十八周周报
文章目录
- 摘要
- 文献阅读3D reconstruction of human bodies from single-view and multi-view images: A systematic review
- 简介
- 研究方法
-
- 搜索策略
- 选择标准
- 搜索结果
- 三维重建方法
-
- 单个视图中使用的技术
-
- 基于参数化人体模型的回归
- 基于非参数人体模型的回归
- 多个视图中使用的技术
-
- 基于参数回归的模型
- 多视图卷积神经网络
- 非参数回归模型
- 数据集
- 讨论
- 结论和展望
- 总结
- Python基础学习
- python
-
- 最重要的是缩进
- 变量,字符串,原始字符串,长字符串
- 条件分支、while循环
- python逻辑运算符
- 数字类型
-
- int
- foalt
- 复数
- 数值运算
- 布尔类型
- 运算优先级
- 流程图
- 思维导图
- 分支和循环
-
- 分支结构嵌套
- for
- 列表
- 浅拷贝和深拷贝
- 列表推导式(用的c语言进行的)
- KISS原则
- 元组tuple
- 字符串
- 序列
-
- is is not
- in not in
- del
- 可迭代对象和迭代器
- 字典
-
- 增
- 改
- 删
- 查
- 视图对象:
- 嵌套
- 字典推导式
- 集合
-
- 建立
- frozenset 不可变集合
-
- 删除:
- 可哈希
- 函数
-
- 定义一个函数和调用
- 形参和实参
- 递归
-
-
- 部分字符串方法含义
-
摘要
本周我找了一篇从单视图和多视图图像重建人体的综述文章;对目前3d人体重建的领域有了一点认识和了解,和之前接触的姿态估计上有很多区别,尤其是这篇综述,它专门挑选了与姿态估计有区分的文章进行整理和总结。
学习python的基础。
This week, I found a comprehensive review article on the reconstruction of the human body from single-view and multi-view images. I gained some understanding and insight into the current field of 3D human body reconstruction, which is quite different from my previous exposure to pose estimation. In particular, this review article specifically selected and organized papers that distinguish themselves from pose estimation, providing a unique perspective on the subject.
Study the primary of python.
文献阅读3D reconstruction of human bodies from single-view and multi-view images: A systematic review
简介
目前,技术的进步使生物医学领域受益匪浅,特别是在人体重建领域。
3D重建在生物医学领域的一些主要好处集中在图像数据分析,其中 3D重建用于分析图像数据,以获得关于人体生理的更详细的信息。
随着三维(3D)扫描仪和数字化物体形状、结构和颜色的设备的出现,新的临床应用领域出现了,因为 3D扫描仪必须捕获准确和健壮的3D人体地图的高容量。3D扫描仪开始对解决人体形状分析相关的医学问题产生重大影响。
近年来,随着消费级采集设备的普及,通过简单输入进行人体扫描,特别是图像扫描,成为三维计算机视觉领域的一个反复出现的研究课题。参数化模型()对3维人体进行重构。
现阶段深度学习的方法不能获得穿着衣服的人体三维模型,就是只能生成裸体人类,还是只能获得关键点和轮廓。
深度学习的方法:点积云、网格、体积表示。
点积云:使用一组点来描述一个3D对象,这些点定义了对象的形状和表面。
网格:通过多边形(三角形和四边形)来描述三维物体的经典方法,这些多边形构成一个面网。
体积表示:学习从RGB图像中推断3D对象。
隐式表示:三维模型可以由连续的决策边界决定,这允许在任意分辨率下的形状恢复。
多视图图像:视觉船体:它使用来
自多个视图的剪影、视锥、体素或多边形网格来相 交捕获体的可见区域。
本文的主要目的是对近年来基于二维图像的人体或人体部位的三维重建进行综述。重点将是主要的挑战,应用领域,以及从单个和多个图像的三维重建的各种方法。本章收集了自 2016年以来在领先的计算机视觉、计算机图形学和机器学习会议和期刊上发表的70篇论文。
研究方法
1.从单视图和多视图图像中,都采用了哪些方法或技术进行人体三维重建?
2.人体三维重建面临哪些挑战?
3.在人体三维重建中有哪些不同的数据集?
4.什么指标被用来评估三维重建技术?
搜索策略
Web of Science 和ScienceDirect 数据库中搜索
“从单视角对人体进行3D重建”和“从多视角对人体进行3D重建”的2016年12月至2023年3月期间发表的文章。
选择标准
1.只找英文期刊
2.标题中必须含有人体三维重建
3.排除了人体姿态和形状估计、人体实时跟踪、全场景重建的文章
4.传感器的三维重建、或者依赖描述骨骼位置的信号方法也排除。
5.基本只剩下从二维图像开始进行重建。
搜索结果
搜索确定了 3325个出版物。首先,20篇与专利和非
英语出版物相关的文章被排除在外。在审查了剩下的出版物的标题和摘要后,3098份被删除了,因为他们做了生物医学计算机方法与程序239 (2023)107620
不符合选定的选择标准。也就是说,他们并不关心从图像(单视图或多视图)对人体进行三维重建。然后删除两个数据库中重复的文章,留下189篇发表的文章进行完整的内容分析。因此,本文对70篇文献进行了系统的回顾和分析。

