Linux内存管理:(九)内存规整
文章说明:
-
Linux内核版本:5.0
-
架构:ARM64
-
参考资料及图片来源:《奔跑吧Linux内核》
-
Linux 5.0内核源码注释仓库地址:
zhangzihengya/LinuxSourceCode_v5.0_study (github.com)
1. 引言
伙伴系统以页面为单位来管理内存,内存碎片也是基于页面的,即由大量离散且不连续的页面组成的。从内核角度来看,出现内存碎片不是好事情,有些情况下物理设备需要大段的连续的物理内存,如果内核无法满足,则会发生内核错误。对于内存碎片化,需要重新规整一下,因此本文叫作内存规整,—些文献中称其为内存紧凑,它是为了解决内核碎片化而出现的一个功能。
内核中去碎片化的基本原理是按照页面的可移动性将页面分组。迁移内核本身使用的物理内存的实现难度和复杂度都很大,因此目前的内核不迁移内核本身使用的物理页面。对于用户进程使用的页面,实际上通过用户页表的映射来访问。用户页表可以移动和修改映射关系,不会影响用户进程,因此内存规整是基于页面迁移实现的。
2. 内存规整的基本原理
在 Linux 2.6.24 内核中集成了社区专家 Mel Gorman 的 Anti-fragmentation 补丁,其核心思想是把内存页面按照可移动、可回收、不可移动等特性进行分类。可移动的页面通常是指用户态程序分配的内存,移动这些页面仅仅需要修改页表映射关系,代价很低;可回收的页面是指不可以移动但可以释放的页面。按照这些类型分类页面后,就容易释放出大块的连续物理内存。
内存规整机制(如下图所示):有两个方向的扫描者,一个从zone头部向zone尾部方向扫描,查找哪些页面是可以迁移的;另一个从zone尾部向zone头部方面扫描,查找哪些页面是空闲页面。当这两个扫描者在zone中间碰头或者已经满足分配大块内存 的需求时(能分配出所需要的大块内存并且满足最低的水位要求),就可以退出扫描了。

Linux 内核中触发内存规整的途径:
- 手动触发。通过写1到 /proc/sys/vm/compact_memory 节点,会手动触发内存规整。它会扫描系统中所有的内存节点上的 zone,对每个 zone 都会做一次内存规整。
- kcompactd 内核线程。和页面回收 kswapd 内核线程—样,每个内存节点会创建一个 kcompactd 内核线程,名称为”kcompactd0”“kcompactd1”等。
- 直接内存规整。和页面回收—样,当页面分配器发现在低水位情况下无法满足页面分配时,会进入慢速路径。在慢速路径里,除了唤醒 kswapd 内核线程外,还会调用函数 __alloc_pages_direct_compact(),尝试整合出一大块空闲内存。
注意:页面回收是基于内存节点的,而内存规整机制是基于zone来进行扫描和规整的
3. 直接内存规整
内存规整的一个重要的应用场景是在分配大块连续物理内存(order> 1),低水位(WMARK_LOW)情况下分配失败时,唤醒 kswapd 内核线程,但依然无法分配出内存,因此调 用 __alloc_pages_direct_compact() 来压缩内存,并尝试分配出所需要的内存,这个过程如下图所示。
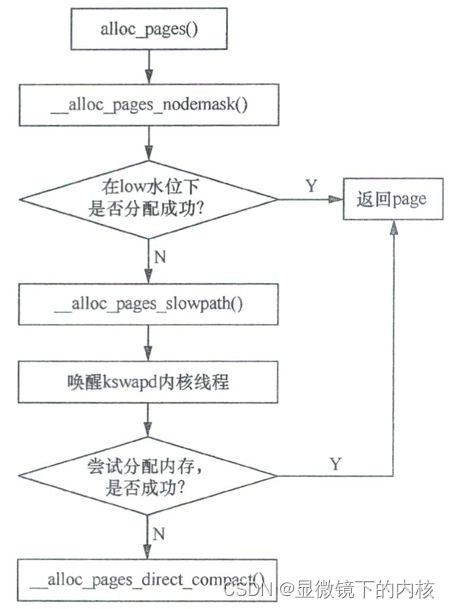
紧接着,__alloc_pages_direct_compact():
// 压缩内存,并尝试分配出所需要的内存
// gfp_mask: 传递给页面分配器的分配掩码
// order: 请求分配页面的大小,其大小为 2 的 order 次幂个物理页面
// alloc_flags: 页面分配器内部使用的分配标志位
// ac: 页面分配器内部使用的分配上下文描述符
// prio: 内存规整的优先级
// compact_result: 内存规整后返回的结果
static struct page *
__alloc_pages_direct_compact(gfp_t gfp_mask, unsigned int order,
unsigned int alloc_flags, const struct alloc_context *ac,
enum compact_priority prio, enum compact_result *compact_result)
{
...
