ClickHouse与Doris数据库比较
概述
都说“实践是检验真理的唯一标准”,光说不练假把式,那么本文就通过实际的测试来感受一下Doris和clickhouse在读写方面的性能差距,看看Doris盛名之下,是否真有屠龙之技;clickhouse长锋出鞘,是否敢缚苍龙?
废话不多说,上货。
硬件配置
在这里,我使用多台物理机搭建了clickhouse和Doris集群。
clickhouse集群
| 节点 | IP | 分片编号 | 副本编号 | 物理配置 |
|---|---|---|---|---|
| ck93 | 192.168.101.93 | 1 | 1 | 48core 256G 27T HDD |
| ck94 | 192.168.101.94 | 1 | 2 | 48core 256G 27T HDD |
| ck96 | 192.168.101.96 | 2 | 1 | 48core 256G 27T HDD |
| ck97 | 192.168.101.97 | 2 | 2 | 48core 256G 27T HDD |
Doris集群
| 角色 | 节点 | IP | 物理配置 |
|---|---|---|---|
| FE | ck94 | 192.168.101.94 | 48core 256G 27T HDD |
| BE | ck93 | 192.168.101.93 | 48core 256G 27T HDD |
| BE | ck94 | 192.168.101.94 | 48core 256G 27T HDD |
| BE | ck96 | 192.168.101.96 | 48core 256G 27T HDD |
clickhouse集群和Doris集群共用一套物理机。
数据准备
由于clickhouse与Doris共用物理机资源,为了避免互相干扰,在Doris测试时,clickhouse集群停止一切读写操作;同理,当clickhouse集群测试时,Doris集群也停止一切读写操作。
本次测试主要针对全文检索的场景。测试数据为clickhouse-server的日志文件,三个节点上的日志,共计2亿条数据,采集写入kafka后数据量为30GB。

我们将数据通过采集器组织成json格式后,采集到kafka,数据结构如下所示:
{
"@message": "2023.12.14 05:25:20.983533 [ 243360 ] {} aimeter.apm_span_index_trace_id (ReplicatedMergeTreePartCheckThread): Checking if anyone has a part 20231104_7476_7590_23 or covering part.",
"@@id": "cd8946be124a4079f4f372782ee6da1f",
"@filehashkey": "484d4e40bf93db91e25fbdfb47f084fe",
"@collectiontime": "2023-12-18T10:56:08.125+08:00",
"@hostname": "ck93",
"@path": "/data01/chenyc/logs/clickhouse-server/clickhouse-server.log.4",
"@rownumber": 6,
"@seq": 6,
"@ip": "192.168.101.93",
"@topic": "log_test"
} 主要测试数据写入和数据查询两个方面。
预设查询场景有如下几个:
- 根据ip和path维度统计每个ip下path的个数
- 统计每个ip下的Error日志的数量
- 统计日志中出现Debug 和 cdb56920-2d39-4e6d-be99-dd6ef24cc66a 的条数
- 统计出现Trace和gauge.apm_service_span出现的次数
- 查询Error中出现READ_ONLY的日志明细
- 查询日志中出现"上海"关键字的日志么明细
主要测试的性能指标包括:
- 写入性能
- 写入速度
- 写入过程的资源占用,CPU负载
- 写入后数据的压缩占比
- 查询性能
- 查询耗时
- 查询的资源占用
- 查询命中索引的情况
另增加测试一边写入一遍查询时对读写的影响。
Doris建表语句
建表语句如下:
CREATE database demo;
use demo;
CREATE TABLE demo.log_test (
`@@id` CHAR(34) NOT NULL COMMENT "每行的唯一hash标识id",
`@message` STRING NOT NULL COMMENT "日志内容",
`@filehashkey` CHAR(34) NOT NULL COMMENT "每个文件的hash值,用于标识文件唯一性",
`@collectiontime` DATETIME(3) COMMENT "采集时间",
`@hostname` VARCHAR(20) NOT NULL COMMENT "主机名",
`@path` VARCHAR(256) NOT NULL COMMENT "文件路径",
`@rownumber` BIGINT NOT NULL COMMENT "行号",
`@seq` BIGINT NOT NULL COMMENT "在同一个文件内连续的序列号",
`@ip` CHAR(16) NOT NULL COMMENT "节点IP",
`@topic` CHAR(16) NOT NULL COMMENT "所属kafka的topic",
INDEX idx_message_inv(`@message`) USING INVERTED PROPERTIES(
"parser" = "unicode",
"parser_mode" = "fine_grained",
"support_phrase" = "true"
) COMMENT "倒排索引",
INDEX idx_message_ngram(`@message`) USING NGRAM_BF PROPERTIES("gram_size"="5", "bf_size"="4096") COMMENT 'ngram_bf 索引'
)
DUPLICATE KEY(`@@id`)
PARTITION BY RANGE(`@collectiontime`) ()
DISTRIBUTED BY HASH(`@@id`) BUCKETS AUTO
ROLLUP (
r1 (`@message`),
r2 (`@ip`, `@path`)
)
PROPERTIES (
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-7",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "32",
"compression"="zstd"
);说明如下:
- 按
@collectiontime动态分区 - 默认三个副本
- 在
@message上创建一个unicode倒排索引,一个NGram BloomFilter索引 - 创建两个ROLLUP, 用来重建前缀索引
- 压缩方式采用ZSTD
clickhouse建表语句
--- 本地表
create table log_test on cluster abc (
`@@id` String NOT NULL CODEC(ZSTD(1)),
`@message` String NOT NULL CODEC(ZSTD(1)) ,
`@filehashkey` String NOT NULL CODEC(ZSTD(1)) ,
