Redis原理篇(ZipList压缩列表)
一 :ZipList概述
1.基础结构
ZipList是一种特殊的“双向链表”,但其实并不是链表,而是一段连续的内存空间,可以在任意一端进行压入/弹出操作。并且该操作的时间复杂度是O(1)
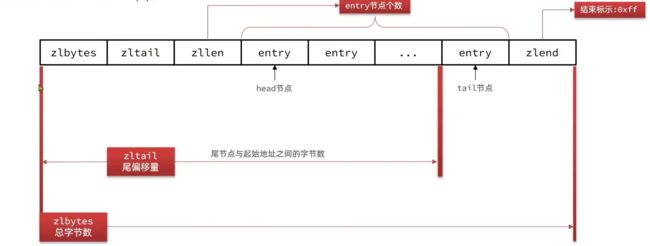
结构如下图:
![]()
现在对每一个部分进行解释:
zlbytes:存该压缩列表的总字节数,byte即字节
zltail:存最后一个节点到压缩列表的其实地址之间的字节数
zllen:存的是总entry的个数
entry:即节点
zlend:压缩列表的结束标志,并且值是固定的:0xff
这里补充一点进制基础:
(1) 0x表示这是16进制数;
(2) 16进制的每一个16进制位可以表示二进制的4个比特位,8个比特位即一个字节。
因为一个比特位有1和0这两种可能,4个比特位就是2的4次方,即能表示0到15这16个不同的值,刚好就是16进制的一个16进制位能表示的值。
(3) 所以用16进制来表示2进制能使二进制数据更紧凑。
结合下图更容易理解:
下图是每个部分所占字节数: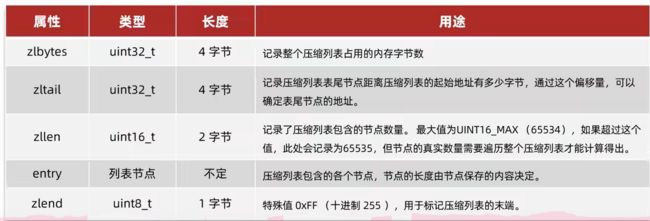
有没有注意到一个问题,为什么这里的entry的长度是不确定的?
像数组,只要确定了数组的类型,就能知道其每个节点所占字节数,为什么这里的不确定的呢?
这就需要我们来聊聊entry的结构了 。
2.压缩列表中entry的结构
Ziplist的entry不像普通双端链表那样记录前后节点的指针,因为记录2个指针要16个字节,比较浪费内存。
Ziplist中的entry采用的如下的结构:

previous_entry_length:存前一个节点的总字节数,占1或5个字节。
- 如果前一个节点的长度小于254字节,就采用1个字节来保存这个长度值, 因为1个字节8个比特位,能表示(2的8次方-1)的值。
- 如果前一个节点的长度大于或等于254字节,则采用5个字节来保存这个长 度值,并且第一个字节是0xfe,后四个字节才是真实长度数据
encoding:存该节点的内容的编码,用来区分content是(自负床还是整数),并且存了 content的长度,占1,2或者5个字节稍后有详细解释
content:存该节点的数据,可以是字符串或整数。
3.压缩列表怎么双向遍历?
压缩列表的entry既然没有存前后2个节点的指针,那么怎么双向遍历呢?
3.1 正序
先说正序:正序时,已知当前entry的起始地址,要知道当前节点的下一个节点,前面有提到过,压缩列表是连续的一片内存空间,所以只要将当前节点的起始地址加上该节点总占字节数()即可,那这个当前节点所占字节数怎么算呢?
节点所占字节数 = previous_entry_length所占字节数 + encoding所占字节数 + encoding里面的所存content的长度
也就是三个部分的字节数相加,只不过content所占字节数要通过encoding里面获取。
3.2 逆序
再说逆序:逆序时,已知当前entry的起始地址,只要用当前entry的起始地址减去previous_entry_length就是前一个节点的起始地址了。因为previous_entry_length存的就是前一个节点总占字节数。
4.encoding编码
4.1 字符串

前面2个比特位用来标记该content是字符串,以第一种为例
00标记该content是字符串,剩余6位存content的所占字节,2的6次方-1是63,所以content的长度最大值是63个字节。
这样说可能不太清楚,举例说明:
现在我们要存“ab” 和 “cd”这两个字符串,即第一个节点存ab,第二个节点存cd
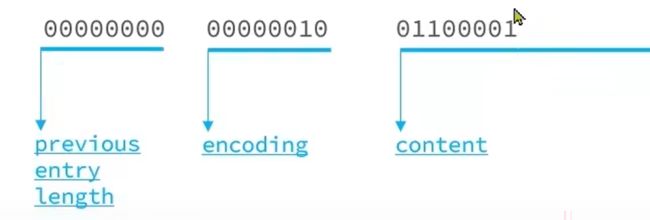
首先存ab:
previous_entry_length:
因为这是第一个节点,所以前一个节点的所占字节数为0
所以previous_entry_length = 00000000
encoding:
因为ab是字符串,并且字符串ab所占字节数为2,所以前2位是00,占字节数是2,
所以encoding =00000010
content:a的ASCII值是97,就是二进制01100001;
b的ASCII值是98,就是二进制01100010.
所以存在entry中是这样的
转化成16进制是这样的:
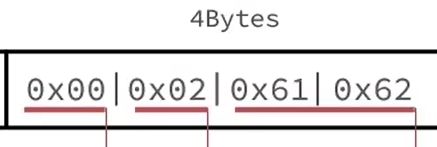
然后来存cd:
previous_entry_length:
这是第二个节点,前一个节点的总占字节数为1+1+2=4
所以previous_entry_length = 00000101
encoding:
因为cd是字符串,并且字符串cd所占字节数为2,所以前2位是00,占字节数是2,
所以encoding =00000010
content:c的ASCII值是99,就是二进制01100010;
d的ASCII值是100,就是二进制01100011
所以存在entry中是这样的

所以整个ziplist是这样的

4.2 整数
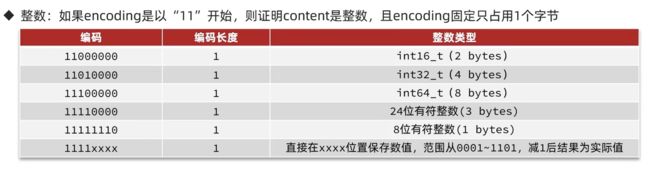
如果encoding是以11开始,就表示content存的是整数