语音分离论文:Dual-Path RNN
论文标题:Dual-Path RNN: Effective Long Sequence Modeling for Time-Domain Single-Channel Speech Separation
Dual-Path RNN
- Introduction
- Dual-Path RNN三阶段
-
- Segmentation 分割阶段
- Block Processing 块处理阶段
- Overlapp-Add 重叠相加
- Results&Discussion
- Reference
Introduction
DPRNN全称是dual path RNN,翻译过来即双路径的rnn。作者把这个模型分为三个阶段,分割阶段,块处理阶段和最后的重叠相加。
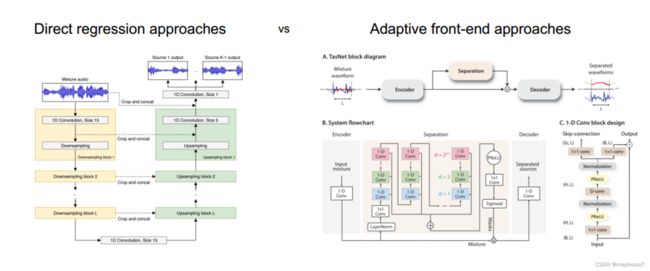
图1 两种时域语音分离方法:直接回归方法、自适应前端方法
现在常用的时域语音分离方法主要是两种,一种是直接回归,像左边这张图,其实就是我之前说过的u-net的模型。它先在左侧这一溜通过卷积池化对特征降维,然后在右边进行卷积和上采样的时候把左边的特征图拼过去,把局部信息的和全局特征进行一个融合,分离出两个特征不一样的声音。第二种方法是自适应前端方法,右边这张图是tasnet。这两种方法本质上的区别是,右边这种自适应前端的方法用了一个encoder处理输入音频,而不是直接把它拿来做卷积。那么这两种方法都有个很重要的共同点,也是实现上的难点,它们都需要对一段比较完整的长时间的输入音频段建模,再提取特征。
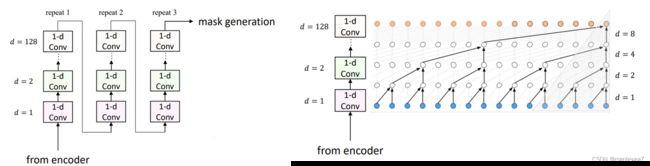
图2 Previous Method: 1-d Conv
Tasnet用很深的时间卷积网络,去感受尽可能多的采样点特征,每一层的卷积核数量是指数增长的,经过多层卷积之后最初始的输入到这个分离网络里面的采样点应该很多,对应的音频序列时间更长。这篇文章提出的DPRNN是用了不同的方法,让RNN网络来建模一个很长的序列,最终实验结果表明在tasnet里把这里的一维卷积替换成DPRNN之后,可以提高效率。
Dual-Path RNN三阶段

图3 网络总体框架
DPRNN分为分割,块处理和重叠相加三步。总的来说,分割先把输入序列分割成互相重叠的块,并且拼接为一个3维向量,接着把向量传给堆叠的DPRNN块来反复执行局部和全局建模,最后一层输出通过重叠相加,转化成输出序列。
Segmentation 分割阶段

图4 分割阶段
分割阶段的目标是把一个长序列截成小断,并列地拼起来,拼成一个叠在一起的块。需要注意的是它的截出来的相邻的小块是会有重叠的部分。设每个小块的长度是k,重叠的部分长度是p,当特例k=2p的时候,每个相邻的小块刚好有一半的部分是和前面的块是重叠的,另一半和后面的块是重叠的。假设原始序列的特征有N维,每个块长度是k,分成了s块,就会得到一个n×k×s的一个立方体,也就是一个三维张量,在这个图里k刚好等于2p。
Block Processing 块处理阶段

图5 块处理阶段
分割的步骤相当于一个预处理,接下来是这个双路径dprnn的结构。为什么它叫双路径rnn?可以看到它有一个intra-chunk rnn和一个inter-chunk rnn,即块内rnn和块间rnn。首先看左边块内rnn,块指的是在分割的时候,把长序列分成的这一段段横着的块,每个块长度是k,分成了s块。所以块内rnn,本质上是对刚刚分的每个块内部单独做rnn。块间rnn也很好理解,它是把每个块的相同坐标位置的特征取出来放一块,做rnn。如果说块内rnn学习到的可能更多的是比较局部,相邻的区域的特征的话,那块间rnn学习到的就是不同块之间的联系。可以看出来,和conv-tasnet的一点区别是,conv-tasnet是通过非常多的卷积层把视野放大,去获得比较多的连续采样点;而dprnn是把待处理的序列先分块,集中到一起,后续处理起来更方便,是一个磨刀不误砍柴工的工作。

