
正则表达式可以是一个简单的字符,或一个更复杂的模式。
正则表达式可用于所有文本搜索和文本替换的操作
而在python中,通过内嵌集成re模块,程序媛们可以直接调用来实现正则匹配。正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎执行
3.re模块简介
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数
4.正则表达式的元字符
4.1 匹配单个字符与数字
. 匹配除换行符以外的任意字符
[0123456789] []是字符集合,表示匹配方括号中所包含的任意一个字符
[good] 匹配good中任意一个字符
[a-z] 匹配任意小写字母
[A-Z] 匹配任意大写字母
[0-9] 匹配任意数字,类似[0123456789]
[0-9a-zA-Z] 匹配任意的数字和字母
[0-9a-zA-Z_] 匹配任意的数字、字母和下划线
[^good] 匹配除了good这几个字母以外的所有字符,中括号里的^称为脱字符,表示不匹配集合中的字符
[^0-9] 匹配所有的非数字字符
\d 匹配数字,效果同[0-9]
\D 匹配非数字字符,效果同[^0-9]
\w 匹配数字,字母和下划线,效果同[0-9a-zA-Z_]
\W 匹配非数字,字母和下划线,效果同[^0-9a-zA-Z_]
\s 匹配任意的空白符(空格,回车,换行,制表,换页),效果同[ \r\n\t\f]
\S 匹配任意的非空白符,效果同[^ \f\n\r\t]
12345678910111213141516
print(re.findall("\d", "_sunck is 66a go8od man 3"))
print(re.findall("[A-Z]","_sunck is 66a go8oD man 3"))
print(re.findall("[a-z]","_sunck is 66a go8od man 3"))
print(re.findall("[\S]","_sunck is 66a go8od man 3"))
print(re.findall("[\W]","_sunck is 66a go8od man 3"))
输出:
['6', '6', '8', '3']
['D']
['s', 'u', 'n', 'c', 'k', 'i', 's', 'a', 'g', 'o', 'o', 'd', 'm', 'a', 'n']
['_', 's', 'u', 'n', 'c', 'k', 'i', 's', '6', '6', 'a', 'g', 'o', '8', 'o', 'd', 'm', 'a', 'n', '3']
[' ', ' ', ' ', ' ', ' ']
12345678910111213
4.2 锚字符(边界字符)
^ 行首匹配,和在[]里的^不是一个意思,"^"要写到字符串的前面
$ 行尾匹配,"$"要写到匹配的字符串后面
\A 匹配字符串的开始,它和^的区别是,\A只匹配整个字符串的开头,即使在re.M模式下也不会匹配其它行的行首
\Z 匹配字符串的结束,它和$的区别是,\Z只匹配整个字符串的结束,即使在re.M模式下也不会匹配它行的行尾
\b 匹配一个单词的边界,也就是值单词和空格间的位置
'er\b'可以匹配never,不能匹配nerve
\B 匹配非单词边界
123456789
print(re.search("^sunck", "sunck is a good man"))
print(re.search("man$", "sunck is a good man"))
print(re.findall("^sunck", "sunck is a good man\nsunck is a nice man", re.M))
print(re.findall("\Asunck", "sunck is a good man\nsunck is a nice man", re.M))
print(re.findall("man$", "sunck is a good man\nsunck is a nice man", re.M))
print(re.findall("man\Z", "sunck is a good man\nsunck is a nice man", re.M))
print(re.search(r"er\b", "never"))
print(re.search(r"er\b", "nerve"))
print(re.search(r"er\B", "never"))
print(re.search(r"er\B", "nerve"))
输出:
<_sre.SRE_Match object; span=(0, 5), match='sunck'>
<_sre.SRE_Match object; span=(16, 19), match='man'>
['sunck', 'sunck']
['sunck']
['man', 'man']
['man']
<_sre.SRE_Match object; span=(3, 5), match='er'>
None
None
<_sre.SRE_Match object; span=(1, 3), match='er'>
1234567891011121314151617181920212223
#匹配qq邮箱,5~12位,第一位不为0
import re
print(re.findall(r"^[1-9]\d{4,11}@qq\.com$","[email protected]"))
print(re.findall(r"^[1-9]\d{4,11}@qq\.com$","[email protected]"))
print(re.findall(r"^[1-9]\d{4,11}@qq\.com$","[email protected]"))
123456
4.3匹配多个字符
说明:下方的x、y、z均为假设的普通字符,n、m(非负整数),不是正则表达式的元字符
(xyz) 匹配小括号内的xyz(作为一个整体去匹配)
x? 匹配0个或者1个x(非贪婪匹配【尽可能少的匹配】)
x* 匹配0个或者任意多个x(.* 表示匹配0个或者任意多个字符(换行符除外))(贪婪匹配【尽可能多的匹配】)
x+ 匹配至少一个x(贪婪匹配)
x{n} 匹配确定的n个x(n是一个非负整数)
x{n,} 匹配至少n个x
x{n,m} 匹配至少n个最多m个x。注意:n <= m
x|y |表示或,匹配的是x或y
123456789
import re
print(re.findall(r"a?", "aaa"))#非贪婪匹配(尽可能少的匹配)
