SAS logistic回归模型如何计算校正比例?
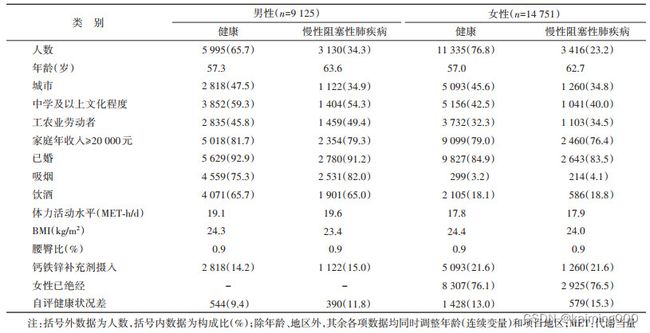
在流行病学研究中,在研究两种因素的关联性研究时,通常在论文的表1时,往往会根据暴露因素进行分组,然后分析不同暴露组的基本特征,这时候连续变量会采用均数(标准差)表示,分类变量采用频数(构成比/率)表示,但这里往往给出的原始值,但有时候部分论文会给出校正均值和校正率,部分同学可能会很困惑,比如下面这篇文章的表1:
这篇文章是研究慢阻肺和骨密度的相关性,因此表1给出了健康者和慢阻肺患者其他基本特征。
上表的备注说:除年龄、地区外,其余各项数据均调整了年龄和地区,也就是说此表年龄是真实值,而其他为校正值,比如城市应该给出的是校正比例。
接着查看论文的统计学方法:
因此,可以看出校正比例/构成比是采用logistics模型计算的,今天先分享一下用SAS去计算校正比例。

下面直接上代码,并以图文的形式向大家讲解:
/*变量名可以设定为中文*/
option validvarname=any;
/*先导入数据*/
PROC IMPORT OUT= mydata
DATAFILE= "C:\Users\12974\Desktop\百度经验\01简书\SAS线性回归模型如何计算校正均值\cc1.csv"
DBMS=csv REPLACE;
GETNAMES=YES;
quit;
/*图片3*/
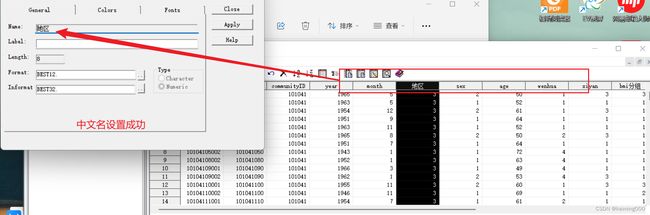
/*这里可以看到数据导入成功,并且中文变量名也设置成功了*/
/*本例的目的计算不同性别的心血管的患病率,并且同时校正地区和年龄;*/
/*在数据库中自变量:sex,因变量:心血管,混杂因素:地区、age*/
/*有两种方法拟合*/
/*采用proc genmod拟合logistic模型*/
proc genmod data=mydata desc;
class sex(ref='1') 心血管(ref='1') 地区(ref='3');/*分类变量放到class语句后*/
model 心血管=sex 地区 age/dist=binomial link=logit;
/*dist=binomial link=logit 表示拟合logistic模型*/
lsmeans sex/ilink cl pdiff;
/*ilink:给出校正率
cl:给出置信区间
pdiff:给出两两两比较的结果,但是这里没给出校正率的差值*/
quit;
proc logistic data=mydata;
class sex(ref='1') 心血管(ref='1') 地区(ref='3')/param=glm;/*分类变量放到class语句后*/
/* param=glm必须写上*/
model 心血管=sex 地区 age/link=logit;
/*dist=binomial link=logit 表示拟合logistic模型*/
lsmeans sex/ilink cl pdiff;
/*ilink:给出校正率
cl:给出置信区间
pdiff:给出两两两比较的结果,但是这里没给出校正率的差值*/
quit;
/*图4和图5*/

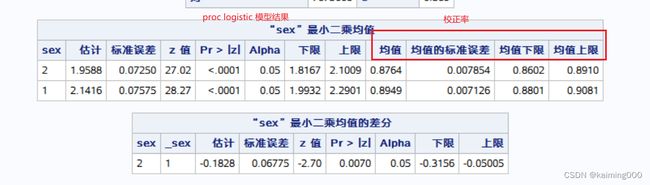
/**这里可以看到两种模型拟合的结果一致**/
/*那么,为什么最小二乘均值表里面的均值就是比例呢?*/
/*为了验证这个,我打算直接算出不同性病的心血管的患病率
然后利用不调整任何变量的logistic模型去看上面的均值与算出的患病率是否一致?*/
proc freq data=mydata;
table 心血管*sex;
quit;
proc logistic data=mydata;
class sex(ref='1') 心血管(ref='0') /param=glm;/*这里需要设定心血管参照为0*/
model 心血管=sex/link=logit;/*模型中只加入性别*/
lsmeans sex/ilink cl pdiff;
quit;
/*图6和图7*/
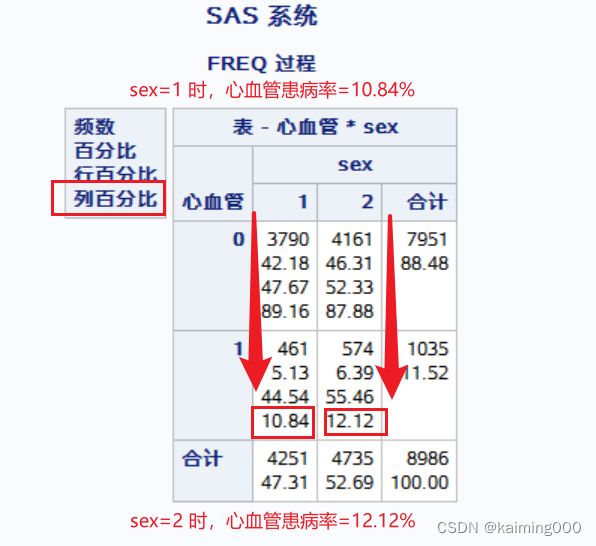

可以看到两个结果一致就验证了我的假设