`@collectiontime` DateTime64(3) CODEC(DoubleDelta, LZ4),
`@hostname` LowCardinality(String) NOT NULL CODEC(ZSTD(1)) ,
`@path` String NOT NULL CODEC(ZSTD(1)) ,
`@rownumber` Int64 NOT NULL ,
`@seq` Int64 NOT NULL ,
`@ip` LowCardinality(String) NOT NULL CODEC(ZSTD(1)) ,
`@topic` LowCardinality(String) NOT NULL CODEC(ZSTD(1)) ,
INDEX message_idx `@message` TYPE ngrambf_v1(5, 65535, 1, 0) GRANULARITY 1,
PROJECTION p_cnt (
SELECT `@ip`, `@path`, count() GROUP BY `@ip`, `@path`
)
)ENGINE = ReplicatedMergeTree
PARTITION BY toYYYYMMDD(`@collectiontime`)
ORDER BY (`@collectiontime`, `@ip`, `@path`);
--- 分布式表
create table dist_log_test on cluster abc as log_test engine = Distributed('abc', 'default', 'log_test')说明如下:
- string字段使用ZSTD压缩,时间字段使用DoubleDelta压缩
- 在
@message字段是创建一个ngrambf_v1的二级索引 - 创建一个projection用于根据ip和path维度的预聚合
- 根据
@collectiontime字段按天做分区
写入性能
clickhouse
使用clickhouse_sinker向ck集群写入数据,为公平起见,clickhouse_sinker为单实例。
配置文件如下:
{
"clickhouse": {
"cluster": "abc",
"db": "default",
"hosts": [
["192.168.101.93", "192.168.101.94"],
["192.168.101.96", "192.168.101.97"]
],
"port": 19000,
"username": "default",
"password": "123456",
"maxOpenConns": 5,
"retryTimes": 0
},
"kafka": {
"brokers": "192.168.101.94:29092,192.168.101.96:29092,192.168.101.98:29092"
},
"tasks": [{
"name": "cktest",
"topic": "log_test",
"earliest": true,
"consumerGroup": "abc",
"parser": "fastjson",
"tableName": "log_test",
"autoSchema": true,
"dynamicSchema":{
"enable": false
},
"prometheusSchema": false,
"bufferSize": 1000000,
"flushInterval": 10
}],
"logLevel": "info"
}测试结果:
| 数据总量 | CPU(sinker) | 内存(sinker) | CPU(clickhouse) | 内存(clickhouse) | 写入速度(条/s) | 写入速度(M/s) | 总耗时 | 压缩前大小 | 压缩后大小 | 压缩比 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2亿 | 15 core | 22G | 5core | 4G | 280k/s | 125MB/s | 12min | 88.10GB | 10.39GB | 8:1 |
clickhouse中数据情况:

Doris
Doris使用Routine load向Doris集群写入数据,由于有3个backend,开启3个并发度。
Routine Load配置如下:
CREATE ROUTINE LOAD demo.doris_test ON log_test
COLUMNS(`@message`,`@@id`,`@filehashkey`,`@collectiontime`,`@hostname`,`@path`,`@rownumber`,`@seq`,`@ip`,`@topic`)
PROPERTIES
(
"desired_concurrent_number"="3",
"max_error_number" = "500",
"max_batch_interval" = "20",
"max_batch_rows" = "300000",
"max_batch_size" = "209715200",
"strict_mode" = "false",
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.101.94:29092,192.168.101.96:29092,192.168.101.98:29092",
"kafka_topic" = "log_test",
"kafka_partitions" = "0,1,2,3,4,5",
"kafka_offsets" = "0,0,0,0,0,0"
);这里 max_error_number 设置了500, 意思是容忍task失败500次。之所以设置这个容忍度,是因为Doris采用RapidJSON库解析JSON串,这个库解析部分乱码数据时会报错:
Reason: Parse json data for JsonDoc failed. code: 10, error info: The input is not valid UTF-8. src line [{"@message":"2023.12.13 18:41:17.762463 [ 143536 ] {bcf2d3d6-a68a-46a3-a008-55399f6a596f} void DB::ParallelParsingInputFormat::onBackgroundException(size_t): Code: 27. DB::ParsingException: Cannot parse input: expected '\\t' before: 'd8caa60-f8f4-45a0-9e45-ee1a9344f774\\t200.188.12.25\\t\\\\N\\tssh\\t\\\\N\\t22\\tzx2\\t1\\t1\\t2\\t180\\t0\\tIT运维管理平台(e海智维)\\t010336\\t季杨\\t6339\\t运维支持部\\t1\\t广东�': \nRow 1:\nColumn 0, name: id, type: Int64, parsed text: \"4\"\nColumn 1, name: deviceId, type: Nullable(Int64), parsed text: \"4\"\nERROR: garbage after Nullable(Int64): \"d8caa60-f8\"\n\n: (at row 1)\n. (CANNOT_PARSE_INPUT_ASSERTION_FAILED), Stack