三维重建方法
单个视图中使用的技术
通过选择一个特定的参数化身体模型,将估计限制在一个小的模型参数集。利用深度神经网络从几个容易获得的输入中推断出可信的3D物体。
但是,由于遮挡和固有的深度模糊,这些方法在生成详细和准确的结果方面有一定的局限性。
基于参数化人体模型的回归
参数化模型: 3D扫描,2D或 3D 关键点,或轮廓。
根据输入图像调整三维参数化模型一直是从单个二维图像重建三维图像的主要方法之一。
例如:
SCAPE:依靠人工点击数据来构建包含形状和3D姿态变化的人体形状模型。该方法是基于一种表示,包括关节和非刚体变形的人体。
SMPL:是一种基于顶点的蒙皮统计模型,它准确地代表了人体自然姿势中各种各样的体型。
SMPLify:通过最小化目标函数来改进 SMPL,该目标函数会惩罚投影模型关节和之前检测到的 2D关节之间的误差。该目标函数将统计体型模型SMPL拟合到由卷积模型获得的二维关节上,并结合一些姿态和形状的先验信息。
simplify:通过检测相应的 2D特征,改进了完
全铰接的手和表情脸。并且能自动检测模型和每个身体都有合适的身体模型。
Photo wake-up:一种二维变形方法,通过变
形模型来适应身体的复杂轮廓。人员检测和二维姿态估计被执行并适应于SMPL模板模型该方法的目标是找到一个人的轮廓和SMPL轮廓之间的对齐,将SMPL法线映射变形到输出,并通过整合扭曲的法线映射来构建深度图。
李振宇等人提出了一个中基于GAN纹理推理的方法:
来重建人体几何和整个身体的纹理地图。首先对输入图像中的人体部位进行分割,然后将人体与参数化模型进行拟合得到初始几何图形。
STAR:一个更紧凑的模型,该模型可以更好地扩展到新物体。因此有用该模型来表示有衣服的三维人体模型的方法:
第一阶段,将基于回归的方法和基于优化的方法相结合来估计位姿参数和形状参数;利用STAR算法从提取的参数中构造出对齐良好的参数体模型。然后将参数化的身体模型用语义代码进行体素化和索引,并将其输入到方法的第二步。
第二阶段由深度神经网络组成,该网络将体素化的参数化模型和输入图像作为输入,用于三维人衣重建。
最后,利用步进立方算法得到三维人衣网格。
一种协调参数化模型鲁棒性与自由三维变形柔性的方法:法使用深度神经网络,利用人体关节、轮廓和逐像素阴影信息的约束,在层次网格变形(HMD)框架中恢复详细的人体形状。
Alldieck:提出了另一种具有相同目标的方法,他们使用卷积神经网络从现成方法获得的可见区域的部分纹理映射中推断法向和向量位移。这种方法的最大优点
是,它可以通过头发、衣服和皱纹等细节反映人体的形状。
kolotouro提出了了一种回归方法和基于优化的方法之间的协作,它通过结合CNN和优化方法的自改进模型来估计 SMPL参数,使拟合更快、更准确。但是未能捕捉宽松的衣服和人体的许多细节。
Chun等人提出了一个基于两个阶段的方法:首先,利用基于 cnn的模型从输入图像中估计坐标,最后将 SMPL模型拟合到估计的坐标上,得到SMPL参数。结果明显优于以往的人体网格重建方法。
基于非参数人体模型的回归
想找到一种既有内存效率又能够从数据中有效地推断出三维表面,因此数据驱动的方法可以分为::体积表示、隐式表示和点云表示。

1、体积表示:将3D形状表示为定义在固定分辨率体素网格上的占用图。
文献中有最广泛的四种体积表示方法:
•二进制占用网格:二进制占用网格表示一个均匀间隔的地图域,其中,如果一个体素属于感兴
趣的对象,则它被设置为1,而背景体素被设置为0。
•概率占有网格:概率占有网格中的每个体素都是二进制随机变量,编码其属于感兴趣对象的
概率。
•有符号距离函数(SDF):每个体素编码它到最近的表面点的有符号距离,信号由该点是否在对
象内部设置。如果体素位于对象内部,则为正,否则为负。
•截断有符号距离函数(TSDF):该表达式的计算方法是,首先估计距离传感器的视线,形成一个投影的有符号距离场,然后在小的负值和正值处截断该场。
早期是使用在体素网格(voxel grids)上运行的 3D卷积神经网络从单个图像重建3D几何图形的问题:
代表方法是:
Varol 等人提出了一种对二维CNN的扩展,通过神经网络对体积输出进行直接推断体形。具体来说,他们使用了一个形状估计子网络输出身体的三维形状,表示为在 1283体素网格上定义的二元占用图,具有固定的分辨率。为了保证体素与输入图像在空间上的对应,作
者使用正投影对体积进行缩放,从而检查 xy平面与2D分割掩码的对齐情况。
Jackson等人也提出了一种端到端的卷积神经网络,
通过体积回归来重建三维几何图形。该方法将三维空间离散为一个固定的维度,其中对象内部的空间被编码为 1,其余为0。
DeepHuman:提出了一种离散的体积表示,以减少与表面几何重构相关的歧义。他们利用三维空间中不同尺度的图像特征,通过多尺度的体特征变换,将二维图像引导信息融合成三维体。使用表面法线的附加细节在最后一层通过法线细化网络浮雕,该网络基于输入图像细化表面法线。精确度高。
预测TSDF的方法:三维网格中的每个点都存储了到最近的三维曲面点的截断符号距离。
Curless 和Levoy引入了TSDF来表示3d曲面。
TetraTSDF:基于将一个四面体TSDF场嵌入人体特有的外壳,在覆盖兴趣空间的同时减少人体表面周围的干扰场。此外,作者开发了一种新的基于多个四面体层的沙漏网络,用于回归四面体模型中每个顶点的TSDF 值。
另一种基于 tsdf的方法使用一个带有RGB-D相机的航空机器人来执行图像采集。
其他的体积方法使用体素表示的层次形式:八叉树。八叉树的基础是将空间递归细分为八个八边形。Riegler等人[19]提出了一种基于八叉树和CNN的稀疏3D数据表示,用于预测高分辨率占用地图。
OPlanes:它允许将单视图人体三维形状重建公式作为占用面预测。使用OPlanes生成占用网格,通过运行立方体算法得到人体网格。与传统的体素网格相比,这种方法的主要优点是其分辨率的灵活性。
DeepHuman他们利用三维空间中不同尺度的图像特征,通过多尺度的体特征变换,将二维图像引导信息融合成三维体。
八叉树?

