【JAVAEE】文件操作——IO
目录
1. 冯·诺伊曼体系
2. 内存与外存的区别
✨3. 文件
3.1 认识文件
✌3.2 文件的管理
3.3 文件路径
3.4 文件的保存
3.4.1 文本文件
3.4.2 二进制文件
3.5 文件系统操作
3.6 文件内容操作
3.7 文件操作示例
3.7.1 示例1 扫描指定目录,并找到名称或者内容中包含指定字符的所有普通文件(不包含目录)
1. 冯·诺伊曼体系
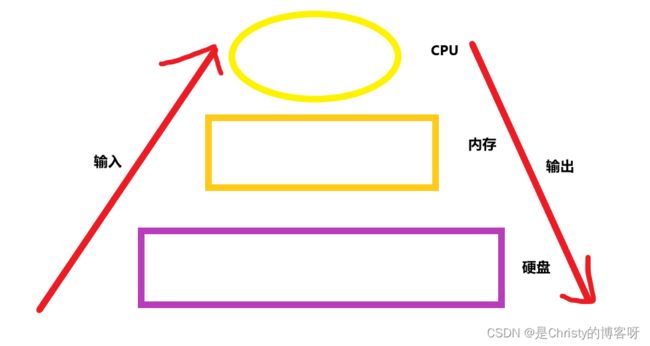
我们知道,现代的计算机是基于冯·诺伊曼体系设计出来的,该体系的基本内容如下:
1. 计算机内部采用二进制来表示指令和数据。每条指令一般具有一个操作码和一个地址码。其中操作码表示运算性质,地址码指出操作数在存储中的位置。
2. 采取存储程序的思想。将程序和数据事先送入存储器中,使计算机在工作时能够自动地高速地从存储器中取出指令加以执行。
3. 计算机由运算器、控制器、存储器、输入设备和输出设备五大基本部件组成。
这个体系第一次从根本上定制了计算机基本架构,并且把计算机组成的各个关键部位完整分割开来,使之互不干扰又能协同工作。尽管计算机的制造技术发生着日新月异的变化,但就其体系结构而言,计算机设备到现在为止一直沿袭这个体系。
下面继续深入了解一下计算机的五大基本组成部件。
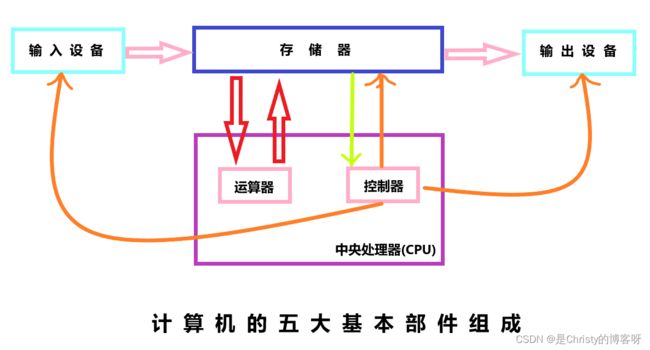
1.运算器
运算器由算术逻辑单元(ALU)、累加器、状态寄存器、通用寄存器组等组成,是对数据信息进行加工和处理的部件,它能够完成各种算术运算和逻辑运算,所以也叫作“算术逻辑运算部件”。算术运算包括加、减、乘、除等运算;逻辑运算包括与、或、非等运算。在运算过程中,运算器不断得到由存储器提供的数据,运算后又把结果送回到存储器保存起来。整个运算过程是在控制器统一指挥下,按程序中编排的操作顺序进行的。
2.控制器
控制器(Controller)控制和协调整个计算机的动作,其工作由程序计数器(PC)、指令寄存器(IR)、指令译码器(ID)、定时与控制电路,以及脉冲源、中断等共同完成。控制器是分析和执行指令的部件,是控制计算机各个部件有条不紊地协调工作的指挥中心。控制器从存储器中逐条取出指令、分析指令,然后根据指令要求完成相应操作,产生一系列控制命令,使计算机各部分自动、连续并协调工作,成为一个有机的整体,实现程序输入、数据输入以及运算并输出结果。
目前的制作工艺通常把运算器、控制器及部分的存储器集成在一块芯片上,统称为中央处理器(CPU),CPU是计算机的核心和关键,计算机的性能主要取决于CPU。3.存储器
存储器(Memory)是用来存放输入设备送来的程序和数据,以及运算器送来的中间结果和最后结果的记忆装置。存储器能容纳的二进制信息的总量称为存储容量,一般用字节数B表示容量的大小。存储容量的单位还有千字节(KB)、兆字节(MB)、吉字节(GB)和太字节(TB)等。存储器又分内存储器和外存储器:
(1)内存储器