trace (when copying this message, always include the lines below):\n\n0. DB::Exception::Exception(DB::Exception::MessageMasked&&, int, bool) @ 0xe18d895 in /usr/bin/clickhouse\n1. ? @ 0xe1ec044 in /usr/bin/clickhouse\n2. DB::throwAtAssertionFailed(char const*, DB::ReadBuffer&) @ 0xe1ebf41 in /usr/bin/clickhouse\n3. DB::TabSeparatedFormatReader::skipFieldDelimiter() @ 0x14adec49 in /usr/bin/clickhouse\n4. DB::RowInputFormatWithNamesAndTypes::readRow(std::vector::mutable_ptr, std::allocator::mutable_ptr>>&, DB::RowReadExtension&) @ 0x149d531f in /usr/bin/clickhouse\n5. DB::IRowInputFormat::generate() @ 0x149b08ae in /usr/bin/clickhouse\n6. DB::ISource::tryGenerate() @ 0x14933695 in /usr/bin/clickhouse\n7. DB::ISource::work() @ 0x14933206 in /usr/bin/clickhouse\n8. DB::ParallelParsingInputFormat::parserThreadFunction(std::shared_ptr, unsigned long) @ 0x14a5c341 in /usr/bin/clickhouse\n9. ThreadPoolImpl>::worker(std::__list_iterator, void*>) @ 0xe260ea5 in /usr/bin/clickhouse\n10. void std::__function::__policy_invoker::__call_impl::ThreadFromGlobalPoolImpl>::scheduleImpl(std::function, long, std::optional, bool)::'lambda0'()>(void&&)::'lambda'(), void ()>>(std::__function::__policy_storage const*) @ 0xe263a15 in /usr/bin/clickhouse\n11. ThreadPoolImpl::worker(std::__list_iterator) @ 0xe25cc73 in /usr/bin/clickhouse\n12. ? @ 0xe2628e1 in /usr/bin/clickhouse\n13. start_thread @ 0x7ea5 in /usr/lib64/libpthread-2.17.so\n14. clone @ 0xfeb0d in /usr/lib64/libc-2.17.so\n (version 23.3.1.2823 (official build))","@@id":"b63049ee2121095314365cc38aa23472","@filehashkey":"778261a8412adda6f7e3f7297ea2d5d1","@collectiontime":"2023-12-18T11:07:21.680+08:00","@hostname":"master94","@path":"/data01/chenyc/logs/clickhouse-server/clickhouse-server.err.log.0","@rownumber":2883976,"@seq":2842107,"@ip":"192.168.101.94","@topic":"log_test"}]; 为了屏蔽掉这个报错导致任务异常PAUSED,所以将出错容忍度设置为500。
测试结果如下:
| 数据总量 | CPU(FE) | 内存(FE) | CPU(BE) | 内存(BE) | 写入速度(条/s) | 写入速度(M/s) | 总耗时 | 压缩前大小 | 压缩后大小 | 压缩比 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2亿 | 1 core | 2G | 19 core | 15G | 126K/s | 81MB/s | 27min | 120.34GB | 22GB | 5:1 |
任务情况:
mysql> show routine load\G;
*************************** 1. row ***************************
Id: 22719
Name: doris_test
CreateTime: 2023-12-18 16:08:49
PauseTime: NULL
EndTime: NULL
DbName: default_cluster:demo
TableName: log_test
IsMultiTable: false
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 3
JobProperties: {"max_batch_rows":"300000","timezone":"Asia/Shanghai","send_batch_parallelism":"1","load_to_single_tablet":"false","current_concurrent_number":"3","delete":"*","partial_columns":"false","merge_type":"APPEND","exec_mem_limit":"2147483648","strict_mode":"false","jsonpaths":"","max_batch_interval":"20","max_batch_size":"209715200","fuzzy_parse":"false","partitions":"*","columnToColumnExpr":"@message,@@id,@filehashkey,@collectiontime,@hostname,@path,@rownumber,@seq,@ip,@topic","whereExpr":"*","desired_concurrent_number":"3","precedingFilter":"*","format":"json","max_error_number":"500","max_filter_ratio":"1.0","json_root":"","strip_outer_array":"false","num_as_string":"false"}
DataSourceProperties: {"topic":"log_test","currentKafkaPartitions":"0,1,2,3,4,5","brokerList":"192.168.101.94:29092,192.168.101.96:29092,192.168.101.98:29092"}
