【Spring源码分析】扫描并注册BeanDefinition逻辑
扫描并注册BeanDefinition逻辑
- 一、ClassPathBeanDefinitionScanner 扫描源码分析
-
- doScan 扫描的具体逻辑
-
- findCandidateComponents 方法解析
- generateBeanName 方法解析
- checkCandidate 方法解析
- 二、总结
| 阅读此需阅读下面这些博客先 |
|---|
| 【Spring源码分析】Bean的元数据和一些Spring的工具 |
| 【Spring源码分析】BeanFactory系列接口解读 |
扫描源码一般是接触Spring源码时大家首先去接触的,因为它是去扫描且过滤出符合的条件的Bean的元数据的(注意这里说的是Bean的元数据,并非全是类的元数据,在此过程中用了ASM技术去提取类的元数据进行操作),比如满足includefilter,不是接口,抽象类等等才会被加入候选…
这当然也是我看源码时首先看的,但是我自己分析做的笔记呢,只是在本地,其实很多都是在本地写 typora 的,比较快,写 CSDN 也是有点耗时滴~大家想一起学习的话可以私聊我加我,若觉得自己学啥好累,我本地其实有相关笔记的,就是可能潦草了点。
本来这没打算写博客的,但是源码这东西都是一环扣一环的,这又是比较重要的一个阶段,所以还是阐述一下吧,可能有些潦草,大伙需要自己边看,然后看这种博客会印象更深。
一、ClassPathBeanDefinitionScanner 扫描源码分析
doScan 扫描的具体逻辑
下面是其方法的代码解释,随后再具体分析:
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
// 过滤掉一些资源,得到预选的BeanDefinition
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
// 设置bean是多例还是单例
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// 获取到 BeanName,若存在@Component 注解则获取其value属性值,若没有则
// Introspector.decapitalize(shortClassName);
// 若0、1为大写则整个类名作为beanName,若不是则首字母小写
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// 设置一堆默认值
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
// 解析@Lazy、@Primary、@DependsOn、@Role、@Description
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 检查Spring容器中是否已经存在该beanName
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
// 注册
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
findCandidateComponents 方法解析
核心还是在 scanCandidateComponents 方法中:
源码解析:
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
// 获取basePackage下所有的文件资源
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// excludeFilters、includeFilters判断
// 一些过滤操作
if (isCandidateComponent(metadataReader)) { // @Component-->includeFilters判断
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
// 这里进行再次过滤,允许超类或者静态类
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
}
}
}
}
return candidates;
}
这边扫描定义了ExcludedeFilters:
@ComponentScan(basePackages = "com.powernode",
excludeFilters = {
@ComponentScan.Filter(
type = FilterType.ASSIGNABLE_TYPE,
value = UserService.class
)
})
则对应的 excludeFilters 为,若被它匹配到返回false,则不会添加到入选候选集candidates里。
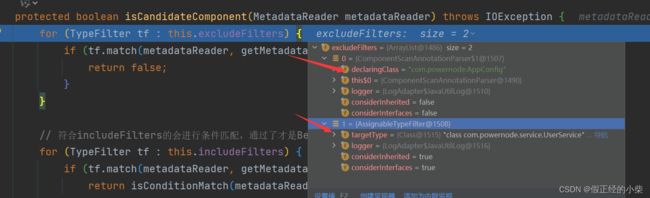
includeFilter 在初始化就会注册默认的过滤器,添加@Component至内:

则存在@Component注解且有Condition判断且判断为true的话就会放行通过:
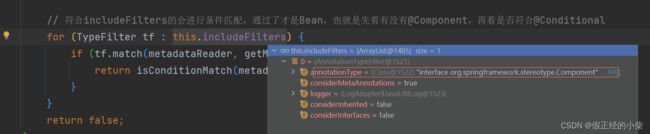
- 先通过给的路径扫描所有资源;
- 遍历资源通过
ASM技术获取到对应的元数据,然后封装成 ScannedGenericBeanDefinition; - 1、随后判断是否可以通过 includefilters 且若有 Conditional 注解的话判断是否匹配成功,且不被 excludefilters 过滤,则放行;
- 2、再次过滤,允许超类或者静态类
- 放入候选集 candidates 中,最后返回
generateBeanName 方法解析
具体源码如下:
public String generateBeanName(BeanDefinition definition, BeanDefinitionRegistry registry) {
if (definition instanceof AnnotatedBeanDefinition) {
// 获取注解所指定的beanName
String beanName = determineBeanNameFromAnnotation((AnnotatedBeanDefinition) definition);
if (StringUtils.hasText(beanName)) {
// Explicit bean name found.