2、神经隐函数
体积内隐表征和神经内隐表征的主要区别在于所使用的数学模型。体积表示依赖于数学函数来描述物体的形状,而神经隐式表示则使用学习过的神经网络来建模物体的表面。
基于隐函数和像素对齐特征的三维重建方法
像素对齐隐函数(PIFu):通过一个隐函数来预测三维空间中的一个点是否在人体表面内,从而估计一个密集的三维体积的占用率。
PIFuHD:以1024 × 1024分辨率的图像作为输入,通过多级方法实现更高保真度的3D人体数字化,从而改善PIFu的结果。
Geo-PIFu:扩展了像素对齐的特征与几何对齐的形状
特征,通过潜在体素表示估计,增强了特征集,并使整体正常化。

PIFu的两种变体与官方PIFu的比较
但是神经隐函数只能产生静态和不可控制的表面,因此不能通过改变姿态或形状参数来修改最终的模型。
Bhatnagar提出了将参数化人体网络(例如SMPL)和隐曲面函数结合起来的方法,获得一个可编辑的曲面。
Chan提出了一种将参数化人体模型纳入隐式模型的新策略:该方法使用 pix2pixHD网络从输入图像中预测前后法线映射。并利用简化对参数模型进行估计。
Liu提出了一种对隐函数进行骨架识别(SIF)。骨骼识别框架是一种骨骼引导的采样策略和一种骨骼识别框架,能够有效地减轻人体的损伤相对编码策略。
但上述方法在对人脸的重建时,不能恢复其面部细节。
JIFF:是一种联合对齐的隐式人脸函数,它将基于隐式函数的方法与基于模型的方法相结合,是一些学者在三维重建中改善人脸质量的一个例子。
TransPIFu:Transformer和PIFu表示相结合,实现高质量的深度感知。其区别是,从输入图像中提取三维特征,然后将其分割成几个序列的三维特征块,利用序列之间的几何相关性,使用变压器来约束全局形状。
Chibane提出了一种是通过各种3D输入实现三维形状重建和补全,是提取三维多尺度张量,而不是单个向量来编码人体的三维形状。
IF-Net:利用预测的2.5D草图从单个输入图像回归到像素对齐的隐函数来重建人体。
3、点云表示。
三维点云提供了一个有吸引力的替代表示三维几何。点云被表示为一组三维点,其中每个点是其(x, y, z)坐标的向量加上额外的特征通道,如颜色或法线。
但是点云的问题是,不规则的结果,点不是均匀分布在物体、场景的不同区域。
三种类型:
一个点云表示,将一个点云作为一个大小为N × 3的矩阵。
包含一个或多个3通道网格的表示。网格中的每个像素编码3D点的(x, y, z)坐标;
从多个视点提取深度图的表示。
从单个RGB图像重建三维点云:
提出了一种结合局部和全局的表示方法来学习详细的三维潜在表示。该框架提出了一个 RGB图像编码器,然后是一个点云解码器和一个3D姿势解码器,以重建逼真的完整3D点云。
PointNet:它直接使用非结构化和无序的点云,该
方法对每个点进行空间编码,然后对每个点的高维局部特征进行聚合从多层感知(MLP)中指向全局点云。
还有用PointNet++方法和SMPL模型相结合的方法:使用PointNet++在分层迭代中从点云中提取特征,以确定 SMPL参数以获得3D网格。
Lunscher提出了一种在只提供单一输入深度图图像的情况下,使用深度学习模型来完成点云扫描。该方法以人的正面或背面的深度图图像作为输入。它从与输入相机相同的姿势合成身体对面的点。(值得注意的是,视点的灵活性是在距离和角度范围内的任何地方,不需要扫描设备需要校准或精确安装)
Gabeur提出:使用双深度图来表示
人的3D形状:可见深度图和“隐藏”深度图。该系统集成了编码器-解码器体系结构,将单个图像作为输入,并同时产生两幅深度图的估计。这些深度图被组合起来,以获得整个3D表面的点云。

多个视图中使用的技术
多视图三维重建是对从不同视点拍摄的一系列图像所捕获的场景或物体的几何结构进行推断.被采纳的依赖于人体参数模型的方法通常试图估计普通 RGB图
像的姿态和形状。该方法不依赖于任何参数化的人体模型,主要利用深度相机获取的RGB- D图像进行三维重建。

基于参数回归的模型
Octopus:这是一个基于学习的模型,可以从单目视频的几帧中推断出3D形状。该方法预测SMPL身体模型参数(剪影和姿态),加上额外的3D顶点模型服装、头发和SMPL空间之外的细节。
Bhatnagar:对之前的方法进行了改进,通
过预测服装几何形状,将其与体型联系起来,并将其转化为新的体型和姿势。这种方法将人体和分层服装直接从图像中分离出来,从而可以学习从图像到人的多层表示的映射。
一种新颖的基于关节点和轮廓的方法来估计 3D 人体姿势和形状:基于参数化模型的结合点和轮廓。在方法的初始阶段,参数化模型拟合了基于 cnn的人体姿态估计方法预测的关节点。然后,利用轮廓来改进形状估计。通过拟合和拟合,预测的姿态和形状参数生成最终的三维人体模型。该方法的最大优点是将人体姿态的
估计与人体外形的改善相结合。
以下方法解决严重遮挡问题:
DeepMultiCap:将像素对齐隐函数与参数化模型相结合,实现了不可见表面积的稳健重建.设计了一种基于自注意机制的多视图特征融合方法,以自适应地聚合来自多视图输入的信息。
Dong等人提出的:将2D的噪声数据聚合到3D空间中。然后将它们与基于信任意识的多数投票技术的个别实例相关联。
优化拟合时间、精读低、深度信息模糊等问题。
Pixel2ISDF:它使用SMPLX模型的几何先验来学习一个隐式函数来重建人体。方法通过普通网格和几何网格提取SMPLX网格中每个顶点的特征向量。利用多幅图像中每个顶点的特征,通过预测权值和变换后的特征的MLP来整合特征。另一个MLP用于将加权特征合并到潜码中,并将其固定在规范空间的SMPLX网格上。最后,使用SparseConvNet生成每个三维点的有效特征
多视图卷积神经网络

