AAAI 2024 | 中科院信工所提出结构化概率编码框架,有效增强预训练语言模型泛化能力

论文题目:
Structured Probabilistic Coding
论文录用:
AAAI 2024 Main Technical Track
论文链接:
https://arxiv.org/abs/2312.13933
代码链接:
https://github.com/zerohd4869/SPC
作者主页:
https://hudou95.github.io/

摘要
本文介绍了一种新的监督表示学习框架,名为结构化概率编码 SPC,用于从输入中学习与目标任务相关的紧凑且有信息量的概率表示。SPC 是一种仅含编码器的概率编码技术,并结合了来自目标任务空间的结构化正则。它能够增强预训练语言模型的泛化能力,实现更好的语言理解。
具体而言,所提出的概率编码技术在一个模块中同时进行信息编码和任务预测,以更充分地利用来自输入数据中的有效信息。它在输出空间中使用变分推断以减少随机性和不确定性。
同时,为了更好地控制潜在空间中的概率分布,引入了一种结构化正则方法,以促进潜在空间中类别级别的均匀性。在结合正则项的概率编码框架下,SPC 可以保留潜在编码的高斯分布结构,并更好地实现潜在空间的类均匀覆盖。
在 12 个自然语言理解任务上的实验结果表明,提出的 SPC 框架有效地提高了预训练语言模型在分类和回归任务上的性能。扩展实验表明,SPC 可以增强模型的泛化能力,对标签噪声的鲁棒性,以及输出表示的聚类质量。

引言
概率嵌入(Probabilistic Embedding)是一种新兴的表示学习技术,其目的在于学习数据的潜在概率分布。相比确定性嵌入(Deterministic Embedding),概率嵌入更加适合描述数据的不确定性和复杂性,能够更好地处理冗余信息,提供更准确的表示。这种方法已经广泛应用于计算机视觉和自然语言处理等领域。
大部分概率嵌入方法建立在信息瓶颈(Information Bottleneck,IB)原理的基础上,其目的是找到关于输入的最大压缩表示,同时保留与目标任务尽可能多的信息,从而在压缩和预测之间取得平衡。
这些基于信息瓶颈的方法通常涉及两个参数模块,即编码器和解码器。通常,编码器将输入映射到潜在空间中的概率分布,而解码器将概率分布映射到目标任务空间中的输出表示。
然而,在编码器-解码器架构下,编码器将输入数据映射到概率分布的过程可能会丢失一些与任务相关的信息,这些信息对于解码器在学习过程中至关重要。
这是因为概率分布固有地包含随机性和不确定性,这些随机因子可能与任务无关并干扰解码器的任务预测过程。为了解决该问题,本文提出了一种仅包含编码器的概率编码(Probabilistic Coding)技术,将信息编码和任务预测结合到一个模块中。
通过在输出空间中使用变分推断,可以更好地控制和利用数据的随机性和不确定性。该方法学习到的紧凑表示可以充分捕获数据的潜在结构,并保留与目标任务相关的有效信息。这有助于提高模型的泛化性能,特别是在面对有限数据或带噪标签时。