内存储器是CPU能根据地址线直接寻址的空间,曾出现过磁芯材料制作的内存储器,但现在绝大多数由半导体器件制成。内存是主机的一部分,用来存放正在执行的程序或数据,与CPU直接交换信息。其特点是存取速度快,但容量相对较小。内存按其功能和存储信息又可分成两大类,即只读存储器和随机存储器。
(2)外存储器
外存储器在过去是一种辅助存储器,主要用来存放一些计算机并不时常调用的程序和数据。当需要执行外存中的程序或处理外存中的数据时,必须通过CPU输入/输出指令,将其调入RAM中才能被CPU执行和处理,其性质与输入/输出设备相同,其存取速度相对较慢。随着科技的发展,外存储器的规格不断改进,容量不断变大,访问速度不断提高,同时计算机程序的大小几何级数增加,使得计算机越来越依赖外存储器作为大容量存储空间的作用。目前外存储器已经不仅仅是一种辅助工具,而是计算机系统的重要组成部分,在某些行业甚至还起到了关键的作用。
常见的外存储器有硬盘、光盘、U盘等。
4.输入设备
输入设备(Input Device)是用户将数据和程序输入计算机中的重要工具,一般由输入装置和输入接口两部分组成。输入装置为可见的物理装置如键盘、鼠标、摄像头、麦克风等;而输入接口包括物理和逻辑两部分,物理部分指输入装置和计算机的物理连线,逻辑部分指的是操作系统为对应输入装置提供的逻辑数据入口。
5.输出设备
输出设备(Output Device)一般是计算机工作循环的最后一个部分,其作用是将计算机的工作结果展示出来。常见的输出装置有显示器、投影仪、音响等。与输入设备类似,输出设备也分输出装置和输出接口两部分。
2. 内存与外存的区别
1. 内存访问速度快,而外存访问速度慢,前者比后者快了3~4个数量级。
2. 内存的空间比较小,而外存的空间比较大,比如笔者此时的电脑,内存8GB,硬盘225GB
3. 内存制作成本高,而外存成本低。几百块能买到一个很好的1T~2T的固态硬盘,而好一点的16GB的内存条,也得几百上千。
4. 内存中的数据,断电之后会丢失,而外存的数据,断电之后依旧存在。也就意味着,内存存储的数据是“易失”的,而外存存储的数据,是“持久”的。
3. 文件
3.1 认识文件
我们先来认识狭义上的文件(file)。针对硬盘这种持久化存储的 I/O 设备,当我们想要进行数据保存时,往往不是保存成一个整体,而是独立成一个个的单位进行保存,这个独立的单位就被抽象成文件的概念, 就类似办公桌上的一份份真实的文件一般。
文件除了有数据内容之外,还有一部分信息,例如文件名、文件类型、文件大小等并不作为文件的数据而存在,我们把这部分信息可以视为文件的元信息。
3.2 文件的管理
随着文件越来越多,那我们该如何组织文件呢,一种合乎自然的想法出现了,就是按照层级结构进行组织 —— 也就是我们数据结构中学习过的树形结构。这样,一种专门用来存放管理信息的特殊文件诞生了,也就是我们平时所谓文件夹(folder)或者目录(directory)的概念。
在我们打开 “此电脑” 后,会发现有的文件没有大小,甚至有时候得连续打开好几个没有大小的文件,没错了,这就是管理文件的文件夹。
3.3 文件路径
那到底该如何才能在众多文件中找到那个想要的文件呢?
