语音分离论文:Conv-TasNet:Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation
语音分离论文之:Conv-TasNet: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation

目录
- Conv-TasNet模型
- 深度可分离卷积
- Cov-TasNet中激活函数
- 参考文献
Conv-TasNet模型
Conv-tasnet是一个用于语音分离的一个架构,它主要由三部分组成,encoder,separator和decoder。它的整体流程是把原始音频分片喂给encoder,encoder会输出一个feature map,这个feature map被分离器separator提取出不同的掩码mask,然后mask作用在feature map上用来分离特征,分离的特征最后再用decoder还原成音频。

首先是encoder,encoder它里面其实就可以看成是一个矩阵。首先原始的混合音频分成小段,每段包含16个采样点,可以看成是一个16维的向量。这个encoder就做了一个线性变换,可以看成是一个16×512行的这样一个矩阵。矩阵有512行,即512维的基向量,然后这16个采样点的音频段,依次通过这512个基向量,起到一个过滤的作用。这512个基可能有些用来编码比较高频的信号,另外一些用来编码低频的信号。这一步相当于16个采样点的音频,即16维的向量,和16×512的矩阵相乘,最后得到512维特征向量。这一步矩阵相乘,只有线性变换,大H是非线性变换的一个激活函数,例如整流线性单元ReLU,用来增加它的非线性拟合能力。

在encoder输出512维的特征向量之后,这些特征向量就会被送到分离器separator。最下面的每个黄色的矩形都代表一个512维的向量。在这个tcn时间卷积网络里面,最下面第一层,是把这些512维的向量两两一组,通过一个卷积核,得到一个新的向量。在第二层,它会在中间间隔一个向量,也就是每两个向量取一个,通过卷积得到新的向量。第三层就是每四个向量取一个。图中的d代表间隔数,论文中叫膨胀因子,呈指数级的增长。完了之后它还要把这样的网络repeat很多次。为什么要用这么大指数爆炸级增加的网络,且还要重复?因为这样它的层数越多,它最终提取出来的掩码mask所对应的音频段的长度也就越长。最开始的时候这里的每个黄色的矩形对应了16个采样点,所以层数越多,对应的采样点就会越多,意味着可以吸收到更多采样点的特征。

经过层层卷积,最终只剩下最上面黄色矩形代表的向量。在该向量中可以认为,每个说话人它们的特征已经提取得差不多了。假设有两个说话人,就可以把这个特征向量乘上两个不同的基矩阵,最后再用sigmoid函数把值映射到0到1之间,得到两种不同的mask。用这两个mask分别和所有的encoder output的这些向量相乘,得到分离开说话人特征的向量。

最后decoder和encoder的结构类似。Decoder输入是512维的特征向量,decoder的里面是一个512×16的矩阵,用1×512的向量乘512×16的矩阵,得到的是一个16维的向量,即16个采样点组成的一段音频。

上图是论文里给出的encoder和decoder内部矩阵结构图。横轴是时间的两张图,它的时间是2毫秒,正好对应了16个采样点,即每一次输入这个encoder的音频段刚好是2毫秒,这两毫秒就包含了16个采样点。所以其实这个矩阵它在纵向上是16列的。纵轴basis index表示它的基函数的索引。前面说过这个矩阵是16×512,它有512行,即512个基。基函数里面的参数,白色表示接近0的,红色表示正数,蓝色表示负数。右边横轴是frequency的图,是把时域图转化到了频域。频域图里面大部分的频段集中在大于0.5,但不到一半的位置。它的单位是千赫兹。它的这一组基函数是基于人的发声频率设计,能够比较好地捕捉人正常说话的时候的频率范围。
深度可分离卷积
前面说到网络里为了感受到尽可能长时间的音频,或者说,为了得到尽可能多的采样点,重复了很多遍这样的指数膨胀的卷积层。既然用了这么多层的卷积,参数量自然就会非常大。所以论文里用了一种可以减少卷积操作的参数量的方法,深度可分离卷积。

