Java集合-Set详细分析
前言
Java的整个集合框架中,主要分为List,Set,Queue,Stack,Map等五种数据结构。其中前四种数据结构都是单一元素的集合,而最后的Map则是以KV对的形式使用。
从继承关系上讲,List,Set,Queue都是Collection的子接口,Collection又继承了Iterable接口,说明这几种集合都是可以遍历的。本篇,我们来从源码角度分析了解Set集合基本操作,探索Set底层的奥秘。
一.了解Set
在Java的Set体系中,根据实现方式不同主要分为两大类。HashSet和TreeSet。
1.TreeSet 是二叉树实现的,TreeSet中的数据是自动排好序的,不允许放入null值; 底层基于TreeMap
2.HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束;底层基于HashMap
Set集合框架结构: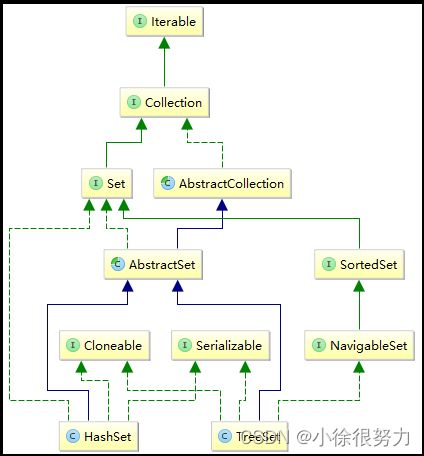
二. Set常用方法
与List接口一样,Set接口也提供了集合操作的基本方法。
但与List不同的是,Set还提供了equals(Object o)和hashCode(),供其子类重写,以实现对集合中插入重复元素的处理;
public interface Set extends Collection {
1:添加功能
boolean add(E e);
boolean addAll(Collection c);
2:删除功能
boolean remove(Object o);
boolean removeAll(Collection c);
void clear();
3:长度功能
int size();
4:判断功能
boolean isEmpty();
boolean contains(Object o);
boolean containsAll(Collection c);
boolean retainAll(Collection c);
5:获取Set集合的迭代器:
Iterator iterator();
6:把集合转换成数组
Object[] toArray();
T[] toArray(T[] a);
//判断元素是否重复,为子类提高重写方法
boolean equals(Object o);
int hashCode();
} 三.HashSet
在HashSet中,基本的操作都是有HashMap底层实现的(后面讲解),因为HashSet底层是用HashMap存储数据的。当向HashSet中添加元素的时候,首先计算元素的hashCode值,然后通过扰动计算和按位与的方式计算出这个元素的存储位置,如果这个位置为空,就将元素添加进去;如果不为空,则用equals方法比较元素是否相等,相等就不添加,否则找一个空位添加。
它继承于AbstractSet,实现了Set, Cloneable, Serializable接口。
(1)HashSet继承AbstractSet类,获得了Set接口大部分的实现,减少了实现此接口所需的工作,实际上是又继承了AbstractCollection类;
(2)HashSet实现了Set接口,获取Set接口的方法,可以自定义具体实现,也可以继承AbstractSet类中的实现;
(3)HashSet实现Cloneable,得到了clone()方法,可以实现克隆功能;
(4)HashSet实现Serializable,表示可以被序列化,通过序列化去传输,典型的应用就是hessian协议。
具有如下特点:
- 不允许出现重复因素;
- 允许插入Null值;
- 元素无序(添加顺序和遍历顺序不一致);
- 线程不安全,若2个线程同时操作HashSet,必须通过代码实现同步;
1. HashSet基本操作
HashSet底层由HashMap实现,插入的元素被当做是HashMap的key,根据hashCode值来确定集合中的位置,由于Set集合中并没有角标的概念,所以并没有像List一样提供get()方法。当获取HashSet中某个元素时,只能通过遍历集合的方式进行equals()比较来实现;
public class HashSetTest {
public static void main(String[] agrs){
//1、创建HashSet集合:
Set hashSet = new HashSet();
System.out.println("HashSet初始容量大小:"+hashSet.size());
//2、元素添加:
hashSet.add("my");
hashSet.add("name");
hashSet.add("is");
hashSet.add("jiaboyan");
hashSet.add(",");
hashSet.add("hello");
hashSet.add("world");
hashSet.add("!");
System.out.println("HashSet容量大小:"+hashSet.size());
//3、迭代器遍历:
Iterator iterator = hashSet.iterator();
while (iterator.hasNext()){
String str = iterator.next();
System.out.println(str);
}
//4、增强for循环
for(String str:hashSet){
if("jiaboyan".equals(str)){
System.out.println("你就是我想要的元素:"+str);
}
System.out.println(str);
}
//5、元素删除:
hashSet.remove("jiaboyan");
System.out.println("HashSet元素大小:" + hashSet.size());
hashSet.clear();
System.out.println("HashSet元素大小:" + hashSet.size());
//6、集合判断:
boolean isEmpty = hashSet.isEmpty();
System.out.println("HashSet是否为空:" + isEmpty);
boolean isContains = hashSet.contains("hello");
System.out.println("HashSet是否为空:" + isContains);
}
} 2 HashSet元素添加分析
Set集合不允许添加重复元素,那么到底是个怎么情况呢?