此外,尽管概率嵌入方法能够捕获数据的不确定性和复杂性,但它们通常受约束于训练数据的有限性和有偏性。这些数据难以充分代表目标任务的真实分布。在编码器将输入数据映射到概率分布的过程中,可能会丢失一些与任务相关的重要信息。任务信息量的不足会导致模型泛化能力不足以及在新数据上的性能不佳。
为了提高潜在表示的任务预测能力,本文利用目标任务空间的结构信息来约束潜在空间概率分布的学习过程。在概率编码框架内,潜在空间的结构化正则(Structured Regularization)可以帮助模型学习与目标任务相关的更多信息,从而提高模型在新数据上的预测准确性。
本文提出的结构化概率编码(Structured Probabilistic Coding, SPC)是一种新的监督表示学习框架。该框架是一种仅含编码器的概率编码技术,并结合来自目标标签空间的结构化正则。通过从输入中提取紧凑且任务信息丰富的概率表示,SPC 可以增强预训练语言模型的泛化能力,以实现更好的语言理解。
其中,概率编码技术通过变分近似,将输入编码为高斯分布空间下的随机输出表示,同时最小化给定表示下目标标签的条件熵。同时,结构化正则项鼓励多元高斯分布下潜在空间内的类级均匀性,使潜在空间分布更好地反映目标任务空间的结构信息,这有利于任务预测。
在结合正则项的概率编码框架下,SPC 可以保持输入空间中邻域的高斯结构,同时在潜在空间实现保持类级均匀性的最佳覆盖。
我们在 12 个自然语言理解任务上进行了实验,包括 10 个分类任务(如表情预测、仇恨言论检测、讽刺检测、攻击性语言检测、情感分析、立场检测、不同领域的情绪检测等)和 2 个回归任务(包括语义相似度预测和合理澄清排序)。
结果表明,提出的 SPC 方法有效地提高了预训练语言模型在分类和回归任务上的性能。以使用 RoBERTa 作为网络骨架为例,与传统的 CE/MSE 学习目标相比,SPC 将分类和回归任务的平均性能分别提高了约 +4.0% 和 +1.5%。
与对比方法相比,包括确定性嵌入技术(即 CE/MSE、CE/MSE+CP、CE+AT 和 CE+SCL)和概率嵌入技术(即 VIB、MINE-IB 和 MEIB),SPC 框架在不同的基础骨架(如 BERT 和 RoBERTa)下始终取得了最佳的平均性能。广泛的实验表明,SPC 可以增强模型的泛化能力(包括数据受限和分布外场景),对标签噪声的鲁棒性,以及输出表示的聚类质量。
主要贡献:
-
我们提出了一种仅含编码器的概率编码方法,将信息编码和任务预测集成到一个模块中,从输入中最大限度地保留了与目标任务相关的有效信息。
-
我们设计了一个结构化正则项来促进潜在空间中类级的一致性,以获得更好的概率嵌入的任务预测能力。
-
我们提出了一个监督表示学习框架 SPC,从输入中学习紧凑且任务信息丰富的概率表示。它可以增强预训练语言模型的泛化能力,以实现更好的语言理解。
-
12个基准测试的实验表明,在不同的网络骨架下,SPC 在分类和回归任务上均实现了最先进的性能。扩展实验表明 SPC 可以增强预训练模型的泛化能力、对标签噪声的鲁棒性,以及输出表示的聚类质量。