文件路径:从树根结点出发,沿着树杈(沿着文件夹),一路往下查找,到达目标文件,这中间经过的所有内容。
Windows 都是从“此电脑”开始的。表示路径的时候,可以把“此电脑”省略,直接由盘符开始,相当于根结点。
实际表示路径时,是通过一个字符串来表示的,每个目录(文件夹)之间使用 / (斜杠)或者 \ (反斜杠,只能在 windows 中使用,代码中需要写成 \\ , 需要转义字符)来进行分割。
举个例子,在C盘中找一份pdf文件,它的路径表示为:
C:\Apps\4.JavaEE初阶
路径有绝对路径与相对路径之分,下面举一个具体例子来进行解释。
绝对路径(absolute path):从盘符开始,一层一层往下找,得到的路径
相对路径(relative path):从给定的某个目录出发,一层一层往下找,得到的路径
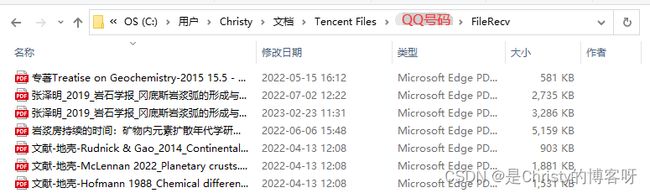
对于 “专著Treatise on Geochemistry-2015 15.5 - Sample Digestion Methods.pdf” 这个文件来说,它的绝对路径为:
C:/用户/Christy/文档/Tencent Files/1234567/FileRecv/专著Treatise on Geochemistry-2015 15.5 - Sample Digestion Methods.pdf
相对路径随着工作路径的不同而不同。
如果工作目录是这样子的:
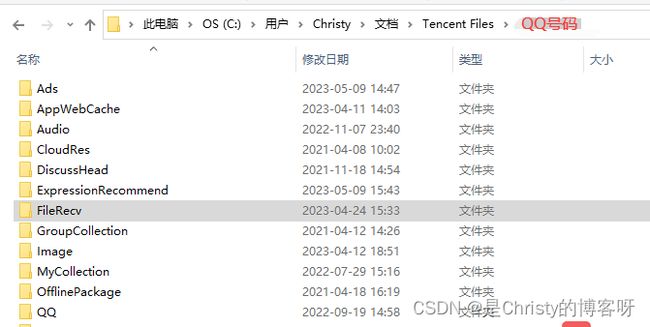
那么相对路径为:
./FileRecv/专著Treatise on Geochemistry-2015 15.5 - Sample Digestion Methods.pdf
如果工作目录为:
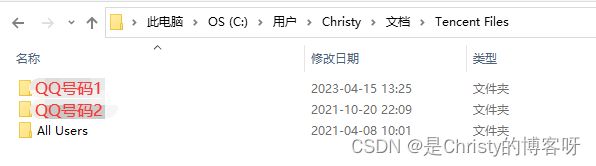
那么相对路径为:
./QQ号码1/FileRecv/专著Treatise on Geochemistry-2015 15.5 - Sample Digestion Methods.pdf
. 在相对路径中,是一个特殊符号,表示当前目录。 .. 也是特殊符号,表示当前目录的上级目录。
注意事项:
1. 相对路径,一定要明确工作目录是啥,即基准目录
2. 绝对路径,可以理解成以“此电脑”为工作路径
文件系统中,任何一个文件,对应的路径是唯一的。不存在两个路径相同,但文件不同的情况。在 Linux 中则可能存在一个文件,有两个不同路径能找到它,而 Windows 上这种事情不可能发生。Windows 上可以认为,路径和文件是一一对应的,也就是说路径相当于一个文件的 “身份标识”。
3.4 文件的保存
在计算机中,所有数据在存储和运算时,都要使用二进制数来表示,而具体用哪些二进制数字表示哪个符号,这就是编码。编码是信息从一种形式转换为另一种形式的过程;解码则是编码的逆过程。为了让所有的计算机间能够相互通信,那么这些计算机就得使用同样的编码规则。
普通文件,根据保存数据的不同,划分成不同的类型,简单的划分为文本文件和二进制文件。文本文件是基于字符编码的文件,常见的编码有 ASCII 编码,UNICODE 编码等等。二进制文件是基于值编码的文件。