CustomProperties: {"group.id":"doris_test_4fba1257-9291-44cc-b4ef-61dd64f58c5e"}
Statistic: {"receivedBytes":129215158726,"runningTxns":[],"errorRows":57,"committedTaskNum":720,"loadedRows":201594590,"loadRowsRate":41912,"abortedTaskNum":0,"errorRowsAfterResumed":0,"totalRows":201594647,"unselectedRows":0,"receivedBytesRate":26864584,"taskExecuteTimeMs":4809870}
Progress: {"0":"33599107","1":"33599106","2":"33599107","3":"33599107","4":"33599107","5":"33599107"}
Lag: {"0":0,"1":0,"2":0,"3":0,"4":0,"5":0}
ReasonOfStateChanged:
ErrorLogUrls: http://192.168.101.93:58040/api/_load_error_log?file=__shard_15/error_log_insert_stmt_6c68b52cc0f849f7-ac9a0ce97dabf7e9_6c68b52cc0f849f7_ac9a0ce97dabf7e9, http://192.168.101.96:58040/api/_load_error_log?file=__shard_16/error_log_insert_stmt_7e6449b5c1b6469f-901d55766835b101_7e6449b5c1b6469f_901d55766835b101, http://192.168.101.94:58040/api/_load_error_log?file=__shard_18/error_log_insert_stmt_44ca6b30a5394689-b34d2e33de930a0c_44ca6b30a5394689_b34d2e33de930a0c
OtherMsg:
User: root
Comment: 这个地方的指标数据是有BUG的:
Statistic: {"receivedBytes":129215158726,"runningTxns":[],"errorRows":57,"committedTaskNum":720,"loadedRows":201594590,"loadRowsRate":41912,"abortedTaskNum":0,"errorRowsAfterResumed":0,"totalRows":201594647,"unselectedRows":0,"receivedBytesRate":26864584,"taskExecuteTimeMs":4809870}我们可以看一下它的计算逻辑:
public Map summary() {
Map summary = Maps.newHashMap();
summary.put("totalRows", Long.valueOf(totalRows));
summary.put("loadedRows", Long.valueOf(totalRows - this.errorRows - this.unselectedRows));
summary.put("errorRows", Long.valueOf(this.errorRows));
summary.put("errorRowsAfterResumed", Long.valueOf(this.errorRowsAfterResumed));
summary.put("unselectedRows", Long.valueOf(this.unselectedRows));
summary.put("receivedBytes", Long.valueOf(this.receivedBytes));
summary.put("taskExecuteTimeMs", Long.valueOf(this.totalTaskExcutionTimeMs));
summary.put("receivedBytesRate", Long.valueOf(this.receivedBytes * 1000 / this.totalTaskExcutionTimeMs));
summary.put("loadRowsRate", Long.valueOf((this.totalRows - this.errorRows - this.unselectedRows) * 1000
/ this.totalTaskExcutionTimeMs));
summary.put("committedTaskNum", Long.valueOf(this.committedTaskNum));
summary.put("abortedTaskNum", Long.valueOf(this.abortedTaskNum));
summary.put("runningTxns", runningTxnIds);
return summary;
} receivedBytesRate是拿总条数/总耗时,loadRowsRate是拿总条数-出错条数-未选中条数 再除以总时间,看起来是没有问题的。但问题出在这个总时间taskExecuteTimeMs上:
private void updateNumOfData(long numOfTotalRows, long numOfErrorRows, long unselectedRows, long receivedBytes,
long taskExecutionTime, boolean isReplay) throws UserException {
this.jobStatistic.totalRows += numOfTotalRows;
this.jobStatistic.errorRows += numOfErrorRows;
this.jobStatistic.unselectedRows += unselectedRows;
this.jobStatistic.receivedBytes += receivedBytes;
this.jobStatistic.totalTaskExcutionTimeMs += taskExecutionTime;
...
}此处计算总行数,去统计各个并发的总数是没问题的,但是总耗时也这样计算的话,实际上是多算了,也就是说,有几个并发度,这个时间就多算了多少倍。因此,这个导入任务的真实时间应该是 4809870/ 3 = 1603290,也就是27分钟。
插入后表中数据:
mysql> select count(*) from log_test;
+-----------+
| count(*) |
+-----------+
| 201594590 |
+-----------+
1 row in set (0.05 sec)Doris接收到的数据总量为120G,远大于clickhouse压缩前的数据量88G,猜测原因可能是写放大导致。因为Routine Load实际上是FE分配任务后在BE上执行stream load,而stream load则是先将数据拉取到一个BE节点,然后广播发送给其他节点。
写入性能小结
从2亿条数据的写入性能来看,clickhouse写入可以达到28w条每秒,Doris大约12w条/s, clickhouse的写入性能是Doris的2倍以上。