方法
结构化概率编码(Structured Probabilistic Coding, SPC)是一种监督式表示学习框架,旨在从输入中学习紧凑且任务信息丰富的概率表示。如图1(c)所示,SPC 是一种只包含编码器的结构化概率编码技术,并结合了来自目标任务空间的结构化正则。

▲ 图1 SPC 与两类主流监督表示学习框架的编码方式比较
3.1 概率编码
概率编码(Probabilistic Coding)将信息编码和任务预测整合到一个模块中。与现有的应用编码器-解码器架构的概率嵌入方法不同,我们的编码器模型可以有效地保留与任务相关的特征,并避免概率化编码过程中的随机性和不确定性带来的负面影响。
在假设 ,对应于马尔可夫链 的前提下,我们的目标是最小化输入 和潜在表示 之间的互信息,同时最大化表示 与目标标签 之间的信息。具体而言,我们使用变分近似将每个输入 编码成输出空间 中的高斯分布表示 ,即 。
此外,我们通过估计表示 给定目标标签 的条件熵,最大化 的下限。概率编码的目标函数可以表示为:
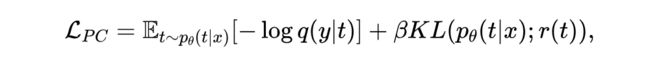
这里 是一个非参数操作,即 argmax 函数。 是 的先验 的估计。 是 的后验概率的变分估计,并由随机编码器 学习。 表示 KL 散度,用作正则化项,迫使 的后验概率近似于先验 。 是控制 对 预测能力和 从 中的压缩程度之间的权衡超参数。
在我们的概率编码方法中,先验 是各向同性高斯分布。变分近似后验 是一个具有对角协方差结构的多元高斯分布,即 ,其中 和 分别代表均值和对角协方差,它们的参数都是依赖于输入的,并由一个多层感知机(MLP,具有单隐藏层的全连接神经网络)预测。
由于 的采样是一个随机过程,我们应用重参数化技巧来确保模型的梯度无偏。
在现有基于信息瓶颈原理的方法中,其解码器 可以是 的参数近似,即压缩表示 可以从分布 中采样,这意味着噪声的特定模式被添加到 的输入中。这种噪声可能会削弱 传达的信息,并可能导致解码器 在学习过程中丢失关键的任务相关信息。
不同于它们,我们的概率编码应用非参数操作来进行预测,并将概率编码和任务预测整合到了一个编码器模块中。它可以有效地避免概率编码中随机性和不确定性带来的负面影响。
3.2 结构化正则
上述提到的马尔可夫假设限制了表示 不能直接依赖于目标标签 ,这意味着对 的学习未能充分利用任务空间的信息。因此,所学得的表示不能充分代表目标任务的真实分布,在从有限或有偏数据中学习时导致泛化能力差。因此,我们设计了一种新的结构化正则(Structured Regularization)来探索标签空间的潜在模式。
具体而言,我们在目标函数中添加了一个关于潜在分布的附加项,以最大化 在标签空间上的先验熵:

在实现中,我们利用每个采样批次的数据估计 ,并应用 Jensen 不等式和蒙特卡洛方法估计其下界:

这里 表示第 个目标标签变量的平均预测概率。这样,我们可以通过计算批次熵 估计 ,其度量了在标签空间中预测概率分布的不确定性或多样性。
这种正则化项促进了潜在空间中不同类别之间的均匀性学习过程,防止模型过度强调训练数据中某些不准确代表真实数据分布的主要特征或标签。
3.3 结构化概率编码
我们将来自目标任务空间的结构化正则项融入到了概率编码框架中,称为结构化概率编码(SPC)。SPC 的总目标可以表示为

这里 是控制正则化强度的超参数。前两项将概率编码和任务预测整合到了一个编码器模块中。第三项是结构化正则项,促进了潜在空间中的类别均匀性。SPC 的目标是在输入空间中保持邻域的高斯结构,并在潜在空间中实现类均匀性的最佳覆盖。
3.4 应用于下游任务
我们将 SPC 框架应用于各种自然语言理解(NLU)任务,以增强预训练语言模型在任务中的泛化能力。由于其学习信息丰富而又紧凑的表示能力,SPC 框架非常适用于分类和回归任务。对于分类任务, 的下限可以相当于经典的交叉熵损失。
同样地,对于回归任务, 的下限可以等同于经典的均方误差损失。

实验
4.1 任务测评
表 1 汇报了在 10 个分类基准任务上的总体结果。与比较方法相比,我们的 SPC 始终获得最佳平均性能。当使用 BERT 和 RoBERTa 网络骨架时,与 CE 相比,SPC 可以分别将所有分类任务的平均性能提高 +3.1% 和 **+4.0%**。
结果表明我们的方法对未见过的测试集具有良好的泛化能力,并显示出在分类任务上的优越性。

▲ 表1 在 10 个分类基准任务上的性能评估。汇报结果采取了在 5 个 seed 下训练的模型在测试集上的平均表现,下同。
表 2 汇报了在两个回归基准任务上的总体结果。SPC 在两个数据集上都获得了更好的回归结果。此外,当使用 RoBERTa 网络骨架时,与 MSE 相比,SPC 在平均性能方面实现了 +1.5% 的绝对提升。这证明了 SPC 对于回归任务中未见过的测试集的优越性和泛化性。