// 遍历内存节点中所有的 zone ,在每个 zone 上进行内存规整
*compact_result = try_to_compact_pages(gfp_mask, order, alloc_flags, ac,
prio);
...
// 尝试分配内存
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
...
return NULL;
}
__alloc_pages_direct_compact()->try_to_compact_pages():
enum compact_result try_to_compact_pages(gfp_t gfp_mask, unsigned int order,
unsigned int alloc_flags, const struct alloc_context *ac,
enum compact_priority prio)
{
...
// 首先遍历内存节点中所有的 zone ,然后在每个 zone 上调用 compact_zone_order() 函数进行内存规整
for_each_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx,
ac->nodemask) {
...
status = compact_zone_order(zone, order, gfp_mask, prio,
alloc_flags, ac_classzone_idx(ac));
...
}
return rc;
}
__alloc_pages_direct_compact()->try_to_compact_pages()->compact_zone_order():
// 初始化内部使用的 compact_control 数据结构,然后调用 compact_zone 进行内存规整
static enum compact_result compact_zone_order(struct zone *zone, int order,
gfp_t gfp_mask, enum compact_priority prio,
unsigned int alloc_flags, int classzone_idx)
{
...
struct compact_control cc = {
.nr_freepages = 0,
.nr_migratepages = 0,
.total_migrate_scanned = 0,
.total_free_scanned = 0,
.order = order,
.gfp_mask = gfp_mask,
.zone = zone,
.mode = (prio == COMPACT_PRIO_ASYNC) ?
MIGRATE_ASYNC : MIGRATE_SYNC_LIGHT,
.alloc_flags = alloc_flags,
.classzone_idx = classzone_idx,
.direct_compaction = true,
.whole_zone = (prio == MIN_COMPACT_PRIORITY),
.ignore_skip_hint = (prio == MIN_COMPACT_PRIORITY),
.ignore_block_suitable = (prio == MIN_COMPACT_PRIORITY)
};
...
ret = compact_zone(zone, &cc);
...
return ret;
}
__alloc_pages_direct_compact()->try_to_compact_pages()->compact_zone_order()->compact_zone():
// 内存规整的核心函数,主要用于“兵分两路”扫描一个 zone,找出可以迁移的页面以及空闲页面。这两路“兵”会在 zone 的中间汇合,
// 然后调用页面迁移的接口函数进行页面迁移,最终整理出大块空闲页面
// zone:表示待扫描的 zone
// cc:表示内存规整中内部使用的控制参数(这个参数需要被调用者初始化)
static enum compact_result compact_zone(struct zone *zone, struct compact_control *cc)
{
...
// compaction_suitable() 主要根据当前的 zone 水位来判断是否需要进行内存规整
ret = compaction_suitable(zone, cc->order, cc->alloc_flags,
cc->classzone_idx);
...
// 内存规整的核心处理部分
// compact_finished() 函数用于判断内存规整是否可以结束了,内存规整结束的条件有两个:
// 1. cc->migrate_pfn 和 cc->free_pfn 两个指针相遇(这两个指针从 zone 的一头一尾向中间方向运行)
// 2. 判断 zone 里面 order 对应的迁移类型的空闲链表是否有成员(zone->free_area[order].free_list
// [MIGRATE_MOVABLE]),最好 order 对应的 free_area 链表中正好有成员,即有空闲页块,或者大于
// order 的空闲链表里有空闲页块,或者大于 pageblock_order 的空闲链表中有空闲页块。若对应的迁移
// 类型中的空闲链表没有空闲对象,那么假设可以从其他迁移类型中“借”一些空闲块过来
while ((ret = compact_finished(zone, cc)) == COMPACT_CONTINUE) {
...
// isolate_migratepages() 用于扫描并且寻觅 zone 中可迁移的页面,可迁移的页面会被添加到 cc->
// migratepages 链表中
switch (isolate_migratepages(zone, cc)) {
...
}
// migrate_pages() 是页面迁移的核心函数,从 cc->migratepages 链表中获取页面,然后尝试迁移页面
err = migrate_pages(&cc->migratepages, compaction_alloc,
compaction_free, (unsigned long)cc, cc->mode,
MR_COMPACTION);
}
...(代码逻辑如下图所示)
}
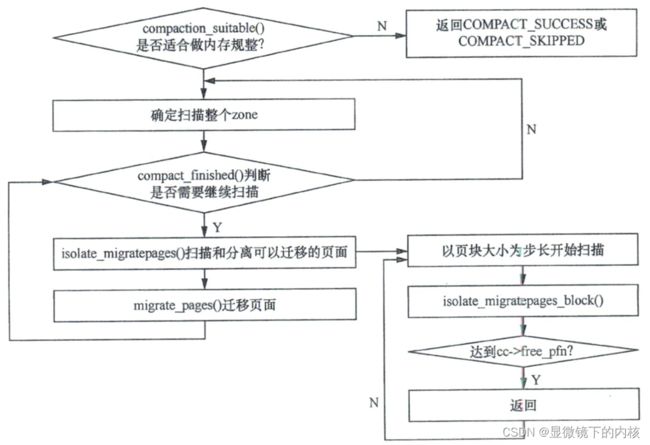
__alloc_pages_direct_compact()->try_to_compact_pages()->compact_zone_order()->compact_zone()->isolate_migratepages():
// 主要作用是扫描并且寻觅 zone 中可迁移的页面,扫描步长是按照页块大小来进行的
// zone:表示正在扫描的 zone
// cc:表示内存规整的内部使用的控制参数
static isolate_migrate_t isolate_migratepages(struct zone *zone,
struct compact_control *cc)
{
...