3.4.1 文本文件
ASCII
ASCII ,是 American Standard Code for Information Interchange 的缩写,即美国信息交换标准代码,是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
ASCII码有两种类型,7位ASCII码以及8位ASCII码。7位ASCII码也叫标准ASCII码,用一个字节(8个比特位)表示一个字符,并规定其最高位为0,实际只用到7位,码值为00000000~01111111,即 0~127。因此可表示 128 个不同字符 。这对于使用英语这种语言的国家来说,128个字符是足够的。
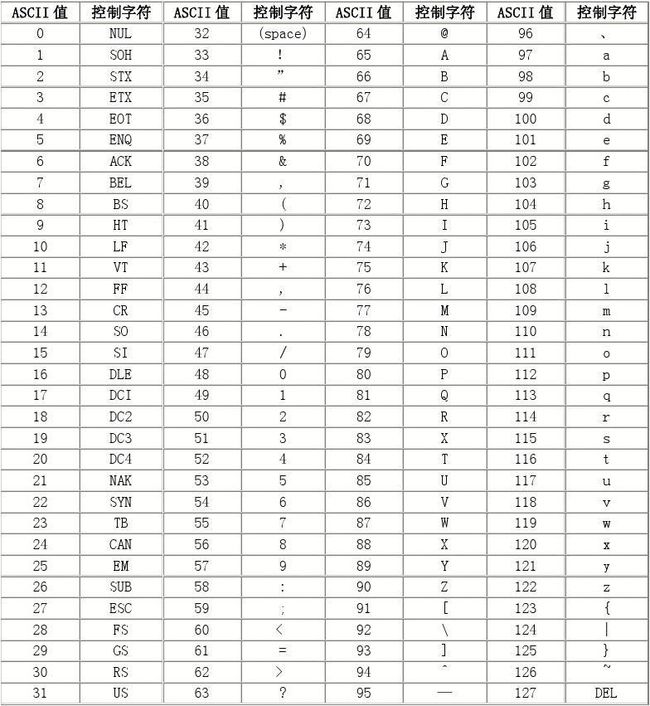
可对于像法语这种,字母头上有符号的语言来说,标准ASCII码值显然是不够的。人们就想,能不能把闲置的最高位也拿来编入新符号,这便是8位ASCII码。但是这也会导致新的问题,不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母也不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。对于亚洲国家来说,符号就更多了。汉字根据不完全统计,约有15万个,这远不是256个符号就能概括的。这也就意味着汉字需要另外的编码。
这个世界上有多种语言,也就需要多种的编码,这会造成同一个二进制数字表示不同的符号。那么当人们去打开一个文本文件时,就必须事先知道它的编码方式,否则就会以错误的编码去解读,造成乱码。
那么全世界的计算机又该如何进行沟通呢?
这便是 Unicode,它将这世界上所有的符号都纳入其中,给每一个符号都分配了独一无二的二进制编码。
UNICODE
Unicode ,即统一码,是为了解决传统的字符编码方案局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,这里的二进制数值也叫码点,以满足跨语言、跨平台进行文本转换、处理的要求。
Unicode 字符集的编码范围是 0x0000 - 0x10FFFF , 可以容纳一百多万个字符。
需要注意的是,Unicode 只规定了符号的二进制编码,但并没有规定其存储方式。
为了讲解清楚,有以下情况是需要知道的。
我们已经清楚, 对于英语这门语言来说,一个字节就足以描述,但如果使用了 Unicode 的统一编码,利用 2 ~ 4 不等的字节去表示一个字符的话,那就意味着有字节浪费了,当文本文件很大的时候,也就浪费了很大的空间。
所以对于 Unicode 来说,它有很多存储的方式。如UTF-8、UTF-16、以及 UTF-32。
UTF-8 的最大特点就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
3.4.2 二进制文件
二进制文件存储 0 和 1 这样的二进制数据。常见的二进制文件有,图像、音频、视频以及程序文件等。
3.5 文件系统操作
文件操作可分为两大类:
1. 文件系统操作,包括创建文件、删除文件、重命名文件、创建目录......
