C/C++学习笔记——C基础:数组和字符串
概述
在程序设计中,为了方便处理数据把具有相同类型的若干变量按有序形式组织起来——称为数组。
数组就是在内存中连续的相同类型的变量空间。同一个数组所有的成员都是相同的数据类型,同时所有的成员在内存中的地址是连续的。

数组属于构造数据类型:
- 一个数组可以分解为多个数组元素:这些数组元素可以是基本数据类型或构造类型。
int a[10];
struct Stu boy[10];
- 按数组元素类型的不同,数组可分为:数值数组、字符数组、指针数组、结构数组等类别。
int a[10];
char s[10];
char *p[10];
通常情况下,数组元素下标的个数也称为维数,根据维数的不同,可将数组分为一维数组、二维数组、三维数组、四维数组等。通常情况下,我们将二维及以上的数组称为多维数组。
一维数组
一维数组的定义和使用
- 数组名字符合标识符的书写规定(数字、英文字母、下划线)
- 数组名不能与其它变量名相同,同一作用域内是唯一的
- 方括号[]中常量表达式表示数组元素的个数
int a[3]表示数组a有3个元素
其下标从0开始计算,因此3个元素分别为a[0],a[1],a[2]
- 定义数组时[]内最好是常量,使用数组时[]内即可是常量,也可以是变量
#include 一维数组的初始化
在定义数组的同时进行赋值,称为初始化。全局数组若不初始化,编译器将其初始化为零。局部数组若不初始化,内容为随机值。
int a[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };//定义一个数组,同时初始化所有成员变量
int a[10] = { 1, 2, 3 };//初始化前三个成员,后面所有元素都设置为0
int a[10] = { 0 };//所有的成员都设置为0
//[]中不定义元素个数,定义时必须初始化
int a[] = { 1, 2, 3, 4, 5 };//定义了一个数组,有5个成员
数组名
数组名是一个地址的常量,代表数组中首元素的地址。
#include 强化训练
- 一维数组的最值
#include - 一维数组的逆置
#include - 冒泡法排序
#include 二维数组
二维数组的定义和使用
二维数组定义的一般形式是:
类型说明符 数组名[常量表达式1][常量表达式2]
其中常量表达式1表示第一维下标的长度,常量表达式2 表示第二维下标的长度。
int a[3][4];
-
命名规则同一维数组
-
定义了一个三行四列的数组,数组名为a其元素类型为整型,该数组的元素个数为3×4个,即:
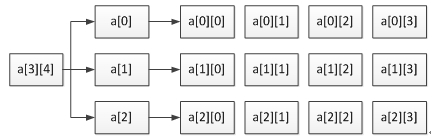
二维数组a是按行进行存放的,先存放a[0]行,再存放a[1]行、a[2]行,并且每行有四个元素,也是依次存放的。
- 二维数组在概念上是二维的:其下标在两个方向上变化,对其访问一般需要两个下标。
- 在内存中并并存在二维数组,二维数组实际的硬件存储器是连续编址的,也就是说内存中只有一维数组,即放完一行之后顺次放入第二行,和一维数组存放方式是一样的。
#include 二维数组的初始化
//分段赋值 int a[3][4] = {{ 1, 2, 3, 4 },{ 5, 6, 7, 8, },{ 9, 10, 11, 12 }};
int a[3][4] =
{
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8, },
{ 9, 10, 11, 12 }
};
//连续赋值
int a[3][4] = { 1, 2, 3, 4 , 5, 6, 7, 8, 9, 10, 11, 12 };
//可以只给部分元素赋初值,未初始化则为0
int a[3][4] = { 1, 2, 3, 4 };
//所有的成员都设置为0
int a[3][4] = {0};
//[]中不定义元素个数,定义时必须初始化
int a[][4] = { 1, 2, 3, 4, 5, 6, 7, 8};
数组名
数组名是一个地址的常量,代表数组中首元素的地址。
#include 强化训练
#include 多维数组(了解)
多维数组的定义与二维数组类似,其语法格式具体如下:
数组类型修饰符 数组名 [n1][n2]…[nn];
int a[3][4][5];
定义了一个三维数组,数组的名字是a,数组的长度为3,每个数组的元素又是一个二维数组,这个二维数组的长度是4,并且这个二维数组中的每个元素又是一个一维数组,这个一维数组的长度是5,元素类型是int。
#include 字符数组与字符串
字符数组与字符串区别
- C语言中没有字符串这种数据类型,可以通过char的数组来替代;
- 字符串一定是一个char的数组,但char的数组未必是字符串;
- 数字0(和字符‘\0’等价)结尾的char数组就是一个字符串,但如果char数组没有以数字0结尾,那么就不是一个字符串,只是普通字符数组,所以字符串是一种特殊的char的数组。
#include 字符串的初始化
#include 字符串的输入输出
由于字符串采用了’\0’标志,字符串的输入输出将变得简单方便。
#include 强化训练:字符串追加
#include 函数的调用:产生随机数
当调用函数时,需要关心5要素:
- 头文件:包含指定的头文件
- 函数名字:函数名字必须和头文件声明的名字一样
- 功能:需要知道此函数能干嘛后才调用
- 参数:参数类型要匹配
- 返回值:根据需要接收返回值
#include 字符串处理函数
- gets()
#include gets(str)与scanf(“%s”,str)的区别:
- gets(str)允许输入的字符串含有空格
- scanf(“%s”,str)不允许含有空格
注意:由于scanf()和gets()无法知道字符串s大小,必须遇到换行符或读到文件结尾为止才接收输入,因此容易导致字符数组越界(缓冲区溢出)的情况。
char str[100];