print(re.findall(r"a*", "aaabaa"))#贪婪匹配(尽可能多的匹配)
print(re.findall(r"a+", "aaabaaaaaa"))#贪婪匹配(尽可能多的匹配)
print(re.findall(r"a{3}", "aaabaa"))
print(re.findall(r"a{3,}", "aaaaabaaa"))#贪婪匹配(尽可能多的匹配)
print(re.findall(r"a{3,6}", "aaaabaaa"))
print(re.findall(r"((s|S)unck)", "sunck--SuNck--Sunck"))
#需求,提取sunck……man,
str = "sunck is a good man!sunck is a nice man!sunck is a very handsome man"
print(re.findall(r"sunck.*?man", str))
输出:
['a', 'a', 'a', '']
['aaa', '', 'aa', '']
['aaa', 'aaaaaa']
['aaa']
['aaaaa', 'aaa']
['aaaa', 'aaa']
[('sunck', 's'), ('Sunck', 'S')]
['sunck is a good man', 'sunck is a nice man', 'sunck is a very handsome man']
123456789101112131415161718192021222324
4.4特殊
*? +? x? 最小匹配,通常都是尽可能多的匹配,可以使用这种解决贪婪匹配(?:x) 类似(xyz),但不表示一个组
1
# /* part1 */ /* part2 */
print(re.findall(r"/\*.*?\*/","/* part1 */ /* part2 */"))
输出:
['/* part1 */', '/* part2 */']
1234
十三.re模块中常用功能函数
1 compile()
编译正则表达式模式,返回一个对象的模式。(可以把那些常用的正则表达式编译成正则表达式对象,这样做的目的是为了可以提高一点效率
格式:
re.compile(pattern,flags=0)
pattern: 编译时用的表达式字符串。
flags 编译标志位,用于修改正则表达式的匹配方式,如:是否区分大小写,多行匹配等
flags定义包括:
re.I:使匹配对大小写不敏感
re.L:表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M:多行模式
re.S:’ . ’并且包括换行符在内的任意字符(注意:’ . ’不包括换行符)
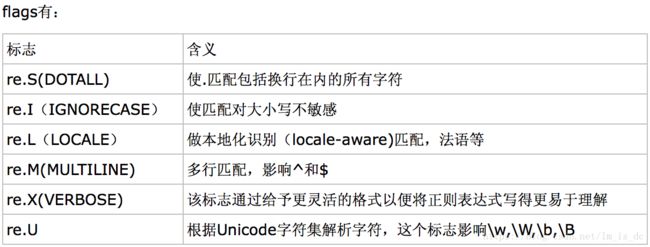
re.U: 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库re.X VERBOSE 详细模式。该模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
代码演示:
import re tt = "Tina is a good girl, she is cool, clever, and so on..." rr = re.compile(r'\w*oo\w*') print(rr.findall(tt)) #查找所有包含'oo'的单词 #执行结果如下: #['good', 'cool'] 1234567
2 match()
决定RE是否在字符串刚开始的位置匹配。//注:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符’$’。检测不成功则返回None。
格式:
re.match(pattern, string, flags=0)
代码演示:
import re print(re.match('com','comwww.runcomoob').group()) print(re.match('com','Comwww.runcomoob',re.I).group()) print(re.match("com$","[email protected]")) print(re.match(r"^[1-9]\d{4,11}@qq\.com$","[email protected]")) 输出: com Com None <_sre.SRE_Match object; span=(0, 15), match='[email protected]'> 12345678910
3 search()
格式:
re.search(pattern, string, flags=0)
re.search函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回一个可迭代对象,如果字符串没有匹配,则返回None
代码演示:
import re print(re.search('\dcom','www.4comrunoob.5com').group()) print(re.search("a+","aabaaaa")) print(re.findall("a+","aabaaaa")) 输出: 4com <_sre.SRE_Match object; span=(0, 2), match='aa'> ['aa', 'aaaa'] 12345678
4 findall()
re.findall遍历匹配,可以获取字符串中所有匹配的字符串,返回一个列表
格式:
re.findall(pattern, string, flags=0)
代码演示:
import re p = re.compile(r'\d+') print(p.findall('o1n2m3k4')) 输出: ['1', '2', '3', '4'] 123456 import re tt = "Tina is a good girl, she is cool, clever, and so on..." rr = re.compile(r'\w*oo\w*') print(rr.findall(tt)) 输出: ['good', 'cool'] 1234567
5 finditer()
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。找到 RE 匹配的所有子串,并把它们作为一个迭代器返回。
格式:
re.finditer(pattern, string, flags=0)
代码分配:
import re iter = re.finditer(r'\d+','12 drumm44ers drumming, 11 ... 10 ...') for i in iter: print(i) print(i.group()) print(i.span()) 输出: <_sre.SRE_Match object; span=(0, 2), match='12'> 12 (0, 2) <_sre.SRE_Match object; span=(8, 10), match='44'> 44 (8, 10) <_sre.SRE_Match object; span=(24, 26), match='11'> 11 (24, 26) <_sre.SRE_Match object; span=(31, 33), match='10'> 10 (31, 33) 12345678910111213141516171819
6 split()
按照能够匹配的子串将string分割后返回列表。
可以使用re.split来分割字符串,如:re.split(r’\s+’, text);将字符串按空格分割成一个单词列表。
格式:
re.split(pattern, string[, maxsplit])
maxsplit用于指定最大分割次数,不指定将全部分割
代码演示:
import re print(re.split('\d+','one1two2three3four4five5')) 输出: ['one', 'two', 'three', 'four', 'five', ''] 1234
import re
string3 = '[12:23:90][12:90:87][23233][dsnernrev]'
print(re.split(r"\[|\]",string3))
输出:
['', '12:23:90', '', '12:90:87', '', '23233', '', 'dsnernrev', '']
12345
7 sub()
使用re替换string中每一个匹配的子串后返回替换后的字符串。
格式:
re.sub(pattern, repl, string, count)
代码演示:
import re text = "Bob is a handsome boy, he is cool, clever, and so on..." print(re.sub(r'\s+', '-', text)) 输出: Bob-is-a-handsome-boy,-he-is-cool,-clever,-and-so-on... #其中第二个参数是替换后的字符串;本例中为'-' #第四个参数指替换个数。默认为0,表示每个匹配项都替换。 123456789re.sub还允许使用函数对匹配项的替换进行复杂的处理。
如:re.sub(r’\s’, lambda m: ‘[’ + m.group(0) + ‘]’, text, 0);将字符串中的空格’ ‘替换为’[ ]’。
代码演示:
import re text = "JGood is a handsome boy, he is cool, clever, and so on..." print(re.sub(r'\s+', lambda m:'['+m.group(0)+']', text,0)) 输出: JGood[ ]is[ ]a[ ]handsome[ ]boy,[ ]he[ ]is[ ]cool,[ ]clever,[ ]and[ ]so[ ]on... 12345
8 subn()
返回替换次数
格式:
subn(pattern, repl, string, count=0, flags=0)
代码演示:
import re print(re.subn('[1-2]','A','123456abcdef')) print(re.sub("g.t","have",'I get A, I got B ,I gut C')) print(re.subn("g.t","have",'I get A, I got B ,I gut C')) 输出: ('AA3456abcdef', 2) I have A, I have B ,I have C ('I have A, I have B ,I have C', 3) 12345678
9. 一些注意点
1、re.match与re.search与re.findall的区别:
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配
代码演示:
import re a=re.search('[\d]',"abc3").group() print(a) p=re.match('[\d]',"abc3") print(p) b=re.findall('[\d]',"abc3") print(b) #执行结果: #3 #None #['3', '3'] 12345678910112、贪婪匹配与非贪婪匹配**
?,+?,??,{m,n}? 前面的,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
代码演示:
import re a = re.findall(r"a(\d+?)",'a23b') print(a) b = re.findall(r"a(\d+)",'a23b') print(b) #执行结果: #['2'] #['23'] 12345678 #这里需要注意的是如果前后均有限定条件的时候,就不存在什么贪婪模式了,非匹配模式失效。 a = re.findall(r"a(\d+)b",'a3333b') print(a) b = re.findall(r"a(\d+?)b",'a3333b') print(b) #执行结果如下: #['3333'] #['3333'] 1234567893、用flags时遇到的小坑
print(re.split('a','1A1a2A3',re.I))#输出结果并未能区分大小写 #这是因为re.split(pattern,string,maxsplit,flags)默认是四个参数,当我们传入的三个参数的时候,系统会默认re.I是第三个参数,所以就没起作用。如果想让这里的re.I起作用,写成flags=re.I即可 12
10.使用练习
#1、匹配电话号码[座机]
p = re.compile(r'\d{3}-\d{6}')
print(p.findall('010-628888'))
123
#2、匹配IP
b = re.search(r"\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b", '192.168.11.244')
print(b)
123