2. 文件内容操作,包括读和写。
文件是存储在硬盘中的,直接通过代码来操作硬盘,不大方便;但可以在内存中创建一个对应的对象,操作这个内存中的对象,就可以间接影响到硬盘的文件情况了,就像是遥控器一样。
Java 标准库中,提供了 File 这个类,其对象是硬盘上一个文件的抽象表示。
File 类的构造方法与方法介绍:
| 构造方法 | 说明 |
| File(File parent, String child) | 根据父目录 + 孩子文件路径,创建一个新的 File 实例 |
| File(String pathname) | 根据文件路径创建一个新的 File 实例,路径可以是绝对路径或者相对路径 |
| File(String parent, String child) | 根据父目录 + 孩子文件路径,创建一个新的 File 实例,父目录用路径表示 |
| 返回值类型 | 方法 | 说明 |
| String | getParent() | 返回 File 对象的父目录文件路径 |
| String | getName() | 返回 FIle 对象的纯文件名称 |
| String | getPath() | 返回 File 对象的文件路径 |
| String | getAbsolutePath() | 返回 File 对象的绝对路径 |
| String | getCanonicalPath() | 返回 File 对象的修饰过的绝对路径 |
| boolean | exists() | 判断 File 对象描述的文件是否真实存在 |
| boolean | isDirectory() | 判断 File 对象代表的文件是否是一个目录 |
| boolean | isFile() | 判断 File 对象代表的文件是否是一个普通文件 |
| boolean | createNewFile() | 根据 File 对象,自动创建一个空文件。成功创建后返 回 true |
| boolean | delete() | 根据 File 对象,删除该文件。成功删除后返回 true |
| void | deleteOnExit() | 根据 File 对象,标注文件将被删除,删除动作会到 JVM 运行结束时才会进行 |
| String[] | list() | 返回 File 对象代表的目录下的所有文件名 |
| File[] | listFiles() | 返回 File 对象代表的目录下的所有文件,以 File 对象表示 |
| boolean | mkdir() | 创建 File 对象代表的目录(一级) |
| boolean | mkdirs() | 创建 File 对象代表的目录,如果必要,会创建中间目录 |
| boolean | renameTo(File dest) | 进行文件改名,也可以视为我们平时的剪切、粘贴操作 |
| boolean | canRead() | 判断用户是否对文件有可读权限 |
| boolean | canWrite() | 判断用户是否对文件有可写权限 |
构造 File 对象
构造过程中,使用绝对路径/相对路径进行初始化,这个路径指向的文件,可以是真实存在的,也可以是不存在的。
public class IODemo1 {
public static void main(String[] args) throws IOException {
File file = new File("./dog!.jpg");
System.out.println(file.getParent());
System.out.println(file.getName());
System.out.println(file.getPath());
System.out.println(file.getAbsolutePath());
System.out.println(file.getCanonicalPath());
}
}此处相对路径的当前工作目录是 IDEA 创建的位置。
当然了,也可以利用 File 里面的方法来创建一个新的文件。
public class IODemo2 {
public static void main(String[] args) throws IOException {
File file = new File("./welcome to the adulthood!.txt");
System.out.println(file.exists());
System.out.println(file.isDirectory());
System.out.println(file.isFile());
//创建文件
file.createNewFile();
System.out.println(file.exists());
System.out.println(file.isDirectory());
System.out.println(file.isFile());
}
}运行结果:
false
false
false
true
false
true
删除之后:
file.delete();
System.out.println("删除文件之后————");
System.out.println(file.exists());运行结果:
false
创建目录:多级目录与一级目录
import java.io.File;
import java.io.IOException;
public class IODemo3 {
public static void main(String[] args) throws IOException {
File file = new File("file-dir/aaa/bbb");
// 创建多级目录
file.mkdirs();
file.createNewFile();
System.out.println(file.getAbsolutePath());
}
}输出:
C:\code\may-2023\2023_5_10\file-dir\aaa\bbb
而对于 mkdir() 这个方法而言,它只能创建一级目录。
import java.io.File;
import java.util.Arrays;
public class IODemo4 {
public static void main(String[] args) {
File file = new File("file-dir");
String[] results = file.list();
System.out.println(Arrays.toString(results));
File[] results2 = file.listFiles();
System.out.println(Arrays.toString(results2));
}
}运行结果:
[aaa]
[file-dir\aaa]
重命名
import java.io.File;
public class IODemo5 {
public static void main(String[] args) {
File file = new File("./file-dir");
File dest = new File("./test222");
file.renameTo(dest);
}
}
3.6 文件内容操作
IO,是 input 和 output 的缩写,输入输出的意思,指应用程序和外部设备之间的数据传递,常见的外部设备包括文件、管道、网络连接等。
Java 是通过流来处理 IO 的。
流(Stream),是一个抽象的概念,是指一连串的数据(字符或字节),是以先进先出的方式发送信息的通道。
流的特性如下:
1. 先进先出:最先写入输出流的数据最先被输入流读取到。
2. 顺序存取:可以一个接一个地往流中写入一串字节,读出时也将按写入顺序读取一串字节,不能随机访问中间的数据。(
RandomAccessFile除外)3. 只读或只写:每个流只能是输入流或输出流的一种,不能同时具备两个功能,输入流只能进行读操作,对输出流只能进行写操作。在一个数据传输通道中,如果既要写入数据,又要读取数据,则要分别提供两个流。
针对文本文件,Java 提供了一组类,统称 “字符流” ,读写的单位为字符;针对二进制文件,Java 提供了另一组类,统称为 “字节流” ,读写的单位为字节。
而上述的两类流对象,又可以进一步的分为输入流(Reader、InputStream)和输出流(Writer、OutputStream)。输入与输出是相对于 CPU 来说的,比如文件读写,读取文件是数据从硬盘来到 CPU ,为输入流,写文件是数据从 CPU 到硬盘,为输出流。
下面拿 InputStream 来举例子。

我们发现,InputStream 被 abstract 修饰,即 InputStream 是抽象类,也就意味着不能直接实例化,但我们可以实例化 InputStream 的子类,FileInputStream,来进行文件读取。
需要注意的是:InputStream 不仅仅可以读写硬盘的文件,还可以读写网卡等。
文件的关闭操作是非常重要的!