▲ 表2 在 2 个回归基准任务上的性能评估。网络架构以 RoBERTa 为例,下同。
4.2 消融分析
我们通过移除结构化正则(w/o Structured)和概率编码(w/o Probabilistic)来进行消融研究。对于分类,表3显示了所有任务的消融结果。当去掉结构化正则项时,SPC w/o Structured 在所有分类指标方面获得较差的性能。
当进一步移除概率编码时,结果显着下降。它揭示了结构化正则和概率编码的有效性。对于回归,由于其标签空间是一维实数,因此 SPC 退化为概率编码,去掉概率编码的 SPC w/o Probabilistic 相当于标准 MSE。
从表 2 可以看出,回归指标的平均性能下降了 1.5%,这证实了概率编码回归的有效性。

▲ 表3 消融实验结果
4.3 泛化评估
我们在以下两种设置下进一步评估 SPC 的泛化能力:使用有限数据进行训练和在分布外(OOD)场景中进行测试。
4.3.1 不同训练数据规模下的性能评估
我们在不同比例的训练集下进行实验,以评估有限数据训练时的泛化能力。图2显示了 CE、VIB、MEIB 和 SPC 在 RoBERTa 网络骨架下的不同训练集大小的结果。
与 CE、VIB 和 MEIB 相比,SPC 在大多数数据集上针对不同比例的训练集都取得了优异的性能。这表明即使在训练数据受限的条件下,SPC也可以增强预训练语言模型的泛化能力。

▲ 图2 在不同训练集大小下的泛化性评估
4.3.2 分布外泛化性评估
我们选择与情绪相关的基准,包括 EmotionEval、ISEAR、MELD 和 GoEmotions,这些基准旨在预测情绪状态,但收集自不同的领域。
表4展示了分布外场景下的性能。我们的 SPC 在所有分布外设置下都获得了最佳结果。这一事实表明,SPC 在处理跨不同领域转移的分布外场景时具有更好的泛化能力。
一方面,SPC 利用输出空间的变分推理,可以更好地控制和利用数据的随机性和不确定性。另一方面,SPC 引入了目标任务空间的结构信息,使得潜在空间概率分布更好地反映任务相关信息,并将模型推广到新数据。

▲ 表4 在OOD场景下的泛化性评估
4.4 鲁棒性评估
我们通过评估模型处理噪声标签的能力来进行实验来证明鲁棒性。如表5所示,在所有设置下,SPC 始终优于 CE、VIB 和 MEIB。
这表明 SPC 在噪声训练数据上表现更稳健。此外,与 CE 相比,SPC 在噪声比为 10%、20% 和 30% 的情况下,在分类任务上的平均性能分别提高了 +2.0%、+2.1% 和 +1.7%。
结果证明 SPC 能够更好地控制和利用数据的随机性和不确定性。

▲ 表5 不同标签噪声下的鲁棒性评估
4.5 表示质量评估
为了评估表示的质量,我们评估了通过不同优化目标获得的输出表示的聚类性能。我们应用轮廓系数(silhouette coefficient, SC)和调整兰德指数(adjusted rand index, ARI)分别衡量获得的表示与输入数据和目标标签相关的聚类能力。
如图3所示,与大多数数据集中的其他目标(CE、VIB 和 MEIB)相比,SPC 实现了更高的 ARI 或 SC 值。这表明 SPC 有效地实现了数据编码和任务预测之间的平衡,从而促进了预训练语言模型在下游任务中的泛化性。

▲ 图3 输出表示的聚类质量评估

总结
本文提出了一种新的结构化概率编码(SPC)框架,用于从输入中提取紧凑且有任务信息量的概率表示。它可以增强预训练语言模型的泛化能力,以实现更好的语言理解。具体而言,仅含编码器的概率编码技术同时进行信息编码和任务预测。此外,引入结构化正则来控制概率分布并促进潜在空间中的类级均匀性。
结合该正则项,SPC 可以保持输入空间中邻域的高斯结构,同时在潜在空间实现保持类别均匀性的最佳覆盖。12 个基准测试的实验表明,SPC 在多种分类和回归任务上均取得了最佳性能。扩展实验表明,SPC 可以增强预训练语言模型的泛化能力、对标签噪声的鲁棒性,以及输出表示的聚类质量。