一般分为两种:一视图一网方法、多视图一网方法。
一视图一网方法:每个视图采用一个卷积神经网络,分别获取每个视图的特征表示。然后通过网络后端或融合方法融合多特征表示。例如Zeng提出的多特征融合方法,将多视图特征与三维形状特征进行融合,并应用于非刚性三维模型检索。Wang等提出的通过结合有序视图特征对该方法进行改进,实现了面向方向的三维人体姿态分类和检索。该方法将视图池层改为有序视图特征融合(Ordered View FeatureFusion, OVFF),根据视图的顺序进行特征融合。
Multi-view Pose:该方法可以直接回归多人 3D姿势,而不需要依赖中间任务。为了做到这一点,MvP将多视图特征表示作为输入,并将其直接转换为一组联合3D位置。
多视图一网方法:多视图数据直接输入到网络中,以获得一个单一的最终表示。例如 Huang 引入了一种多视角CNN,将二维图像映射到三维体场,对曲面点的概率分布进行编码。
Gilbert 等人提出了一种卷积
自动编码器架构,用于人体的高保真体积重建,仅包含有限的相机视图集。
Smith提出了一种独特的方法来
从一对图像中产生高度准确的人形测量,来重建3D身体形状。
Putra提出了一种包含预训练 CNN、注意层、
RNNs层和多输入输出分数融合层的DNNs 模型。
MMT提出了一种多视图人体网格翻译模型,利用视觉变换对人体表面进行估计。第一阶段,利用卷积图像编码器从多个视图获取全局特征特征;然后,利用
多视图融合变压器对编码后的特征进行融合,得到上下文化的嵌入。最后,通过多层变压器对人体网格进行编码。
多视图CNN架构涉及到早期或晚期的融合,以组合多
个输入。
非参数回归模型
在多视图三维重建中,其他广泛使用的方法是基于非参数三维回归,它利用深度神经网络,仅从输入数据中获得信息,而不依赖参数形式。这些模型并不是没有参数,因为只要参数的数量是灵活多变的。
SFS:最常用的估计物体形状的方法之一,,这是一种利用剪影分割扩展基于体素的Sfs方法的新方法。执行二维身体分割证明了对轮廓估计失真的鲁棒性。这种方法可以用于除了其他重建方法填补空腔在一个点云的人体。
一种类似的方法来组合和检索来自多个校准摄像机的 3D姿态。一个亲和度之间的三维检测从不同的观点被用来保证几何确定性一致性。这种相似性被输入匹配算法来分组不同的多视图检测。
(对单视图隐函数方法的改进)基于多阶段端到端神经网络提取的多尺度特征的多视图方法,第一步,将
图像输入具有多个端到端沙漏网络的模型,提取多尺度特征随后,该作者改进了之前的方法,引入了体素超分辨率 (voxel super-resolution, VSR)步骤,对隐式函数的结果进行细化,生成更详细的最终3D重建。
VSR使用多尺度框架从低分辨率体素网格
中提取特征,并使用隐式表示生成最终的 3D模型。
PIFusion(PIfu的变体):作者提出了一种利用单个RGB-D摄像机进行非刚性融合的新方法。它最初使用神经网络从第一个RGB-D帧推断出一个近似模型。在接下来的几帧中,使用推断模型进行非刚性跟踪,将观测结果融合到TSDF卷中。
一种类似于PIFu的简化技术,可以从单目视频中实时绘制人体的三维模型。为此,他们开发了一种表面定位算法,可以查询从粗到细的3D位置,以尽可能少的点构建职业领域。
Yenamandra提出了一种不同的策略来推断头部的隐式3D变形模型。这种方法首先捕获整个头部区域,包括变形和头发外观。创新在于一种新的神经网络架构,将学习过程解耦为学习参考形状、几何变形和颜色网络。
NeRF(神经辐射场):该方法涉及从稀疏的2D图像集捕获的部分观测中学习3D场景的表示。一个场景,在一个有边界的3D体上定义了一个体辐射场。该方
法利用简单的多层感知器网络对以连续5D坐标为输入,以体积密度和发射亮度为输出的空间位置映射进行编码。