前面学过进程,它是用 PCB 这样的结构来表示的:
1. pid
2. 内存指针
3. 文件描述符表
文件描述符表记载了进程都打开了哪些文件,每打开一个文件,都会在这个表中申请到一个位置。可以把这个表当成一个数组,数组的下标是文件描述符,而数组的元素是这个文件在内核中的结构体表示。由于文件描述符表的长度是有限的,如果无休止的打开文件,却都不释放(没有进行文件的关闭,在这个过程中,每一个忘记关闭的文件,都会造成一次文件资源泄漏,直到这个表满了),那么这个表就会满。一旦满了,后续文件就会打开失败!所以一定要进行文件的关闭!!
import java.io.InputStream;
public class IODemo6 {
public static void main(String[] args) throws IOException{
//test.txt 已事先创建,里面的内容为 hello world
//相当于打开文件
InputStream inputStream = new FileInputStream("./test.txt");
System.out.println(inputStream.read());
// ************************
inputStream.close();
}
}输出:
104 (h 的 ASCII 码值)
但这样子写真的就万无一失了吗?在 ******* 那一行中,如果出现一些问题,比如 return 、抛异常了,就会导致 close 执行不了。所以对上述代码进行如下修改:
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
public class IODemo6 {
public static void main(String[] args) throws IOException{
InputStream inputStream = null;
try {
inputStream = new FileInputStream("./test.txt");
} finally {
inputStream.close();
}
}
}Java 中提供了一种不需要手动写 close 的语法,如下:

try with resources,带有资源的 try 操作,会在 try 代码块结束之后,自动执行 close 操作。这也是因为 InputStream 实现了一个接口 Closeable。
在讲解清楚文件的打开和关闭之后,下面讲解该如何去读:
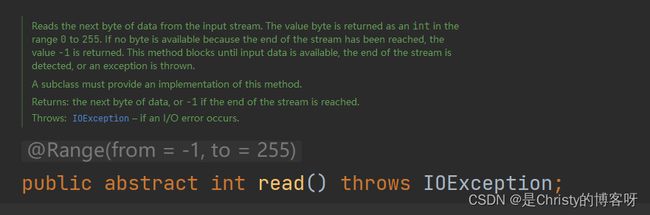
使用 read 来读取文件中的字节
1. 无参数的 read,每次读取一个字节,但返回类型却是 int 。为什么不使用 byte 或是short 呢?出于内存对齐的考虑,使用 4 个字节的 int 读取速度反而更快了,虽然会浪费一些空间,但在如今的时代,这点空间也不算什么了。
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
public class IODemo6 {
public static void main(String[] args) throws IOException{
try(InputStream inputStream = new FileInputStream("./test.txt")){
while(true){
int a = inputStream.read();
if(a == -1){
//文件读到末尾了,返回 - 1
break;
}
System.out.println(a);
}
}
}
}输出:
104
101
108
108
111
32
119
111
114
108
100
因为 InputStream 是字节流,读取的字节,这一个个的数字,是字符对应的 ASCII 码值。
如果 test.txt 里面是汉字呢?修改里面的内容为 你好世界,再次运行程序,结果如下:
228
189
160
229
165
189
228
184
150
231
149
140
这里输出了 12 个数字,每个数字是1个字节,也就意味着,1个汉字3个字节,使用的是 UTF-8 编码。
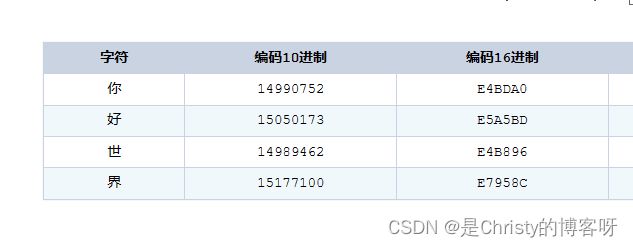
再将程序的输出结果按16进制去输出:
e4
bd
a0
e5
a5
bd
e4
b8
96
e7
95
8c
最后介绍该如何去写文件:
import java.io.*;
public class IODemo7 {
public static void main(String[] args) {
//写文件
try(OutputStream outputStream = new FileOutputStream("./test.txt")) {
outputStream.write(102);
outputStream.write(105);
outputStream.write(98);
} catch (IOException e) {
e.printStackTrace();