printf("请输入str: ");
gets(str);
printf("str = %s\n", str);
- fgets()
#include fgets()在读取一个用户通过键盘输入的字符串的时候,同时把用户输入的回车也做为字符串的一部分。通过scanf和gets输入一个字符串的时候,不包含结尾的“\n”,但通过fgets结尾多了“\n”。fgets()函数是安全的,不存在缓冲区溢出的问题。
char str[100];
printf("请输入str: ");
fgets(str, sizeof(str), stdin);
printf("str = \"%s\"\n", str);
- puts()
#include #include - fputs()
#include fputs()是puts()的文件操作版本,但fputs()不会自动输出一个’\n’。
printf("hello world");
puts("hello world");
fputs("hello world", stdout);
- strlen()
#include char str[] = "abcdefg";
int n = strlen(str);
printf("n = %d\n", n);
- strcpy()
#include 注意:如果参数dest所指的内存空间不够大,可能会造成缓冲溢出的错误情况。
char dest[20] = "123456789";
char src[] = "hello world";
strcpy(dest, src);
printf("%s\n", dest);
- strncpy()
#include char dest[20] ;
char src[] = "hello world";
strncpy(dest, src, 5);
printf("%s\n", dest);
dest[5] = '\0';
printf("%s\n", dest);
- strcat()
#include char str[20] = "123";
char *src = "hello world";
printf("%s\n", strcat(str, src));
- strncat()
#include char str[20] = "123";
char *src = "hello world";
printf("%s\n", strncat(str, src, 5));
- strcmp()
#include char *str1 = "hello world";
char *str2 = "hello mike";
if (strcmp(str1, str2) == 0)
{
printf("str1==str2\n");
}
else if (strcmp(str1, str2) > 0)
{
printf("str1>str2\n");
}
else
{
printf("str1);
}
- strncmp()
#include char *str1 = "hello world";
char *str2 = "hello mike";
if (strncmp(str1, str2, 5) == 0)
{
printf("str1==str2\n");
}
else if (strcmp(str1, "hello world") > 0)
{
printf("str1>str2\n");
}
else
{
printf("str1);
}
- sprintf()
#include char dst[100] = { 0 };
int a = 10;
char src[] = "hello world";
printf("a = %d, src = %s", a, src);
printf("\n");
int len = sprintf(dst, "a = %d, src = %s", a, src);
printf("dst = \" %s\"\n", dst);
printf("len = %d\n", len);
- sscanf()
#include char src[] = "a=10, b=20";
int a;
int b;
sscanf(src, "a=%d, b=%d", &a, &b);
printf("a:%d, b:%d\n", a, b);
- strchr()
#include char src[] = "ddda123abcd";
char *p = strchr(src, 'a');
printf("p = %s\n", p);
- strstr()
#include char src[] = "ddddabcd123abcd333abcd";
char *p = strstr(src, "abcd");
printf("p = %s\n", p);
- strtok()
#include - 在第一次调用时:strtok()必需给予参数s字符串
- 往后的调用则将参数s设置成NULL,每次调用成功则返回指向被分割出片段的指针
char a[100] = "adc*fvcv*ebcy*hghbdfg*casdert";
char *s = strtok(a, "*");//将"*"分割的子串取出
while (s != NULL)
{
printf("%s\n", s);
s = strtok(NULL, "*");
}
- atoi()
#include 类似的函数有:
- atof():把一个小数形式的字符串转化为一个浮点数。
- atol():将一个字符串转化为long类型
char str1[] = "-10";
int num1 = atoi(str1);
printf("num1 = %d\n", num1);
char str2[] = "0.123";
double num2 = atof(str2);
printf("num2 = %lf\n", num2);