VGP(Voxel Grid Performer):它提出
了一种基于网格的体素表示,用于人类视觉合成。在这种方法中,稀疏网格被设计成表示密度和颜色,以实现更好的性能和更少的计算量。
其他基于NERF的人体三维重建方法也被提出:FLAME-in-NERF,用于任意面部表情控制和肖像视频合成。
GM-NeRF:这是一种将 Generalizable models 与 neuralradiation fields整合在一起的Generalizable framework。GM-NeRF通过图像编码器提取多视图图像特征。利用这些特征给出几何和外观信息。将几何和外观编码输入MLP网络,建立神经特征场。
隐函数或神经辐射场,都可以表示复杂的几何形状和外观。然而,基于神经辐射场的方法具有更强的优越性和更紧凑的结果。它的显著优点是克服了离散体素
网格在高分辨率重现复杂场景时的存储成本。
数据集
BUFF:使用主动多摄像机立体系统
以60帧每秒的速度获取全身 3D扫描的时间序列。公共数据集包含11054个3D网格,大约有150000个顶点。
Human3.6M:包含从四个不同视点获取的 360万个精确的3D
SURREAL:它为在形状、纹理和姿态的广泛变化下呈现的模型提供了 SMPL形状和姿态参数。这个数据集包含了 600万帧人造人。
Von Marcard:提出了一个类似的数据集,不同之处在于它是在室外条件下捕获的,使用 IMU 传感器来计算网格的姿态和形状。(私有)
FAUST:公开了一个由廉价RGB-D传感器获得的网格的公共数据集。该数据集包含300张高分辨率三角形的人体扫描图。唯一的缺点是纹理贴图,这不是高质量的足够逼真的渲染。
讨论
目前,有不同的方法和策略可以从单个或多个图像进行人体三维重建。为了选择最适当和最准确的技术,必须考虑以下特点:
•输入图像类型;
•输入图像数量;
•表示类型;
•输出模型的分辨率;
•网络架构。
1.有必要考虑每种方法的优缺点以及额外信息的使用,如相机姿态参数。
2.参数化模型允许您通过修改模型的参数和尺寸来更改。
3.由于深度神经网络的重大发展,各种三维表征的非参数模型被用于改进人体三维重建方法。基于非参数方法的方法能够提供更精确和灵活的预测,因为它们
能够更好地适应输入数据,并且可以针对各种输出表示进行调整。
4.隐式表示最有希望,因为它简化了深度学习表示法,并在新架构和算法、鲁棒性分析和设计、可解释性、稀疏性和网络架构优化方面提供了许多新选项。
5.点云表示方法在人体三维重建中也得到了广泛的应用,但它们不允许简单的表面渲染和可视化。这些限制是它们很少使用的主要原因。
因此,选择最佳的表示对最终重建的质量至关重要。
单视图重建的一个相当大的挑战是,从单个图像推断不可见的部分和丢失的三维物体的信息。对于融合多信息的最普遍的方法,大多数作者使用卷积神经
网络。
综上所述,本研究中提到的所有方法都可以扩展到各个研究
领域。虽然直接应用整个重建算法可能是不可行的,所提供的方法可以扩展到重建不同的对象或完整的场景。这可能是必要的调整模型与数据集适用于特定场景的3D重建。
结论和展望
到目前为止,3D人体重建已经进入了一个可以从单视图或多视图检索精确、高分辨率人体模型的时代。然而,未来科学界还必须解决其他问题和进展。
•目前,基于单独训练人体模型的三维重建方法多种多样,训练时间往往相当长。然而,只有一些研究人员解决了多人问题,即在同一场景中创建多
个人体的三维模型。这导致需要为多人和人-物交互开发有效的表示和可泛化的算法。
•虽然可以复制详细的3D人体模型,但它们需要逼真的图像。然而,获得高质量的图像需要昂贵的捕获硬件和大量的渲染时间。Karras开发了一种神经绘制方法,在生成高质量图像方面取得了令人印象深刻的结果。为人体几何和未知物体开发更可控的神经绘制方法是一个令人兴奋和基本的方向。
•另一个需要考虑的改进是开发3D表示的质量指标,以获得数据的定性评估。虽然存在几种评估指标,但它们无法将 3D表示与任意连接性或不同的
采样密度进行比较。在这方面,开发一个有价值和准确的度量是必要的,以捕获模型之间的拓扑和视觉差异。
总结
本周我找了一篇 从单视图和多视图图像重建人体:系统综述;他是把现在三维重建方法分类成单视角,多视角两类;在单视角里面有分为基于参数化人体模型的回归(代表的就是与SMPL模型)和非参数化人体模型回归;而基于非参数化人体模型的回归有一下三种方法:
1.体积表示
2.隐式表示
3.点云表示
多视角:基于参数回归的方法,使用卷积神经网络的基础上一系列方法,还有非参数回归方法:SFS、多尺度特征的多视图方法、PIFusion,及一些对单视图方法的改进。
数据集主要是用凯撒数据集、Human3.6m、SURREAL、FAUST一些公共开源数据集。
最后结论是选择最好的重建方法是对最后的质量有最关键的作用,但是要根据内存的限制、分辨率、容量等诸多因数综合决定使用那种方法。
Python基础学习
python
最重要的是缩进
变量,字符串,原始字符串,长字符串
- (如无必要,勿增实体)
- 里面变量不能以数字开头
- 单引号、双引号、三引号
- 转义字符都是以反斜杠开头

-
\路径里面的双斜杠,就是用反斜杠来转义反斜杠!
-
在字符串前面加一个原始字符r,表示字符串后的反斜杠都是字符,而不是转义字符
-
字符串最后是反斜杠,说明表示未完待续,程序不会执行,可以继续写
-
字符串也可以作乘法输出

条件分支、while循环
- int()
- if 条件:
- else:记住后面都有冒号哦!
-

- is 、is not 判断两个对象的id是否相等的
- Python3 中,一行可以书写多个语句=》;
- 也可以多行写一个语句,用反斜杠就可以 \
- while_条件:
- 语句
python逻辑运算符
- and 从左到右计算表达式,若所有的都为真,则返回最后一个值,若存在假,返回第一个假值.同时也是与的逻辑作用 遇假出假
- or 从左到右计算表达式,只要遇到真值就返回那个真是,如果表达式结束依旧没有遇到真值,就返回最后一个假值.同时也是或的逻辑作用 遇真出真
- 以上也叫做短路逻辑(short-circuit logic)
- not 取反,非逻辑作用
- (10 < cost) and (cost < 50)等价于 10 < cost < 50
- random.getstate() random.setstate
数字类型
int
python里整除了,最后结果还是以浮点数形式存在

foalt
-
python中小数是以浮点数形式存放的
-

-
精确计算浮点数
-
decimal.Decimal()实例对象
-
比较的时候还是要用同一对象进行比较,不能用0.3直接和decimal对象比较,那是不同对象的,会报错。
-

-
python科学计数法,e表示10的幂次方
-
将数字转换为科学计数法
num = 123456789
print(“{:.2e}”.format(num)) # 输出为1.23e+08

那个{:.xe}x是表示小数点后几位数字
复数

- python是向下取整,int(5.5)=5
- 取变量类型用instance()、type()
数值运算

- //地板除
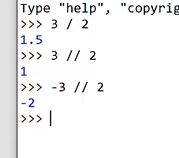
 - [ ] 用int转换小数字符串的时候,会截断
- [ ] 用int转换小数字符串的时候,会截断

- pow (x,y,z) y可以为负数,就做log函数,还有z是求余的运算。

布尔类型
- 值为false

- 可以这样理解,bool类型是特殊的整数类型
- python所有对象都能进行真值测试
运算优先级

- 当学生只能硬记,由上至下,优先级越高!
流程图

思维导图
分支和循环
- 条件表达式

- 用一个小括号来把代码封起来,等价于\实现多行代码连续输入。
分支结构嵌套
-

-
while break 跳出循环体
-
continue 跳出本次循环,回到循环体
-
while else 语句:当循环完整结束后会执行 else

-
break和continue都是作用于最小循环
for
- for in中的可迭代对象
- range
是生成一个数字序列,其参数必须是整型。

列表

- 注意最后的,还可以倒序输出。
- 增 :append()、 extend()