} ;
}
}
对于字符流来说,整个流程跟字节流相似,直接给出代码如下:
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;
public class IODemo8 {
public static void main(String[] args) {
try(Reader reader = new FileReader("./test.txt")){
while(true){
int c = reader.read();
if(c == -1){
break;
}
char ch = (char)c;
System.out.println(ch);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}输出:
a
b
c
d
e
f
g
h
i
j
k
3.7 文件操作示例
3.7.1 示例1 扫描指定目录,并找到名称或者内容中包含指定字符的所有普通文件(不包含目录)
实现思路:
1. 先去递归遍历根目录下的所有目录
2. 每次找到一个文件,都打开,并读取文件内容(得到 String)
3. 判定要查询的词是否在上述文件内容中存在。如果存在,结果即为所求。
这种实现方式并不高效,小规模可行。更高效的实现,需要依赖“倒排索引”这样的数据结构。
import java.io.*;
import java.util.Scanner;
public class IODemo9 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// 1. 让用户指定一个要搜索的根目录
System.out.println("请输入要扫描的根目录:");
File rootDir = new File(scanner.next());
if(!rootDir.isDirectory()){
System.out.println("输入有误,你输入的目录不存在!");
return;
}
// 2. 让用户输入一个要查询的词
System.out.println("请输入要查询的词:");
String word = scanner.next();
// 3. 递归的进行目录/文件的遍历
scanDir(rootDir, word);
}
private static void scanDir(File rootDir, String word){
//列出当前 rootDir 中的内容,没有内容,直接递归结束
File[] files = rootDir.listFiles();
if(files == null){
// 当前 rootDir 是一个空的目录
// 没有必要往里递归了
return;
}
// 目录里有内容,就遍历目录中的每个元素
for(File f : files){
System.out.println("当前搜索到:" + f.getAbsolutePath());
if(f.isFile()){
//是普通文件
//打开文件,读取内容,比较看是否包含上述关键词
String content = readFile(f);
if(content.contains(word)){
System.out.println(f.getAbsolutePath() + "包含要查找的关键字!");
}else if(f.isDirectory()){
//是目录
//进行递归操作
scanDir(f, word);
}else{
//不是普通文件,也不是目录文件,直接跳过
continue;
}
}
}
}
private static String readFile(File f){
//读取文件的整个内容,并返回String
//用字符流来读取
StringBuilder stringBuilder = new StringBuilder();
try(Reader reader = new FileReader(f)){
while(true){
int c = reader.read();
if(c == -1){
break;
}
stringBuilder.append((char)c);
}
} catch (IOException e) {
e.printStackTrace();
}
return stringBuilder.toString();
}
}输出:
请输入要扫描的根目录:
../2023_5_11
请输入要查询的词:
hello
当前搜索到:C:\code\may-2023\2023_5_11\..\2023_5_11\.idea
当前搜索到:C:\code\may-2023\2023_5_11\..\2023_5_11\2023_5_11.iml
当前搜索到:C:\code\may-2023\2023_5_11\..\2023_5_11\out
当前搜索到:C:\code\may-2023\2023_5_11\..\2023_5_11\src
当前搜索到:C:\code\may-2023\2023_5_11\..\2023_5_11\test.txt

