后门攻击阅读笔记,Input-aware dynamic backdoor attack
论文标题:Input-aware dynamic backdoor attack
论文单位:VinAI Research, Hanoi University of Science and Technology, VinUniversity
论文作者:Tuan Anh Nguyen, Tuan Anh Tran
收录会议:NIPS2020
开源代码:https://github.com/VinAIResearch/input-aware-backdoor-attack-release
输入感知的动态的后门攻击(攻击)
简单总结
一种新的后门攻击方法
-
以前的工作生成的触发器都是与输入无关的,这是一个全新的工作,打开了触发器与输入相关的大门。
-
场景:外包场景,攻击者持有数据和模型的设计
-
使用数据集:MNIST、CIFAR-10和GTSRB
-
触发器特点:强制生成的触发器对不同的输入具有多样性和不可重用性
-
模型特点:设计一个专门生成触发器的生成器(自动编码器结构),设计一个由多个任务合成的loss,需要保证多样性和不可重用性。
-
攻击方法:模型在使用SGD更新参数过程中,对每一个batch中的每一个输入的干净样本根据概率大小,选择使用该样本计算分类loss,或是选择该样本添加对应触发器计算攻击loss,或是选择该样本添加随机抽取别的样本的触发器计算分类loss,将一个batch内的所有样本对应的loss加起来,并加上保证触发器差异的一个正则化项,进而训练得到带后门的模型。
值得做的点(仅从本文出发)
-
该文章有点类似与NIPS2019发表的Clean-Label Attack,但那篇是属于数据投毒攻击,生成的也是多样性的模式,但那个攻击会降低模型的精度,也是比较类似于对抗样本的生成,对不同输入添加不同的噪声,只是形式上,不谈生成的手段。或许,可以借鉴数据投毒攻击、对抗样本的生成,生成更加鲁棒的且具有多样性的触发器。
-
有攻必有防,可以针对该新型攻击手段提出防御方法。比如我很好奇Gradcam为什么没有检测到触发器的位置,从Gradcam在人工智能可解释性的角度来看,模型关注的点在于热力值偏大的地方,但在这里可以使其攻击成功,但检测到的点不在于添加的触发器上,这个是需要后面做实验去进行展开的。
abstract
-
在本工作中,提出了一种新的后门攻击技术,其中触发器因输入而异。
-
为了实现这一目标,实现了由多种损失驱动的输入感知触发器生成器。
-
一种新的交叉触发测试被应用于执行触发器的不可重用性,使得目前的后门验证不可能。
1.introduction
介绍一下以前的工作,虽然在机制和场景上有所不同,但所有这些攻击都依赖于在所有中毒数据上使用固定触发器的相同前提。
作者认为,固定触发器阻碍了后门攻击方法的能力。 具有从输入到输入的触发模式的动态后门要隐蔽得多。 它打破了目前所有防御方法的基础假设,从而容易击败它们。

如图所示,触发器不可重复使用;将触发器插入不匹配的干净输入不会激活攻击。
2.background
2.1场景假设
我们考虑大多数后门攻击和防御研究使用的标准威胁模型。 对手对训练过程有完全的控制,有目的地用后门训练深层神经网络。然后将受感染的网络按原样提供给客户。 客户可以在部署模型之前或之后运行保护方法。(外包场景)
2.2以前的后门攻击
-
BadNets
-
Trojaning Attack 特洛伊木马攻击
-
Targeted Backdoor Attacks
再次强调:所有之前的方法都依赖于统一的后门触发器,而不管输入图像如何。
2.3后门防御
防御方法分三类:training defense, model defense, and testing-time defense.
[1] training defense:这个防御假设防守者可以获得训练数据,侧重于数据异常检测。 然而,这个假设不符合我们的假设,所以直接不考虑。
[2] model defense:模型防御方法试图在部署之前验证或缓解第三方模型。
-
Fine-Pruning:通过切割在干净输入上休眠的神经元来中和深层网络。 然而,它无法验证模型是否有后门
-
Neural Cleanse :第一项能够检测中毒模型的工作
-
ABS:扫描神经元并通过反向工程技术生成触发候选。 然后通过应用于一组干净的图像来验证这些触发器
-
GradCam:分析干净输入图像上的网络行为,有和没有合成触发器来检测异常
-
Mode Connectivity approach:间接地将模式连接应用于检查后门行为,有效地减轻后门,同时在良性数据上保持可接受的模型性能
[3] Testing-time defense:当深度模型已经部署时,在测试时进行防御。
STRIP:给定一个可能中毒的输入图像,STRIP将通过一组随机的干净图像来扰动它,并监视预测输出的熵
3.Method
我们认为,所有图像的通用后门触发器是一种糟糕的做法,也是当前攻击方法的致命弱点。 防御者可以通过优化和验证一组干净的输入来估计全局触发器。 因此,我们提出了一种新的方法,其中每个图像都有一个唯一的触发器,并且图像的触发器不会在其他图像上工作。
3.1定义