- 也可以使用切片的方法去做

和extend的原理一样 - insert( x,y) x插入的位置,y是插入的元素
-

- 删除: remove()但是有多个匹配的元素,只会删除第一个,如果没有匹配到,就会报错。
- pop() 删除 某个位置的元素
- clear()清空
-

- 列表元素的替换:

- 列表排序:sort()从小到大排序

或者在sort(reverse=True)直接在sort里翻转 - 列表反转:reverse()
- index() 索引 index(a,b,c) a是元素内容、bc分别表示起始位置
 - [ ] 可以通过该方法替换未知索引的内容
- [ ] 可以通过该方法替换未知索引的内容

- count() 计算列表里有多少该元素
- copy()浅拷贝
-
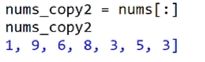
- 负数索引表示从数组的末尾开始往前数的元素


- 列表 加法 乘法

- 嵌套列表
- 嵌套列表输出

- 只给一个下标索引,给出的是以行为单位的整个列表
- 初始化列表

- is判断两个变量是不是指向的同一对象。
- 若字符串是相同,则两个对象是指向的同一对象;而列表不是。
-

为什么不能用B=[ [ 0 ] * 3 ] *3来初始化列表
如下图:

- 在python中,变量不是盒子,是引用
- 我们要真正获得两个独立的列表,就需要用到copy()或者切片

在C++中类似,不能对数组进行直接复制,拷贝,只能通过for循环,对数组中每一个元素逐个进行复制。
浅拷贝和深拷贝
-
在面对多维列表的时候,在使用copy就不行了,因为浅拷贝只是对外围数据进行拷贝,对内层数据还是以引用形式存在的。
-

-
copy模块 import copy
-
copy.deepcopy()深拷贝
-
copy.copy()浅拷贝
python虚拟机 pvm
列表推导式(用的c语言进行的)
- 结果是一个列表

- 其执行顺序为 先执行for 的迭代 ,然后再执行,for后判断语句。

- 嵌套的列表推到式

- 可以用嵌套的列表推导式来表示笛卡尔乘积,每个for后面都可以加一个if来进行条件筛选
-

KISS原则
要保证代码简洁好看,不介意多行列表嵌套式,容易看不懂
元组tuple
不可逆的、圆括号、也可以不带括号、也支持切片操作
-
count、index()
-
支持拷贝

-
支持嵌套


生成一个元素的元组:x = <520,> -
打包和解包:一堆数据生成一个元组称为元组的打包,用一个元组对几个变量进行赋值,称为解包。打包和解包用于所有序列。注意解包的时候,需要左右两边的变量数量要一致。
-
除非用以下这个方式:
-

_:表示匿名变量
python中多重赋值就是这样的来的。

元组中的元素是不可变的,但是元组中的元素如果指向的是可变的元素,那就可以改变。如下:

字符串
- 用切片来实现回文数的查找
-

字符串里的方法:

capitalize()将字符串首字母大写
title()各单词首字母大写
swapcase()将原字符串大小写翻转
upper()将所有字母都大写
lower()将所有字母都小写
casefold()小写,并且可以处理其他语言

center(w)w>字符串长度则,将其居中。小于则直接输出。
ljust左对齐
rjust右对齐
zfill()字符串前面补0,不是单纯的补,如果字符串前面有符号,在前面也会有符号站位

count(a,b,c)bc分别是指定的查找位置参数
find()rfind()从左往右、从右往左找
index()找不到就抛出异常

- 使用空格来替换制表符,返回一个新的字符串
- replace(old,new,count==-1)指定新字符串替换旧字符串,count默认为-1,即为替换全部

配合str.maketrans()使用,相当于是在里面生成了一个转换规则。
依照这个转化规则执行:

还可以再加一个参数,将指定的字符串忽略掉
序列
** + * **
在python中,每一个对象都有三个属性:唯一标志、类型、值。
id()返回一个代表指定对象的唯一标识的整数值
对于不可变的序列类型,使用增量赋值的时候,其唯一标志就会改变。

is is not
判断对象是否是同一对象
in not in
判断对象是否包含在序列中

del
删除指定对象
可以删除可变序列中的指定元素

记住清空内容和清空这个序列对象的区别哦!

可迭代对象直接转为列表
min()max()输出可迭代对象的最小和最大值,如果是字符串,那就是比较各个字符的编码值,大写字母的编码值是在小写字母编码之前的。
遇到空对象,就需要设置default的值
len()函数有个问题是有最大值上限:2*63-1的长度
sum(x,z)z是指定参数 从z开始相加
sorted(x,reverse,key) 返回的是新的序列 key参数是排序的方式
比如key=len

t.sort是对整个序列进行排序,对每个元素先执行len(),求出字符串长度,然后由长度从大到小排序。
reverse() 是返回的迭代器,可以在reverse()的基础上,在外加一个list()就可以了

all()判断某个序列中是否所有元素都为真
any()判断某个序列中是否存在一个元素为真
**enumerate(a,b)**返回一个二元组,b是二元组索引下标起始位置
zip()
相同长度的序列进行组合

当面对相同不同长度的序列时,取最小值的那个,类似木桶原理;
如果要取最大值的,导入itertools模块;
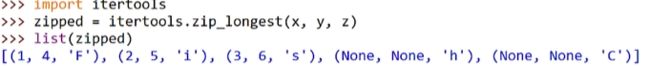
**map(x,y,z)**x是操作,y,z分别是两个序列,对y,z序列中每对元素进行x操作;比如:

还是执行的同样的木桶原理,按序列长度最小值来确定;返回的还是迭代器,所以要用list()进行转换
** filter** 过滤器

![]()
第一个参数用于过滤的函数,第二是序列,只有判断结果为true才会输出。
可迭代对象和迭代器
一个迭代器肯定是一个可迭代对象,最大的区别就是可迭代对象是可以重复使用的,而迭代器是一次性的;
返回迭代器对象:reversed()、enumerate()、zip()

iter(x)能够返回一个以x的数据的迭代器。其类型是list_iterator。
next()对迭代器进行迭代;