// isolate_mode 表示分离模式,判断是否支持异步分离模式(ISOLATE_ASYNC_MIGRATE)
const isolate_mode_t isolate_mode =
(sysctl_compact_unevictable_allowed ? ISOLATE_UNEVICTABLE : 0) |
(cc->mode != MIGRATE_SYNC ? ISOLATE_ASYNC_MIGRATE : 0);
// cc->migrate_pfn 表示上次扫描结束时的页帧号,然后从这次 cc->migrate_pfn 开始扫描
low_pfn = cc->migrate_pfn;
// pageblock_start_pfn() 表示向页块起始地址对齐
block_start_pfn = pageblock_start_pfn(low_pfn);
// block_start_pfn 表示这次扫描的起始页帧号
if (block_start_pfn < zone->zone_start_pfn)
block_start_pfn = zone->zone_start_pfn;
...
// 以 block_end_pfn 为起始页帧号开始扫描,查找的步长以 pageblock_nr_pages 为单位
// Linux 内核以页块为单位来管理页的迁移属性
for (; block_end_pfn <= cc->free_pfn;
low_pfn = block_end_pfn,
block_start_pfn = block_end_pfn,
block_end_pfn += pageblock_nr_pages) {
...
// pageblock_pfn_to_page() 函数返回这个页块中第一个物理页面的 page 数据结构
page = pageblock_pfn_to_page(block_start_pfn, block_end_pfn,
zone);
...
// 判断页块的迁移类型
// 对于异步类型的内存规整,只支持迁移类型为可移动(MOVABLE)的页块
// 对于同步模式的内存规整,要判断页块迁移类型。若当前的页块的迁移类型和请求页面的迁移类型不一致,那么会跳过这个页块
if (!suitable_migration_source(cc, page))
continue;
// isolate_migratepages_block() 函数对页块里的页面执行分离任务
low_pfn = isolate_migratepages_block(cc, low_pfn,
block_end_pfn, isolate_mode);
...
}
...
}
__alloc_pages_direct_compact()->try_to_compact_pages()->compact_zone_order()->compact_zone()->isolate_migratepages()->isolate_migratepages_block():
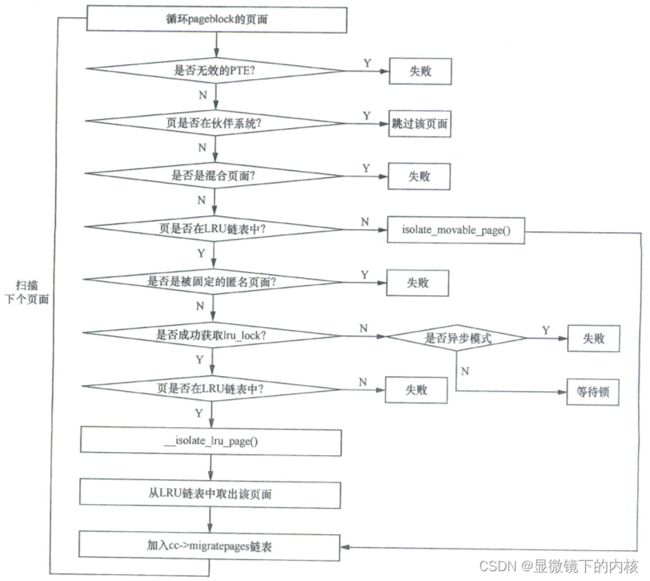
由上图可知,和页面迁移类似,有两类页面适合做内存规整:
- 传统的LRU页面,如匿名页面和文件映射页面
- 非LRU页面,即特殊的可以迁移的页面,如根据zsmalloc机制和virtio-balloon机制分配的页面
但是对于传统的LRU页面,并不是所有的页面都适合做内存规整,有一些特殊的情况我们需要考虑:
- 在伙伴系统中的页面
- 混合页面
- 不在LRU链表中的页面
- 被锁住的匿名页面
- 对于异步模式来说,获取zone->zone_pgdat->lru_lock自旋锁失败的页面
- 标记了PG_unevictable的页面不适合
- 对于异步模式来说,正在回写中的页面(标记了PG_writeback的页面)不适合
- 对于异步模式来说,没有定义mapping->a_ops->migratepage()方法的脏页不合适
上述这些特殊情况的LRU页面也不适合做内存迁移。