图6 双向RNN
块内rnn和块间rnn后续的操作相同,先进行一个bi-rnn也就是双向rnn,然后是一个全连接层,再是一个layer norm,最后是一个残差连接。首先双向rnn的输入是第一阶段分割得到的张量Tb,有三个参数因为它是一个三维向量,双向rnn把它抽象成一个函数fb,最后输出一个Ub。
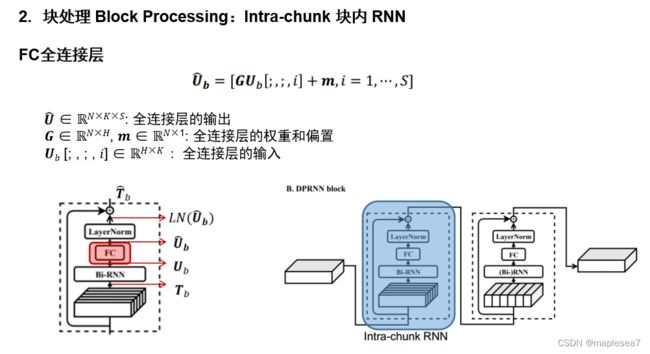
图7 FC全连接层
接下来是一个fully connection全连接层,相当于把刚刚双向rnn得到的U进行一个线性变换,得到一个U帽。这个公式就是相当于对S个三维立方体块,先乘上权重矩阵G,再加上偏置m。

图8 层归一化&残差连接
接下来是layer normalization层归一化的操作。层归一化的作用就是让每一层,这里即连续的一个句子,或者代表一段语义的序列,让它的内部实现一个标准化。因为之前一步经过了这个rnn还有全连接层,它们的权重矩阵还有偏置会让不同的层里面相差较大,所以实现归一化就是把一个层的内部看作一个分布,让一个层的内部实现标准化。
在这里它就相当于是对RNN后的结果做了层归一化。μ表示的是这个张量Ub帽的均值,sigma表示它的方差。层标准化的公式,前面部分相当于做了一个化为标准正态分布的操作,后面对应相乘的z再加上r,起到线性函数的作用,其中z可以把前面部分进行缩放,r可以控制它的偏移值。 总的来说,先把它转化成均值是1,方差是0的标准分布,再对这个数据做扩展和平移操作。通过对RNN做了一个层标准化,rnn在每个时刻输入进去的张量经过加权然后输出,最后被标准化重新调整在了一个合适的范围里面,让它的均值是1,方差是0,这样的话可以避免数据不合理的分布。如果是用梯度下降做优化的时候,数据特征分布的稳定了,就不容易出现梯度消失或者梯度爆炸的问题。
最后一步,圆圈里的小加号表示残差连接。它的操作是在层归一化输出的基础上加上一个最开始的Tb张量。这一步是为了改善梯度消失,梯度爆炸和过拟合的问题。当模型层数很深的时候,不仅不会提升模型的表达能力,反而会让模型的效果变差。比如,当一个网络通过反向传播来进行参数更新,当它某一个梯度求导得到的导数很小,那么多次连乘之后得到的梯度就可能会越来越小,最终导致梯度消失。但经过残差连接,有一个直接映射的部分Tb,再对整个这个式子右边求导,相当于多了一个常数,可以有效地避免梯度消失的问题。

图9 块间RNN
接下来是右边的部分,块间rnn。块间rnn只是在分块的时候和块内rnn不一样,后续的步骤完全一致。把每个块的相同坐标位置的特征取出来放一块,做rnn。块内rnn学习到的更多的是局部,相邻的区域的特征,块间rnn学习到的是不同块之间的联系。这里是把块内rnn这边的输出Tb帽作为块间rnn的输入,也要进行全连接层和层归一化和残差连接操作。
Overlapp-Add 重叠相加

图10 Overlap-Add 重叠相加
当所有的dprnn操作完成之后,就要把压成块状的张量重新分离开,拼成一个长序列。因为整个dprnn都没有改变这个张量的大小,还是N×k×S,所以复原出来的序列依然是初始的长度为L的N个维度的序列。
Results&Discussion

图11 DPRNN和其他模型比较
作者把基于dprnn的tasnet和之前基于卷积的tasnet做了一个比较。可以看到,由于不要过多的参数,基于dprnn的tasnet它的model size比原来更小了,并且用于衡量分离效果的这个尺度不变信噪比这个点也有了提升。

图12 LSTM导致震荡现象
作者从第一次在2017年提出tasnet这个语音分离模型开始,用的其实是lstm网络。但是后来发现lstm对于输入序列的起点在哪会比较敏感,如果起点不是一个句子的开头的时候,模型的效果就会很差。所以这张图里当起点进行偏移的时候,它的效果会时好时坏,呈现一个震荡。后来作者用很深的卷积网络来替换这个lstm,它对起点变化的鲁棒性很强。由于网络很深它也带来了一些缺点,第一个是参数量会很大,所以上周我也对深度可分离卷积进行了一个汇报,它的作用就是把卷积拆成两步来减少参数量。但网络很深还有其他的缺点,比如说容易导致梯度连乘的时候梯度消失或者梯度爆炸。

图13 DPRNN作为分离模块
所以作者在dprnn这里事先做了一个预处理,它把这个很长的特征序列进入网络之前先做了一个分割,拼接成了一个三维的张量,这样一块张量本身就对应很多的采样点,不需要一层一层很深的卷积来去扩大它的感受野。这也是dprnn比之前的时间卷积网络效果要好一些的原因。
Reference
[1] Luo Y, Chen Z, Yoshioka T. Dual-path rnn: efficient long sequence modeling for time-domain single-channel speech separation[C]// ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020: 46-50.