但是从资源消耗来看,Doris的写入由于是由Routine Load完成,占用的是BE节点的资源,而clickhouse使用第三方的clickhouse_sinker完成,完全可以和节点部署在不同机器上,从而避免对clickhouse集群资源的侵占。
Doris在写入性能落后的情况下,CPU的消耗与clickhouse_sinker相当,内存稍微占用少一点,但是和clickhouse节点来比,就完全不是一个数量级了。clickhouse在数据写入时,CPU和内存的波动都比较小,处于正常水平。不会吃太多的资源,从而影响到查询。更为重要的是,Doris写入的资源占用,是每个节点都要占这么多,N个节点,这个资源消耗就是N倍,这和clickhouse_sinker之间的差距就进一步拉大了。
clickhouse_sinker是擎创科技开源的一个将kafka的数据写入clickhouse的开源项目。拥有着低资源消耗,高性能写入,高容错、稳定的运行能力。它通过写本地表的方式,可以达到数据均衡写入到各节点,自动按照shardingkey做hash路由,多个sinker进程实例之间自动根据kafka的消费lag来合理分配写入任务等,非常适合作为clickhouse数据写入的方案。
从压缩性能上来看,由于clickhouse和Doris对压缩前的数据统计口径不一致,所以光看压缩比意义不大。但kafka的数据是固定的,kafka里的数据是30G(kafka也有自己的压缩算法,使用的是zstd),写入到clickhouse后数据为10.17GB,这个大小没有算入副本,如果算上副本,应该乘以2,也就是20.34GB。
Doris的数据大小通过SHOW TABLE STATUS FROM demo LIKE '%log_test%';查询得到,Data_length为67.71GB,除以三个副本,得到22.57GB。
不算副本,只看单一数据的大小,clickhouse的压缩率达到了Doris的2.2倍,这个压缩差距还是非常大的。
查询性能
我们分上面六个预设的场景进行查询测试。
| 场景 | 说明 |
|---|---|
| 场景1 | 根据ip和path维度统计每个ip下path的个数 |
| 场景2 | 统计每个ip下的Error日志的数量 |
| 场景3 | 统计日志中出现Debug 和 query_id 为 cdb56920-2d39-4e6d-be99-dd6ef24cc66a 的条数 |
| 场景4 | 统计出现Trace和gauge.apm_service_span出现的次数 |
| 场景5 | 查询Error中出现READ_ONLY的日志明细 |
| 场景6 | 查询日志中出现“上海”关键字的明细 |
查询SQL如下:
| 场景 | 数据库 | SQL语句 |
|---|---|---|
| 场景1 | clickhouse | SELECT @ip, @path, count() FROM dist_log_test GROUP BY @ip,@path |
| 场景1 | Doris | SELECT @ip, @path, count() FROM log_test GROUP BY @ip,@path |
| 场景2 | clickhouse | SELECT @ip, count() FROM dist_log_test WHERE @message LIKE '%Error%' GROUP BY @ip |
| 场景2 | Doris | SELECT @ip, count() FROM log_test WHERE @message MATCH_ANY 'Error' GROUP BY @ip |
| 场景3 | clickhouse | SELECT count() FROM dist_log_test WHERE @message LIKE '%Debug%' AND @message LIKE '%cdb56920-2d39-4e6d-be99-dd6ef24cc66a%' |
| 场景3 | Doris | SELECT count() FROM log_test WHERE @message MATCH_ALL 'Debug cdb56920-2d39-4e6d-be99-dd6ef24cc66a' |
| 场景4 | clickhouse | SELECT count() FROM dist_log_test WHERE @message LIKE '%Trace%' AND @message LIKE '%gauge.apm_service_span%' |
| 场景4 | Doris | SELECT count() FROM log_test WHERE @message MATCH_ALL 'Trace gauge.apm_service_span' |
| 场景5 | clickhouse | SELECT * FROM dist_log_test WHERE @message LIKE '%Error%' AND @message LIKE '%READ_ONLY%' |
| 场景5 | Doris | SELECT * FROM log_test WHERE @message MATCH_ALL 'Error READ_ONLY' |
| 场景6 | clickhouse | SELECT * FROM dist_log_test WHERE @message LIKE '%上海%' |
| 场景6 | Doris | SELECT * FROM log_test WHERE @message MATCH_ANY '上海' |
查询结果:
备注:查询结果取连续查询10次的中位数。
| 数据库 | 场景1 | 场景2 | 场景3 | 场景4 | 场景5 | 场景6 |
|---|---|---|---|---|---|---|
| clickhouse | 0.078 sec | 7.948 sec | 0.917 sec | 3.362 sec | 4.584 sec | 3.784 sec |
| Doris | 0.84 sec | 5.91 sec | 0.19 sec | 0.84 sec | 5.07 sec | 0.75 sec |
初步分析:
从上述结果来看,clickhouse胜2负4。其中场景1是碾压性优势,查询性能是Doris的10倍多,这是因为Doris本身不善于count类的查询,而clickhouse依靠projection的预聚合查询,达到了极致性能。
场景5之所以clickhouse能领先,有必要说明一下,按照原计划Doris使用MATCH ALL语法去查询,但是没有查询到结果(不明白为什么),改用LIKE查询后性能比较差,达到了5秒左右,甚至比clickhouse更慢(这也是我没有想到的)。
Doris在PK中胜4负2,比分大幅领先。除了场景2查询耗时相差不大之外,其余场景3、4、6都是降维打击,性能遥遥领先,达到了clickhouse的5倍左右。这自然是得益于Doris的全文检索功能立了大功。
场景2之所以相差不大,还是因为SQL中涉及到了count的计算,前面说过,Doris不擅长count类的查询,因此性能比较拉胯,也就情有可原了。但即便如此,依然依然能达到clickhouse的1.3倍。
clickhouse 日志存储优化方案-构建隐式列
构建隐式列(或map列)是目前业界各大企业使用clickhouse存储日志的通用落地方案。下面摘取了一些成熟的日志存储的实践方案,无不例外都用到了构建隐式列或Map列的思想:
- 使用 ClickHouse 构建通用日志系统
- Uber 如何使用 ClickHouse 建立快速可靠且与模式无关的日志分析平台?