为了突出深度可分离卷积的作用,把深度可分离卷积和标准卷积做一个对比。 上图展示的是标准卷积的过程。标准的cnn中,输入的feature map的通道数和卷积核的通道数一致,这样卷积核才能够一次性整体地扫描完这个feature map。假设输入的feature map是6×6,通道数是2。卷积核是3×3×2,通道数也必须是2。那么用3×3×2的卷积核去扫描6×6×2的feature map,假设步长是1,从左到右要扫描4次,从上到下也是4次,最后得到一张4×4的矩阵。如果有两个卷积核,就可以得到两张4×4的矩阵。总结一下,标准卷积,卷积核的通道数必须和feature map的通道数一样,但是至于有几个卷积核来卷积是没有限制的。
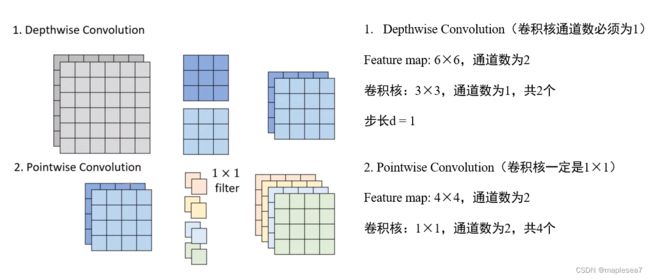
然后来看深度可分离卷积,它其实是把一次完整的卷积操作分成两步来做。第一步是depthwise convolution,用到的卷积核的通道数必须是1,就是卷积核一定只有一层,卷积核的个数和feature map的通道数相同。这里feature map有两层,通道数是2,所以它用到了两个卷积核。它的卷积操作就是用第一个卷积核去和feature map的第一层进行卷积操作,第二个卷积核去和feature map的第二层进行卷积操作,得到两个4×4的矩阵。但只有一个depthwise卷积还不够,因为这一步虽然给每一层做了卷积,但每一层之间没有关联,所以还需要用一次纵向上的卷积,来捕捉层与层之间的关联。这就用到第二步pointwise convolution。因为第一步已经给平面维度上做过卷积了,所以第二层只考虑纵向,我们只需要1×1的卷积核,在纵向的通道数上和feature map的通道数保持一致。那么1×1的卷积当然不会改变上一步得到的feature map的大小,还是4×4。这里我们也用四个卷积核,跟前面的标准卷积保持一致。最终也是得到了4张4×4的矩阵。

最后我们可以计算标准卷积和深度可分离卷积分别要用到多少个参数。这个例子标准卷积用到4个3×3,通道数为2的卷积核,所以参数量是4×3×3×2=72。在深度可分离卷积中,第一步两个平面上的卷积的参数量是3×3×2=18个,第二步纵向的卷积是4个1×1,通道数是2的卷积核,所以参数量是8个。总共加起来参数量是26个。比标准卷积操作的参数量还是要少挺多。
最后可以把它扩展到一般情况。假设卷积核的大小是k×k,输入的feature map的通道数是I,卷积核的个数是O,可以知一般情况下,标准卷积的参数量是k×k×I×O,深度可分离卷积depthwise的参数量是k×k×I,pointwise的参数量是I×O,把他们相除,就等于O分之1加k×k分之1,当卷积核的数量O很大的时候,O分之一趋于0,所以深度可分离卷积的参数量可以近似看成标准卷积的k×k分之1,就很显著地达到了给模型减少参数这样的目的。
Cov-TasNet中激活函数
 论文中的激活函数,像sigmoid,relu还有带参数的parametric relu,最后对这些激活函数稍做总结。因为模型的卷积操作是线性的,激活函数是为了增加模型的非线性拟合能力。
论文中的激活函数,像sigmoid,relu还有带参数的parametric relu,最后对这些激活函数稍做总结。因为模型的卷积操作是线性的,激活函数是为了增加模型的非线性拟合能力。