来看一个简单的例子:
public class HashSetTest {
public static void main(String[] agrs){
//hashCode() 和 equals()测试:
hashCodeAndEquals();
}
public static void hashCodeAndEquals(){
//1、第一个 Set集合:
Set set1 = new HashSet();
String str1 = new String("jiaboyan");
String str2 = new String("jiaboyan");
set1.add(str1);
set1.add(str2);
System.out.println("长度:"+set1.size()+",内容为:"+set1);
//2、第二个 Set集合:
Set set2 = new HashSet();
App app1 = new App();
app1.setName("jiaboyan");
App app2 = new App();
app2.setName("jiaboyan");
set2.add(app1);
set2.add(app2);
System.out.println("长度:"+set2.size()+",内容为:"+set2);
//3、第三个 Set集合:
Set set3 = new HashSet();
App app3 = new App();
app3.setName("jiaboyan");
set3.add(app3);
set3.add(app3);
System.out.println("长度:"+set3.size()+",内容为:"+set3);
}
}
长度:1,内容为:[jiaboyan]
长度:2,内容为:[com.jiaboyan.collection.App@efb78af, com.jiaboyan.collection.App@5f3306ad]
长度:1,内容为:[com.jiaboyan.collection.App@1fb030d8]可以看到,第一个Set集合中最终只有一个元素;第二个Set集合保留了2个元素;第三个集合也只有1个元素;
究竟是什么原因呢?
让我们来看看HashSet的add(E e)方法:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}在底层HashSet调用了HashMap的put(K key, V value)方法:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
} 通过查看以上的源码,我们可以了解到:实际的逻辑都是在HashMap的put()方法中。
int hash = hash(key) 对传入的key计算hash值;
int i = indexFor(hash, table.length) 对hash值进行转换,转换成数组的index(HashMap中底层存储使用了Entry
for (Entry
如果存在,则if(e.hash == hash && ((k = e.key) == key || key.equals(k)))判断;
如果不存在,则addEntry(hash, key, value, i)直接添加;
简单概括如下:
在向HashMap中添加元素时,先判断key的hashCode值是否相同,如果相同,则调用equals()、==进行判断,若相同则覆盖原有元素;如果不同,则直接向Map中添加元素;
反过来,我们在看下上面的例子:
在第一个Set集合中,我们new了两个String对象,赋了相同的值。当传入到HashMap中时,key均为“jiaboyan”,所以hash和i的值都相同。进行if (e.hash == hash && ((k = e.key) == key || key.equals(k)))判断,由于String对象重写了equals()方法,所以在((k = e.key) == key || key.equals(k))判断时,返回了true,所以第二次的插入并不会增加Set集合的长度;
第二个Set集合中,也是new了两个对象,但没有重写equals()方法(底层调用的Object的equals(),也就是==判断),所以会增加2个元素;
第三个Set集合中,只new了一个对象,调用的两次add方法都添加的这个新new的对象,所以也只是保留了1个元素;
四. TreeSet
从名字上可以看出,此集合的实现和树结构有关。与HashSet集合类似,TreeSet也是基于Map来实现。TreeSet的底层是TreeMap的keySet0,而TreeMap是基于红黑树实现的,红黑树是一种平衡二又查找树,它能保证任何一个节点的左右子树的高度差不会超过较矮的那棵的一倍。
与HashSet不同的是,TreeMap是按key排序的,元素在插入TreeSet时compareTo0方法要被调用,所以TreeSet中的元素要实现Comparable接口。TreeSet作为一种Set,它不允许出现重复元素。TreeSet是用compareTo(来判断重复元素的。
它继承AbstractSet,实现NavigableSet, Cloneable, Serializable接口。
(1)与HashSet同理,TreeSet继承AbstractSet类,获得了Set集合基础实现操作;
(2)TreeSet实现NavigableSet接口,而NavigableSet又扩展了SortedSet接口。这两个接口主要定义了搜索元素的能力,例如给定某个元素,查找该集合中比给定元素大于、小于、等于的元素集合,或者比给定元素大于、小于、等于的元素个数;简单地说,实现NavigableSet接口使得TreeSet具备了元素搜索功能;
(3)TreeSet实现Cloneable接口,意味着它也可以被克隆;
(4)TreeSet实现了Serializable接口,可以被序列化,可以使用hessian协议来传输;
具有如下特点:
- 对插入的元素进行排序,是一个有序的集合(主要与HashSet的区别);
- 底层使用红黑树结构,而不是哈希表结构;
- 允许插入Null值;
- 不允许插入重复元素;
- 线程不安全;
1. TreeSet基本操作
public class TreeSetTest {
public static void main(String[] agrs){
TreeSet treeSet = new TreeSet();
System.out.println("TreeSet初始化容量大小:"+treeSet.size());
//元素添加:
treeSet.add("my");
treeSet.add("name");
treeSet.add("jiaboyan");
treeSet.add("hello");
treeSet.add("world");
treeSet.add("1");
treeSet.add("2");
treeSet.add("3");
System.out.println("TreeSet容量大小:" + treeSet.size());