- 还在用 ES 查日志吗,快看看石墨文档 Clickhouse 日志架构玩法
- Building an Observability Solution with ClickHouse - Part 1 - Logs
- B站基于Clickhouse的下一代日志体系建设实践
所谓隐式列( Implicit columns), 我们可以将message中常用的(有规律的)一些字段,通过正则表达式提取出来,作为一个隐式列,构建一个大宽表,然后查询的时候匹配该隐式列,从而达到避免走或少走全文检索的效果。你clickhouse不是不擅长模糊查询么,那么我就尽量不走模糊查询,不就行了吗?
比如本案例中,我们可以将日志中的query_id,thread_id,loglevel, timestamp等内容提取出来。
下例为通过我们自研采集器提取字段的例子:
if $raw_event =~ /(^\d+\.\d+\.\d+\s+\d+:\d+:\d+\.\d+)\s+\[\s+(\d+)\s+\]\s+{(.*)}\s+<(\w+)>.*/ {
$@timestamp=replace($1, ".", "-", 2);
$@threadid=$2;
$@queryid=$3;
$@loglevel=$4;
}采集到的数据样例如下:
{
"@message": "2023.12.07 03:41:18.775976 [ 154026 ] {} aimeter.metric_agg (ReplicatedMergeTreePartCheckThread): No replica has part covering 202312_11890_20601_1725 and a merge is impossible: we didn't find a smaller part with the same min block.",
"@@id": "f7efeef0501a4f13f8561d2dfa18461d",
"@filehashkey": "12d1faf9499acb0664d5dfe4af9d761c",
"@collectiontime": "2023-12-18T17:56:26.586+08:00",
"@hostname": "master94",
"@path": "/data01/chenyc/logs/clickhouse-server/clickhouse-server.err.log.1",
"@rownumber": 3,
"@seq": 3,
"@timestamp": "2023-12-07 03:41:18.775976",
"@threadid": "154026",
"@queryid": "",
"@loglevel": "Error",
"@ip": "192.168.101.94",
"@topic": "log_test2"
} 建表语句如下:
CREATE TABLE default.log_test2 on cluster abc (
`@@id` String CODEC(ZSTD(1)),
`@message` String CODEC(ZSTD(1)),
`@filehashkey` String CODEC(ZSTD(1)),
`@collectiontime` DateTime64(3),
`@hostname` String,
`@path` String CODEC(ZSTD(1)),
`@rownumber` Int64,
`@seq` Int64,
`@timestamp` DateTime64(3) CODEC(DoubleDelta, LZ4),
`@threadid` Int32,
`@queryid` String CODEC(ZSTD(1)),
`@loglevel` LowCardinality(String),
`@ip` String CODEC(ZSTD(1)),
`@topic` LowCardinality(String),
INDEX level_idx `@loglevel` TYPE tokenbf_v1(4096, 1, 0) GRANULARITY 1,
INDEX ip_idx `@ip` TYPE tokenbf_v1(4096, 1, 0) GRANULARITY 1,
INDEX query_idx `@queryid` TYPE ngrambf_v1(10, 30720, 1, 0) GRANULARITY 1,
INDEX message_idx `@message` TYPE ngrambf_v1(5, 65535, 1, 0) GRANULARITY 1,
PROJECTION p_cnt (
SELECT `@ip`, `@path`, count() GROUP BY `@ip`, `@path`
)
) ENGINE = ReplicatedMergeTree
PARTITION BY toYYYYMMDD(`@timestamp`)
ORDER BY
(`@timestamp`, `@ip`, `@path`, `@loglevel`)
--- 分布式表
create table dist_log_test2 on cluster abc as log_test2 engine = Distributed('abc', 'default', 'log_test2')由于多了4个字段,kafka中的数据膨胀了4G。

通过clickhouse_sinker将数据导入到clickhouse集群。
写入clickhouse后如下所示:

针对上面6种场景,改写SQL如下:
| 场景 | 查询SQL语句 |
|---|---|
| 场景1 | SELECT @ip, @path, count() FROM dist_log_test2 GROUP BY @ip,@path |
| 场景2 | SELECT @ip, count() FROM dist_log_test2 WHERE hasToken(@loglevel, 'Error') GROUP BY @ip |