当其中没有元素后,就会抛出异常。
也可以添加第二个参数,当next()掏空迭代器后,就抛出参数

字典
通过指定一个不存在的键,就可以创建一个新的键值对
键是不能重复的,是与序列的本质区别

创建字典的方法:

- { }
- dict()不能对键的关键字进行加引号
- dict([k,v],[k,v],[k,v]…)里面使用列表
- dict({ })
- dict(混合)
- 使用zip函数,因为zip函数返回的是一个迭代器
增
fromkeys():创建后续以第一个参数为键,第二个参数为所有相同的值的字典。

改
d[‘x’] = “ y”
update()可以直接传入一个字典,对原字典进行覆盖
删
pop(key[,default])返回的是指定的键和值

default是返回一个不存在的键的默认值。
popitem()弹出最后加入的键值对,在3.7版本之前,字典里的键值对的顺序是没有保证的,而3.7版本之后,字典里面的键值对有了先后加入的顺序
del()函数也能完成删除操作
clear()也可以进行清空操作
查
get(x,y) y是当找不到x键的时候返回的值
setdefault(x,y)当字典中存在x键的时候,返回对应的值,但是如果不存在x的键,就返回y值,并且在原有字典中添加x->y键值对

视图对象:

dict.keys dict.values dict.items

len(d)返回d字典键值对的数量
in
not in
list(d)得到字典中所有键构成的列表
iter(d)得到由字典的键构成的迭代器
reversed()对字典的键进行反转,适用于3.8以后的版本
嵌套
字典也是可以进行嵌套的;
嵌套不仅可以嵌套字典类型、还可以嵌套列表

字典推导式
键值互换:

字符串生成字典:

推导式两个for循环,如果和列表一样的话,就应该生成一个3*3的嵌套列表,但是在字典中,键是唯一的,因此只保留最后一个每次只保留最后一个循环的键值对,1>6;3>6;5>6;

集合
集合中的元素都是独一无二的,并且也是无序的
建立
- {}
- 集合推导式:

- set()类型构造器
会生成一个无序的集合,不能使用下标进行访问
但是可以使用in 或者 not in判断某个元素是否在里面
结合len(),可以对一个列表判断其中元素是否唯一:
len(s) == len(set(s))
如果一个列表的长度和他转化为集合的长度是一样的,那么就说明其中每个元素都是唯一的
s.copy() 浅拷贝
s.isdisjoint()判断两个集合之间是否有交集,有交集则返回False
issubset()判断一个集合是否是另一个集合的子集
issuperset()判断一个集合是否是另一个集合的超集
并、交、差(以下三个可以有多个参数)
union()返回一个新的并集
intersection()返回两个集合的交集
difference()返回存在调用该函数的集合且不存在()里面的集合
对称差集:

sysmmetric_difference() 只能单参数
\ > <都可以用于集合包含关系的判断,
| 并集
&交集
-差集
^对称差集
需要注意的,使用上述方法,只要是可迭代对象就可以使用,但是对于运算符而言,两边只能是集合
frozenset 不可变集合
update(*others)表示支持多个参数,如果是other就只能一个参数。
更新集合。

以上的函数,当集合调用的时候,会对调用的集合进行改变
add():如果插入一个字符串的话,是将整个字符串作为一个整体插入到集合中;而update插入字符串,是将字符串拆开成为几个字符分别插入进去。
删除:
remove():当删除一个不存在的元素,则会抛出异常
discard():当删除一个不存在的元素,静默处理
pop()随机弹出一个元素
clear()清空
可哈希
只有可哈希的值才能作为字典的键或者集合的元素,判断一个元素能不能哈希: hash(x),整数的哈希值就为它本身,如果两个数据相等,只是不同的数据类型 比如1和1.0,他们的哈希值也是相等的。
列表是可变的,因此它就不能哈希;元祖是不可变的,它就可以哈希。集合也是不可哈希的。因此直接进行集合的嵌套是不行的,因为集合中的元素和字典中的键是一样的,都是应该能够哈希的。
如果要实现一个集合的嵌套,就在用frozen()生成子集合,在放入需要嵌套的母集合中去,就实现了集合的嵌套。