这个触发器生成器还需要满足两个特性:
Diversity :不同干净输入所生成的触发器不能相同
**Nonreusablity **:一个输入图像生成的触发器不能在另一个图像上使用
- 首先,我们设计触发器生成器为自动编码器,在干净图像输入工作。
- 其次,我们提出了一种新的交叉触发模式,以及标准的干净和攻击模式,以强制触发不可重用性。
- 最后,我们合并了训练中使用的目标函数。
3.2触发器生成器网络/3.3运行模式

现有的后门攻击被训练在两种模式上:
(a)干净模式,网络必须正确识别干净图像;
(b)攻击模式,攻击被激活的有毒数据。
为了增强触发器的非重复性,我们提出了一种新的交叉触发模式。 给定一个干净的输入 x x x,我们随机选择一个不同的图像 x ′ x' x′,还有产生对应的触发器 t ′ t' t′。 将 t ′ t' t′注入 x x x让其分类为干净标签 y y y。
©交叉触发模式,增强每个触发器的非重复性。
在评估中,我们有三个相应的运行模式:干净模式、攻击模式和交叉触发模式。
3.4目标函数
Classifification loss:根据不同概率使用不同损失

Diversity loss:保证差异的一个正则化项

合并loss

4Experiments
4.1实验设置/4.2攻击实验
评估数据集: MNIST, CIFAR-10 and GTSRB datasets
具体实现伪代码:

触发生成器网络结构设计
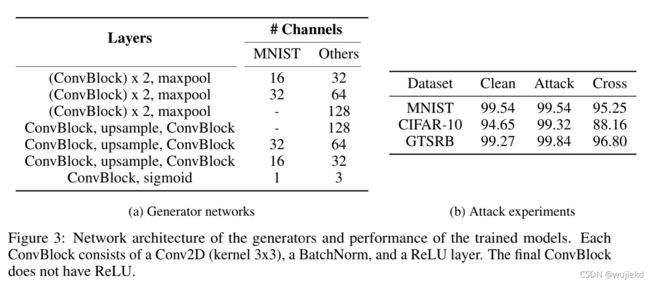
对于所有三个数据集,后门攻击成功率(ASR)几乎为100%,而在干净数据上仍然达到与良性模型相同的性能。 此外,交叉触发精度从88.16%(CIFAR-10)到96.80%(GTSRB),证明后门触发器不适用于未配对的干净图像。
4.3防御实验
根据前面background的介绍,这里作者展开对两个防御场景进行实验: Model defense 和 Testing defense
Model defense :Neural Cleanse, Fine-Pruning and Mode Connectivity
它们代表了三种不同的模型防御方法:模式优化、神经元分析和基于loss情况的模型修复
Testing defense:STRIP
STRIP:给定一个可能中毒的输入图像,STRIP将通过一组随机的干净图像来扰动它,并监视预测输出的熵。
传统的后门攻击输出的熵不会受到太大影响,而干净样本会受到影响,作者设计的这种攻击方法收到扰动后也会受到影响,因此可以抵挡这种实时的防御。
4.4模型简化测试
-
Without the cross-trigger test 没有这个交叉触发测试,针对某一张图片生成的触发器也可应用于另一张图片。
-
Without the diversity loss 这个交叉触发和攻击模式会产生矛盾,模型训练无法收敛,因为模型对于同样的触发器要输出不同的结果。
-
Without both losses 上面两个都不使用的话,和一个标准BatNet没差别,不同图片所生成的触发器也都是一样的。
-
Classifification loss所使用概率的超参数的分析
4.5行为分析
-
在应用一些简单的图像正则化(image smoothing or color depth shrinking)时,作者提出的方法仍具有鲁棒性,效果下降的不多。
-
使用了Gradcam去可视化不同的中毒图像,左三列是以前的方法,右边这列是作者提出的,可以看到GradCam并不能很好地检测出触发器的位置,也说明了传统的后门攻击在很大程度上依赖于图像无关的触发器。