return beanName;
}
}
// Fallback: generate a unique default bean name.
// 生成一个默认的beanName
return buildDefaultBeanName(definition, registry);
}
获取@Component中的beanName实现也很简单,就是遍历类上的所有注解,看有没有,有就取,没有就返回null回去:
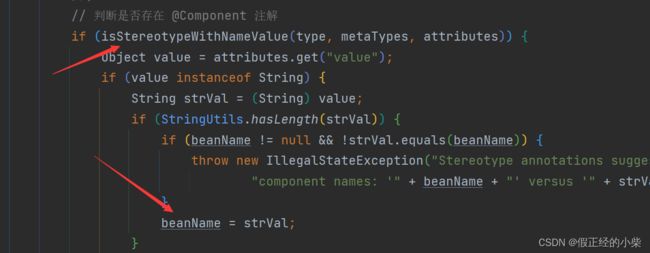
要为空就会生成一个默认的beanName,默认生成则通过内省API Introspector.decapitalize(shortClassName); 直接生成,里面的逻辑就是若首字母和次字母是大写就直接返回类名,若不是就首字母小写。
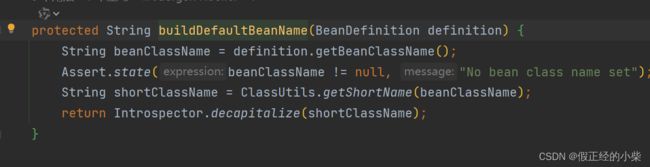
checkCandidate 方法解析
protected boolean checkCandidate(String beanName, BeanDefinition beanDefinition) throws IllegalStateException {
if (!this.registry.containsBeanDefinition(beanName)) {
return true;
}
BeanDefinition existingDef = this.registry.getBeanDefinition(beanName);
BeanDefinition originatingDef = existingDef.getOriginatingBeanDefinition();
if (originatingDef != null) {
existingDef = originatingDef;
}
// 是否兼容,如果兼容返回false表示不会重新注册到Spring容器中,如果不冲突则会抛异常。
// 就是看看是不是同一个类的 beanDefinition
// 就是同一类是不是被多次加载了,出现多次scan会有这种现象
if (isCompatible(beanDefinition, existingDef)) {
return false;
}
throw new ConflictingBeanDefinitionException("Annotation-specified bean name '" + beanName +
"' for bean class [" + beanDefinition.getBeanClassName() + "] conflicts with existing, " +
"non-compatible bean definition of same name and class [" + existingDef.getBeanClassName() + "]");
}
- 就判断容器内是否有相同的 beanDefinition,以beanName进行判断,如果没有就直接返回true,同意注册;
- 否则看是否是同一个类多次加载,是的话就返回false不注册;
- 再则就直接抛
ConflictBeanDefinitionException异常。
检查如果通过的话就把 beanName 放入到 beanDefinitionNames 集合中,把 BeanDefinition 放入到 beanDefinitionMap 中。
二、总结
- 首先是经过扫描获取到候选的 BeanDefinition 集(在选举候选集的时候,会经过 includefilter 判断,它内部初始化的时候会放入 @Component 注解进去进行检举,且过滤掉 excludefilter);
- 填充 scope;
- 获取 beanName;
- 初始化 BeanDefinition 中的一些属性;
- 解析@Lazy、@Primary、@DependsOn、@Role、@Description 到 BeanDefinition 中。
- 注册。