| 场景3 | SELECT count() FROM dist_log_test2 WHERE hasToken(@loglevel, 'Debug') AND @queryid = 'cdb56920-2d39-4e6d-be99-dd6ef24cc66a' |
| 场景4 | SELECT count() FROM dist_log_test2 WHERE hasToken(@loglevel, 'Trace') AND @message LIKE '%gauge.apm_service_span%' |
| 场景5 | SELECT * FROM dist_log_test2 WHERE hasToken(@loglevel, 'Error') AND @message LIKE '%READ_ONLY%' |
| 场景6 | SELECT * FROM dist_log_test2 WHERE @message LIKE '%上海%' |
为了方便对比,我们将上两次的查询结果也贴到一块。
| 数据库 | 场景1 | 场景2 | 场景3 | 场景4 | 场景5 | 场景6 |
|---|---|---|---|---|---|---|
| clickhouse | 0.078 sec | 7.948 sec | 0.917 sec | 3.362 sec | 4.584 sec | 3.784 sec |
| Doris | 0.84 sec | 5.91 sec | 0.19 sec | 0.84 sec | 5.07 sec | 0.75 sec |
| clickhouse with Implicit columns | 0.064 sec | 0.390 sec | 0.317 sec | 1.117 sec | 4.288 sec | 3.437 sec |
先刨除掉场景1,场景6不看,因为查询SQL与不加隐式列是一样的,所以性能也差不多。
关键看场景2,场景3,场景4。场景2比未加隐式列之前性能提升了20倍,比Doris提升了15倍,提升非常大。而场景3和场景4也在不加隐式列的基础上提升了3倍左右的性能,虽然还比不上Doris,但差距已经追小了许多(Doris仅领先1.5倍)。
场景5由于仍然有根据@message字段做模糊搜索,所以性能提升不大。
总而言之,在绝大多数场景,通过隐式列的方式改写查询语句,可以将原有的查询性能提升3倍左右。
通过构建隐式列的方式存储日志,可有效解决查询性能的问题。但在交互上就显得不那么友好。因为对于使用者来说,是不知道有这些列的存在的,或者说如果使用者没有很强的业务感知能力,都是随性搜索短语的话,同样会导致查询的内容只能通过模糊匹配,那么就起不到任何加速作用。
因此,要想用好隐式列,首先需要在交互上引导用户去使用隐式列进行条件搜索,而不是随意选择关键字;
其次是要做好日志规范,否则,不仅提取有效关键字比较困难,而且不同的业务日志有不同的提取方法,有不同的关键字,导致提取出来的维度关键字五花八门,这对搜索来说也带来了一定的困难。
大查询对写入的影响
我们知道,在实际生产环境,除非有一套相对成熟的存算分离方案,否则写入对查询的互相影响是不可避免的。由于数据量有限,为了尽可能模拟大查询对写入的影响,我们采用场景2的SQL语句,通过5个SQL并发查询,观察写入数据的速度变化。
为了尽可能模拟真实并发情况,在这里使用golang分别实现了5并发查询数据库的功能。
clickhouse:
package main
import (
"fmt"
"sync"
"github.com/ClickHouse/clickhouse-go/v2"
)
func main() {
conn := clickhouse.OpenDB(&clickhouse.Options{
Addr: []string{"192.168.101.93:19000","192.168.101.94:19000","192.168.101.96:19000","192.168.101.97:19000"},
Auth: clickhouse.Auth{
Database: "default",
Username: "default",
Password: "123456",
},
})
err := conn.Ping()
if err != nil {
panic(err)
}
query := "SELECT `@ip`, count() FROM dist_log_test WHERE `@message` LIKE '%Error%' GROUP BY `@ip`"
for {
var wg sync.WaitGroup
var lastErr error
for i := 0; i < 5; i++ {
wg.Add(1)
go func() {
defer wg.Done()
rows, err := conn.Query(query)
if err != nil {
lastErr = err
return
}
defer rows.Close()
for rows.Next() {
var (
ip string
cnt uint64
)
if err := rows.Scan(&ip, &cnt); err != nil {
lastErr = err
return
}
fmt.Printf("ip: %s, count: %d\n", ip, cnt)
}
}()
}
wg.Wait()
if lastErr != nil {
panic(lastErr)
}
}
}
查询Doris:
package main
import (
"database/sql"
"fmt"
"sync"
_ "github.com/go-sql-driver/mysql"
)
func main() {
conn, err := sql.Open("mysql", "root:@(192.168.101.94:59030)/demo")
if err != nil {
panic(err)
}
if err = conn.Ping(); err != nil {
panic(err)
}
query := "SELECT `@ip`, count() FROM log_test WHERE `@message` MATCH_ANY 'Error' GROUP BY `@ip`"