集合的查找效率是比列表快很多的,背后是以后散列表的存在,但是牺牲了海量的存储空间来实现的,因此就符合了空间换时间、时间换空间。
函数
定义一个函数和调用


 函数的返回值可以用return返回
函数的返回值可以用return返回

形参和实参

关键字参数
 默认参数(即形参中给定默认值,则在未给实参时会以默认值输出)
默认参数(即形参中给定默认值,则在未给实参时会以默认值输出)
收集参数

函数与过程

函数变量、作用域

函数里面修改全体变量可在函数内部修改,可是在函数外面,全体变量仍是原值
函数内嵌

闭包
>>> def funX(x):
def funY(y):
return(x*y)
return funY
>>> funX(5)
<function funX.<locals>.funY at 0x00000210D0C7C158>
>>> type(funX(5))
<class 'function'>
>>> funX(8)
<function funX.<locals>.funY at 0x00000210D0C7C1E0>
>>> i=funX(5)
>>> i(5)
25
>>> funX(5)(6)
30
>>> funY(8)
Traceback (most recent call last):
File "" , line 1, in <module>
funY(8)
NameError: name 'funY' is not defined
>>> def fun1():
x=5
def fun2():
return (x *= x)
return fun2()
SyntaxError: invalid syntax
>>> def fun1():
x=5
def fun2():
x *= x
return x
return fun2()
>>> fun1()
Traceback (most recent call last):
File "" , line 1, in <module>
fun1()
File "" , line 6, in fun1
return fun2()
File "" , line 4, in fun2
x *= x
UnboundLocalError: local variable 'x' referenced before assignment # 局部变量不可修改全局变量
解决方法如下:s
>>> def fun1():
x=[5] #x=【5】//下一步x【0】就是5,前提就是首先令x为组
def fun2():
x[0] *= x[0]
return x[0]
return fun2()
>>> fun1()
25
第二种方法
>>> def fun1():
x=5
def fun2():
nonlocal x #说明它不是局部变量就可覆盖上面的x
x *= x
return x
return fun2()
>>> fun1()
25
lambda表达式
Lambda表达式
一个参数
>>> def ds(x):
return 2*x+1
>>> ds(5)
11
>>> lambda x:2*x+1
<function <lambda> at 0x00000210D0C7C2F0>
>>> g=lambda x:2*x+1
>>> g(5)
11
两个参数
>>> lambda x,y :x+y
<function <lambda> at 0x00000210D0C7C2F0>
>>> z=lambda x,y:x+y
>>> z(3,4)
7
Filter过滤器
>>> filter(None,[1,0,False,True])
<filter object at 0x00000210D0C59D30>
>>> list(filter(None,[1,0,False,True]))
[1, True]
>>> def odd(x):
return x%2
>>> t=range(10)
>>> show=filter(odd,t)
>>> list(show)
[1, 3, 5, 7, 9]
>>> list(filter((lambda x:x%2),range(10)))
[1, 3, 5, 7, 9] /过滤出奇数
>>> list(filter((lambda x:x%2-1),range(10)))
[0, 2, 4, 6, 8] /过滤出偶数
Map()函数
>>> list(map(lambda x:x*2,range(10)))
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18] //生成0~9数字
递归
>>> def recursion():
return recursion()
def jieceng(n):
t = 1
for i in range(1,n+1):
t *= i
return t
number = int(input("输入正整数:"))
jieceng(number)
#print("输入正整数的阶层是:",jieceng(number))
print("%d的阶层是%d" % (number,jieceng(number)))
def jieceng(i):
if i == 0:
return 1
elif i == 1:
return i
elif i != (0 and 1):
return i * jieceng(i-1)
y = int(input("请输入整数:"))
t = jieceng(y)
print("%d的阶层为%d"%(y,t))
部分字符串方法含义
capitalize() 把字符串的第一个字符改为大写
casefold() 把整个字符串的所有字符改为小写
center(width) 将字符串居中,并使用空格填充至长度width的新字符串
count(sub[,start[,end]]) 返回sub在字符串里边出现的次数,start和end参数表示范围,可选
encode(encoding=‘utf-8’, errors=‘strict’) 以encoding指定的编码格式对字符串进行编码
endswith(sub[,start[,end]]) 检查字符串是否以sub子字符串结束,如果是返回True,否则返回False。start和end参数表示范围,可选
expandtabs([tabsize=8]) 把字符串中的tab符号(\t)转换为空格,如不指定参数,默认的空格数是tabsize=8
find(sub[,start[,end]]) 检测sub是否包含在字符串中,如果有则返回索引值,否则返回-1,start和end参数表示范围,可选
index(sub[,start[,end]]) 跟find方法一样,不过如果sub不在string中会产生一个异常
isalnum() 如果字符串至少有一个字符并且所有字符都是字母或数字则返回True,否则返回False
isalpha() 如果字符串至少有一个字符并且所有字符都是字母则返回True,否则返回False
isdecimal() 如果字符串只包含十进制数字则返回True,否则返回False
isdigit() 如果字符串只包含数字则返回True,否则返回False
islower() 如果字符串中至少包含一个区分大小写的字符,并且这些字符都是小写,则返回True,否则返回False
isnumeric() 如果字符串中只包含数字字符,则返回True,否则返回False
isspace() 如果字符串中只包含空格,则返回True,否则返回False
istitle() 如果字符串是标题化(所有的单词都是以大写开始,其余字母均小写),则返回True,否则返回False
isupper() 如果字符串中至少包含一个区分大小写的字符,并且这些字符都是大写,则返回True,否则返回False
join(sub) 以字符串作为分隔符,插入到sub中所有的字符之间。>>> str5 = ‘Fishc’ >>> str5.join(‘12345’) ‘1Fishc2Fishc3Fishc4Fishc5’
ljust(width) 返回一个左对齐的字符串,并使用空格填充至长度为width的新字符串
lower() 转换字符串中所有大写字符为小写
lstrip() 去掉字符串左边的所有空格
partition(sub) 找到子字符串sub,把字符串分成一个3元组(pre_sub,sub,fol_sub),如果字符串中不包含sub则返回(‘原字符串’, ’’, ’’)
replace(old,new[,count]) 把字符串中的old子字符串替换成new子字符串,如果count指定,则替换不超过count次。>>> str7 = ‘i love fishdm and seven’ >>> str7.replace(‘e’,‘E’,2) 输出’i lovE fishdm and sEven’
rfind(sub[,start[,end]]) 类似于find()方法,不过是从右边开始查找
rindex(sub[,start[,end]]) 类似于index()方法,不过是从右边开始
rjust(width) 返回一个右对齐的字符串,并使用空格填充至长度为width的新字符串
rpartition(sub) 类似于partition()方法,不过是从右边开始查找
rstrip() 删除字符串末尾的空格
split(sep=None, maxsplit=-1) 不带参数默认是以空格为分隔符切片字符串,如果maxsplit参数有设置,则仅分隔maxsplit个子字符串,返回切片后的子字符串拼接的列表。>>> str7.split () [‘i’, ‘love’, ‘fishdm’, ‘and’, ‘seven’]
splitlines(([keepends])) 按照‘\n’分隔,返回一个包含各行作为元素的列表,如果keepends参数指定,则返回前keepends行
startswith(prefix[,start[,end]]) 检查字符串是否以prefix开头,是则返回True,否则返回False。start和end参数可以指定范围检查,可选
strip([chars]) 删除字符串前边和后边所有的空格,chars参数可以定制删除的字符,可选
swapcase() 翻转字符串中的大小写
title() 返回标题化(所有的单词都是以大写开始,其余字母均小写)的字符串
translate(table) 根据table的规则(可以由str.maketrans(‘a’,‘b’)定制)转换字符串中的字符。>>> str8 = ‘aaasss sssaaa’ >>> str8.translate(str.maketrans(‘s’,‘b’)) ‘aaabbb bbbaaa’
upper() 转换字符串中的所有小写字符为大写
zfill(width) 返回长度为width的字符串,原字符串右对齐,前边用0填充