Sigmoid激活函数,会把输入映射到0到1之间。一般用σ表示。同时它的导数也很容易计算,根据解析式它的导数可以写成1加e的负y次方分之1对y的导数,然后用复合函数求导法则求导,再把它分解成两个分式相乘,可以得到图中最下面这个等号后面的形式。式中左边部分就是σ,右边部分就是1-σ,所以最终sigmoid函数的导数就是σ乘上(1-σ)。Sigmoid函数的导数图像如上图,前面这个线性单元输出的y的值非常大或者非常小的时候,sigmoid函数的导数是趋于0的,而且不管怎么取值,导数的最大值都是0.25,这意味着神经网络反向传播的时候,每一层的梯度会缩小四分之一。
sigmoid函数有个特点是会让收敛变慢。上图右边的图中,如果神经元的输入是x1和x2,它们是上一层sigmoid函数的输出,所以x1x2均大于0。进行反向传播后得到w1和w2的梯度。基于前面的分析,两个式子里面σ×(1-σ)×x1和σ×(1-σ)×x2这两个部分始终大于0,所以w1和w2的梯度正负完全取决于损失函数对o的导数,所以w1和w2的梯度正负始终一致,即它们会同时进行正向或者反向更新,这样会让神经网络收敛得更慢。
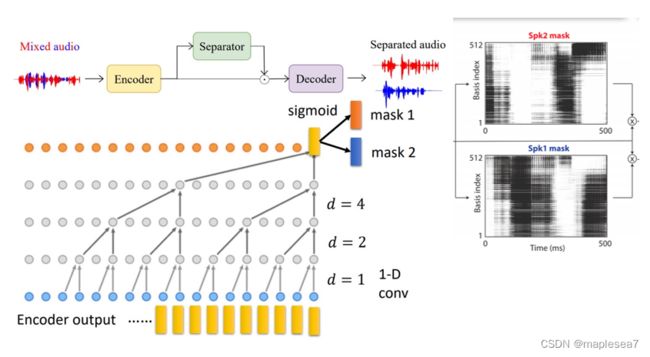
在论文中的sigmoid函数是在求mask掩码时,让掩码向量都取在0到1中间,形成黑白灰度图像。让mask向量中的值都在0到1之间,这些0到1之间的值代表mask向量每一个维度属于不同说话人的置信度。比如说mask1里面某一个dimension的值可能是0.1,那就大概率不是第一个的说话人的特征,接近1则很可能是第一个说话人的特征。

模型中还用到ReLU。ReLU函数在大于0的时候是一个正比例的映射,但会抑制小于0的输入,只保留正数部分。只有当神经元输出大于0的时候才会回传梯度,小于0的时候就不会进行反向传播。同时ReLu函数在训练时可以动态控制神经元的状态,要么激活大于0,要么等于0被抑制。因为部分的神经元的输出被抑制了,所以当输入改变的时候只有一部分的神经元需要改变状态。从而可以说降低了信息耦合程度。
ReLU函数一个缺点是它的输出没有上界,如果ReLU函数前面的线性单元的输出很大,或者当网络有循环结构的时候,就会导致梯度爆炸,就需要进行参数初始化。另外还有个问题是网络中的一些神经元可能输出一直是负数,就会一直被抑制,导致神经元坏死。为了解决这个问题,2013年提出了一种leaky relu函数对relu函数做了一点改进,在relu函数的负半轴增加了一个很小但固定的梯度值0.01,从而避免神经元坏死。在2015年又提出了parametric relu函数,它把负半轴的梯度值更换成了可以动态学习调整的参数,是否去抑制这个神经元,是不是要去保留这个网络的稀疏性,都要通过训练过程来决定。论文中用到的Parametric relu,就是用来在每一次线性的卷积之间不断地添加非线性函数,同时又让这个负半轴的梯度值可以通过训练来调节,不至于让神经元坏死。共同点即通过让负半轴不恒等于0,保持住了特征的表达能力,也可以动态地改变这个负半轴的梯度参数,更加灵活。
参考文献
[1] Luo, Y., & Mesgarani, N. (2019). Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM transactions on audio, speech, and language processing, 27(8), 1256-1266.
[2] Xu B, Wang N, Chen T, et al. Empirical evaluation of rectified activations in convolutional network[J]. arXiv preprint arXiv:1505.00853, 2015.