System.out.println("TreeSet元素顺序为:" + treeSet.toString());
//增加for循环遍历:
for(String str:treeSet){
System.out.println("遍历元素:"+str);
}
//迭代器遍历:升序
Iterator iteratorAesc = treeSet.iterator();
while(iteratorAesc.hasNext()){
String str = iteratorAesc.next();
System.out.println("遍历元素升序:"+str);
}
//迭代器遍历:降序
Iterator iteratorDesc = treeSet.descendingIterator();
while(iteratorDesc.hasNext()){
String str = iteratorDesc.next();
System.out.println("遍历元素降序:"+str);
}
//元素获取:实现NavigableSet接口
String firstEle = treeSet.first();//获取TreeSet头节点:
System.out.println("TreeSet头节点为:" + firstEle);
// 获取指定元素之前的所有元素集合:(不包含指定元素)
SortedSet headSet = treeSet.headSet("jiaboyan");
System.out.println("jiaboyan节点之前的元素为:"+headSet.toString());
//获取给定元素之间的集合:(包含头,不包含尾)
SortedSet subSet = treeSet.subSet("1","world");
System.out.println("1--jiaboan之间节点元素为:"+subSet.toString());
//集合判断:
boolean isEmpty = treeSet.isEmpty();
System.out.println("TreeSet是否为空:"+isEmpty);
boolean isContain = treeSet.contains("who");
System.out.println("TreeSet是否包含who元素:"+isContain);
//元素删除:
boolean jiaboyanRemove = treeSet.remove("jiaboyan");
System.out.println("jiaboyan元素是否被删除"+jiaboyanRemove);
//集合中不存在的元素,删除返回false
boolean whoRemove = treeSet.remove("who");
System.out.println("who元素是否被删除"+whoRemove);
//删除并返回第一个元素:如果set集合不存在元素,则返回null
String pollFirst = treeSet.pollFirst();
System.out.println("删除的第一个元素:"+pollFirst);
//删除并返回最后一个元素:如果set集合不存在元素,则返回null
String pollLast = treeSet.pollLast();
System.out.println("删除的最后一个元素:"+pollLast);
treeSet.clear();//清空集合:
}
} 2. TreeSet元素排序
在前面的章节,我们讲到了TreeSet是一个有序集合,可以对集合元素排序,其中分为自然排序和自定义排序,那么这两种方式如何实现呢?
首先,我们通过JDK提供的对象来展示,我们使用String、Integer:
public class TreeSetTest {
public static void main(String[] agrs){
naturalSort();
}
//自然排序顺序:升序
public static void naturalSort(){
TreeSet treeSetString = new TreeSet();
treeSetString.add("a");
treeSetString.add("z");
treeSetString.add("d");
treeSetString.add("b");
System.out.println("字母顺序:" + treeSetString.toString());
TreeSet treeSetInteger = new TreeSet();
treeSetInteger.add(1);
treeSetInteger.add(24);
treeSetInteger.add(23);
treeSetInteger.add(6);
System.out.println(treeSetInteger.toString());
System.out.println("数字顺序:" + treeSetString.toString());
}
} 测试结果:
字母顺序:[a, b, d, z]
数字顺序:[1, 6, 23, 24]
接下来,我们自定义对象,看能否实现:
public class App{
private String name;
private Integer age;
public App(){}
public App(String name,Integer age){
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public static void main(String[] args ){
System.out.println( "Hello World!" );
}
}
public class TreeSetTest {
public static void main(String[] agrs){
customSort();
}
//自定义排序顺序:升序
public static void customSort(){
TreeSet treeSet = new TreeSet();
//排序对象:
App app1 = new App("hello",10);
App app2 = new App("world",20);
App app3 = new App("my",15);
App app4 = new App("name",25);
//添加到集合:
treeSet.add(app1);
treeSet.add(app2);
treeSet.add(app3);
treeSet.add(app4);
System.out.println("TreeSet集合顺序为:"+treeSet);
}
} 测试结果:
抛出异常:提示App不能转换为Comparable对象:
Exception in thread "main" java.lang.ClassCastException: com.jiaboyan.collection.App cannot be cast to java.lang.Comparable
为什么会报错呢?