for {
var wg sync.WaitGroup
var lastErr error
for i := 0; i < 5; i++ {
wg.Add(1)
go func() {
defer wg.Done()
rows, err := conn.Query(query)
if err != nil {
lastErr = err
return
}
defer rows.Close()
for rows.Next() {
var (
ip string
cnt uint64
)
if err := rows.Scan(&ip, &cnt); err != nil {
lastErr = err
return
}
fmt.Printf("ip: %s, count: %d\n", ip, cnt)
}
}()
}
wg.Wait()
if lastErr != nil {
panic(lastErr)
}
}
}
clickhouse

clickhouse5个并发同时查询,CPU飙到了接近40 core,几乎占满了物理机的80%的资源。
此时我们启动clickhouse_sinker任务(sinker进程部署在clickhouse集群以外的节点),观察写入性能如下:
| 写入数据条数 | 写入数据总量 | 写入性能(条/s) | 写入性能(M/s) | 总耗时 |
|---|---|---|---|---|
| 2亿条数据 | 88GB | 196k/s | 88M/s | 17min |
上面这个测试案例比较特殊,因为所有的查询请求都打到了同一个clickhouse节点,导致这个节点的CPU占用特别高,其他节点的CPU比较正常,整体写入性能有所下降,约为原来的70%。但总体性能还是不错的,单sinker进程可以达到20w行每秒。
如果我们在clickhouse的查询端加一层proxy,使得查询请求比较均衡地分不到各个clickhouse节点,相信查询性能还能进一步提高。
Doris
5个并发查询Doris,可以看到Doris的FE几乎无资源损耗,但是BE的CPU吃满。而且与clickhouse不同的是,clickhouse是仅请求打到这个节点上,这个节点的CPU才会占得比较高,但是Doris的各个节点的CPU都占得比较高。

我们同样启动一个Routine Load向Doris写入数据,性能如下:
| 写入数据条数 | 写入数据总量 | 写入性能(条/s) | 写入性能(M/s) | 总耗时 |
|---|---|---|---|---|
| 2亿条数据 | 120GB | 71k/s | 43MB/s | 47min |
当我们在并发执行很多耗时的大查询时,由于CPU占用比较满,导致写入性能下降了50%左右,这使得原本就不富裕的生活更加雪上加霜。
但是我们注意到一个有意思的现象,原本场景2的查询5秒能返回结果,但是在高速写入时,查询速度降到了15秒(事实上所有的查询都慢了2-3倍左右,clickhouse更夸张,查询会慢5倍以上)。所以Doris在同时有读写请求的时候,是优先保证写请求的资源的。
大查询写入优化方案-用户资源限制
clickhouse和Doris都可以通过设置用户权限来限制某个查询用户所能使用的资源。从上面的测试结果来看,我们发现即使clickhouse写入时大查询占据了80%资源,clickhouse的写入速度(190k/s)还是高于Doris无干扰写入的速度(126k/s), 因此,我们主要来看clickhouse在专门设置了一个查询用户后的插入性能情况。
我们新增一个query的用户:

通过profile限制其查询最大线程数为8:
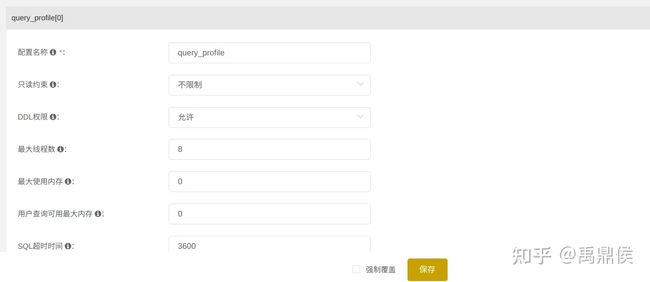
由于可用线程数减少,为了避免查询超时,将SQL超时时间修改到1个小时。
同时通过quota设置当1分钟内连续5次报错,就禁止该用户查询:
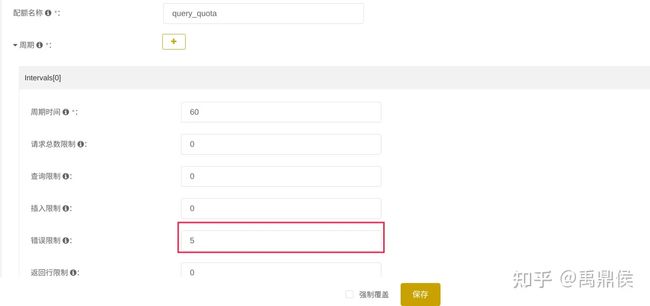
我们通过这个query用户,起5个并发,轮询查询副本节点ck94, ck97(clickhouse写ck93, ck96)。clickhouse_sinker在集群以外的节点上启动。
测试结果如下:
| 写入数据条数 | 写入数据总量 | 写入性能(条/s) | 写入性能(M/s) | 总耗时 |
|---|---|---|---|---|
| 2亿条数据 | 88GB | 250~270k/s | 114MB/s | 13min |
对比无干扰时写入,写入性能仅下降5-10%左右,这主要是因为写入本身消耗的节点资源就比较少,当查询的资源被限制,clickhouse的节点就有足够多的资源去保障写入,并且我们通过配置简单的读写分离的方式,让查询请求尽量分配到不同的副本节点,可以进一步减小查询对写入的影响。
不过需要注意的是,用户的最大线程数限制的是单个查询所使用的最大线程资源,如果多个查询语句同时请求到同一个节点,仍然能将该节点的CPU负载占满。(测试过程中,尝试5个并发全部请求到一个节点,该节点CPU能达到2500%)。
总结
本文重点比较了clickhouse和Doris在日志存储场景下的写入能力和查询能力。
写入性能上,clickhouse完胜。在写入性能领先Doris 2倍的情况下,可以做到使用更少的系统资源,且压缩率也达到了Doris的2倍以上。
至于查询性能,由于Doris支持倒排索引,在模糊查询场景,Doris对比clickhouse有5倍左右的提升,虽然clickhouse可以通过构建隐式列的方式提升查询效率,但Doris仍然能够做到1.5倍左右的性能领先。
而在需要聚合计算count的查询场景,Doris明显不如clickhouse高效。
在读写同时进行的场景,在大查询比较多时,clickhouse和Doris的写入性能都有所下降,clickhouse写入性能下降到70%,Doris则直接腰斩。而且都对查询影响比较大。
通过配置专门的查询用户限制查询查询资源,可有效缓解大查询对写入带来的性能影响。
本专栏知识点是通过<零声教育>的系统学习,进行梳理总结写下文章,对C/C++课程感兴趣的读者,可以点击链接,查看详细的服务:C/C++Linux服务器开发/高级架构师