compare(key, key); // type (and possibly null) check
final int compare(Object k1, Object k2) {
return comparator==null ? ((Comparable)k1).compareTo((K)k2)
: comparator.compare((K)k1, (K)k2);
}通过查看源码发现,在TreeSet调用add方法时,会调用到底层TreeMap的put方法,在put方法中会调用到compare(key, key)方法,进行key大小的比较;
在比较的时候,会将传入的key进行类型强转,所以当我们自定义的App类进行比较的时候,自然就会抛出异常,因为App类并没有实现Comparable接口;
将App实现Comparable接口,在做比较:
public class App implements Comparable{
private String name;
private Integer age;
public App(){}
public App(String name,Integer age){
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
//自定义比较:先比较name的长度,在比较age的大小;
public int compareTo(App app) {
//比较name的长度:
int num = this.name.length() - app.name.length();
//如果name长度一样,则比较年龄的大小:
return num == 0 ? this.age - app.age : num;
}
@Override
public String toString() {
return "App{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
} 测试结果如下:
TreeSet集合顺序为:[App{name='my', age=15}, App{name='name', age=25}, App{name='hello', age=10}, App{name='world', age=20}]
此外,还有另一种方式,那就是实现Comparetor
//自定义App类的比较器:
public class AppComparator implements Comparator {
//比较方法:先比较年龄,年龄若相同在比较名字长度;
public int compare(App app1, App app2) {
int num = app1.getAge() - app2.getAge();
return num == 0 ? app1.getName().length() - app2.getName().length() : num;
}
} 此时,App不用在实现Comparerable接口了,单纯的定义一个类即可;
public class App{
private String name;
private Integer age;
public App(){}
public App(String name,Integer age){
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public static void main(String[] args ){
System.out.println( "Hello World!" );
}
}
public class TreeSetTest {
public static void main(String[] agrs){
customSort();
}
//自定义比较器:升序
public static void customComparatorSort(){
TreeSet treeSet = new TreeSet(new AppComparator());
//排序对象:
App app1 = new App("hello",10);
App app2 = new App("world",20);
App app3 = new App("my",15);
App app4 = new App("name",25);
//添加到集合:
treeSet.add(app1);
treeSet.add(app2);
treeSet.add(app3);
treeSet.add(app4);
System.out.println("TreeSet集合顺序为:"+treeSet);
}
}
测试结果:
TreeSet集合顺序为:[App{name='hello', age=10}, App{name='my', age=15}, App{name='world', age=20}, App{name='name', age=25}]
最后,在说下关于compareTo()、compare()方法:
结果返回大于0时,方法前面的值大于方法中的值;
结果返回等于0时,方法前面的值等于方法中的值;
结果返回小于0时,方法前面的值小于方法中的值;
五.扩展
1. HashSet,TreeSet,LinkedHashSet, BitSet有何区别
(1).功能不同:
HashSet是功能最简单的Set,只提供去重的能力; LinkedHashSet不仅提供去重功能,而且还能记录插入和查询顺序; TreeSet提供了去重和排序的能力: BitSet不仅能提供去重能力,同时也能减少存储空间的浪费,不过对于普通的对象不太友好,需要做额外处理
(2).实现方式不同:
HashSet基于HashMap,去重是根据HashCode和equals方法的;LinkedHashSet是基于LinkedHashMap,通过双向链表记录插入顺序; TreeSet是基于TreeMap的,去重是根据compareTo方法的;BitSet基于位数组,一般只用于数字的存储和去重
其实BitSet只是叫做Set而已,它既没有实现Collection接口,也和terable接口没有什么3关系,但是是名字相似而已
2.Set是如何保证元素不重复的
在Java的Set体系中,根据实现方式不同主要分为两大类。HashSet和TreeSet。
1.TreeSet 是二叉树实现的,TreeSet中的数据是自动排好序的,不允许放入null值; 底层基于TreeMap
2.HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束; 底层基于HashMap
在HashSet中,基本的操作都是有HashMap底层实现的,因为HashSet底层是用HashMap存储数据的。当向HashSet中添加元素的时候,首先计算元素的hashCode值,然后通过扰动计算和按位与的方式计算出这个元素的存储位置,如果这个位置为空,就将元素添加进去;如果不为空,则用equals方法比较元素是否相等,相等就不添加,否则找一个空位添加。
TreeSet的底层是TreeMap的keySet0,而TreeMap是基于红黑树实现的,红黑树是一种平衡二又查找树,它能保证任何一个节点的左右子树的高度差不会超过较矮的那棵的一倍。
TreeMap是按key排序的,元素在插入TreeSet时compareTo(方法要被调用,所以TreeSet中的元素要实现Comparable接口。TreeSet作为一种Set,它不允许出现重复元素。TreeSet是用compareTo(来判断重复元素的。