高性能队列--Disruptor
背景
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列。基于Disruptor开发的系统单线程可以支撑每秒600万的订单。
那么,这种高性能的内存队列是如何实现的呢?
JAVA内置的队列
目前java内置的队列有以下几种

为了在并发场景下保证线程的安全,上面的内置队列都使用了CAS或者锁的技术,那么使用CAS或者锁会对性能造成多大的影响呢?
Disruptor论文中讲述了一个实验:
这个测试程序调用了一个函数,该函数会对一个64位的计数器循环自增5亿次。
机器环境:2.4G 6核
运算: 64位的计数器累加5亿次
|Method | Time (ms) | |— | —| |Single thread | 300| |
Single thread with CAS | 5,700| |
Single thread with lock | 10,000| |
Single thread with volatile write | 4,700| |
Two threads with CAS | 30,000| |
Two threads with lock | 224,000|
结论:
加锁:比单线程无锁慢3个数量级
CAS:比单线程无锁慢1个数量级
单线程情况下,不加锁的性能 > CAS操作的性能 > 加锁的性能
理论上在高度竞争环境中,锁的性能会大于CAS的性能,但是在真实业务中,并没有那么多激烈的高度竞争场景(几十上百个线程争夺一个锁),所以尽量选择不加锁或者使用CAS来提高系统性能
CPU与缓存
下面是CPU与缓存的示意图,查询效率比较:L1>L2>L3>主存

下面是CPU访问通过不同层级缓存数据的时间概念

越靠近CPU的缓存,查询效率越高。效率是高了,但是如果缓存持有的数据是过期无效数据,那查询效率再高也没用。
缓存行概念
cache是由多个cache line组成的,每个cache line 通常是64个字节,并且它有效地引用内存中的一块地址。cpu每次从主存中拉取数据时,都会将相邻的数据一块放入cache line。
下面是一个测试用例,证明使用cache line的特性和不使用cache line特性的对比
public class CacheLineEffect {
//考虑一般缓存行大小是64字节,一个 long 类型占8字节
static long[][] arr;
public static void main(String[] args) {
// 构造二维数组,并填充数据
arr = new long[1024 * 1024][];
for (int i = 0; i < 1024 * 1024; i++) {
// 这8个long数据在读取的时候会被一次性加载到缓存行中
arr[i] = new long[8];
for (int j = 0; j < 8; j++) {
arr[i][j] = 0L;
}
}
long sum = 0L;
long marked = System.currentTimeMillis();
for (int i = 0; i < 1024 * 1024; i+=1) {
// 拿到第一个arr[i][0]的时候已经把后面arr[i][1]-arr[i][7]的7个long数据一起加载进缓存行了,这样接下来就不用再加载了
for(int j =0; j< 8;j++){
sum = arr[i][j];
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
marked = System.currentTimeMillis();
for (int i = 0; i < 8; i+=1) {
// 拿到第一个arr[j][0],就已经把后面的arr[j][1]-arr[j][7]的数据全部拿出来了,但是接下来cpu不使用这些数据,使用的是arr[j+1][0]数据,还得重新拿,浪费时间
for(int j =0; j< 1024 * 1024;j++){
sum = arr[j][i];
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
}
}
伪共享概念
上面代码示例中没有使用到cache line的情形就是伪共享的概念。这种无法充分使用缓存行特性的现象,就叫伪共享。
比如:两个cpu都加载同一个对象到自己的缓存行中,当一个cpu修改对象中的属性,另一个cpu加载到缓存行中的对象数据就失效,还得重新加载一遍对象数据,从而达不到内存共享的效果。
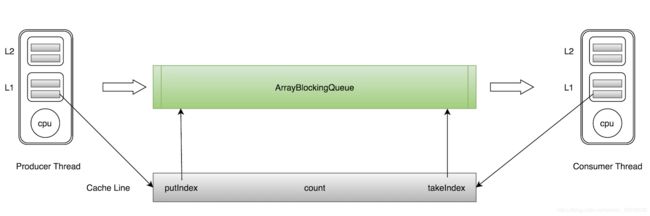
解决思路:增大数组元素间隔,使不同的线程加载到缓存行中的数据互不干扰,以空间换时间。避免线程操作当前缓存行中的数据,造成其它线程中的缓存行的数据失效。
public class FalseSharing implements Runnable{
public final static long ITERATIONS = 500L * 1000L * 100L;
private int arrayIndex = 0;
private static ValuePadding[] paddingObjArr;
public FalseSharing(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
for(int i=1;i<10;i++){
System.gc();
final long start = System.currentTimeMillis();
// 不同数量的线程并发执行,测试效果如何
runTest(i);
System.out.println("Thread num "+i+" duration = " + (System.currentTimeMillis() - start));
}
}
private static void runTest(int NUM_THREADS) throws InterruptedException {
// 创建存储N个paddingObj的数组
paddingObjArr = new ValuePadding[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; i++) {
paddingObjArr[i] = new ValuePadding();
}
// 创建N个线程
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; i++) {
// 每个线程拿到各自的下标
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
// 各自的线程处理各自数组下标下的对象的属性值
// 如果使用ValuePadding,因为线程之间加载的对象不在一个cache line中,导致线程修改自己对象的值,不会使其它线程的cache line失效,相互之间不会有影响
paddingObjArr[arrayIndex].value = 0L;
}
}
public final static class ValuePadding {
// 前面填充7个long,后面填充7个long,保证两个对象肯定加载不到同一个cache line中
protected long p1, p2, p3, p4, p5, p6, p7;
protected volatile long value = 0L;
protected long p9, p10, p11, p12, p13, p14;
protected long p15;
}
public final static class ValueNoPadding {
// protected long p1, p2, p3, p4, p5, p6, p7;
protected volatile long value = 0L;
// protected long p9, p10, p11, p12, p13, p14, p15;
}
}
使用ValuePadding测试结果如下:

使用ValueNoPadding测试结果如下:

总之一句话就是,你别的线程修改数据可以,但是不要影响到我这个线程使用的cache line的有效性,让我这个线程的cache line失效,我还得重新去主内存查找,这性能就慢了。
Disruptor核心RingBuffer
下面是单线程生产者,单线程消费者的代码demo
import com.lmax.disruptor.*;
import com.lmax.disruptor.dsl.ProducerType;
import java.util.concurrent.Executors;
public class DisruptorMain {
public static class MyEvent{
private int value;
public int get() {
return value;
}
public void set(int value) {
this.value = value;
}
}
public static void main(String[] args) throws Exception {
// 创建一个RingBuffer环形队列
RingBuffer<MyEvent> ringBuffer = RingBuffer.create(ProducerType.SINGLE, new EventFactory<MyEvent>() {
@Override
public MyEvent newInstance() {
return new MyEvent();
}
},16,new BlockingWaitStrategy());
// 单线程消费者逻辑
SequenceBarrier sequenceBarrier = ringBuffer.newBarrier();
// 创建processor
BatchEventProcessor batchEventProcessor = new BatchEventProcessor<MyEvent>(ringBuffer, sequenceBarrier, new EventHandler<MyEvent>() {
@Override
public void onEvent(MyEvent myEvent, long l, boolean b) throws Exception {
System.out.println(myEvent.get());
}
});
// 给ringBuffer添加上batchEventProcessor的序列号,用于判断最后消费的是哪个序列号,以便生产者插入新消息时知道下一个位置可不可以写入覆盖
ringBuffer.addGatingSequences(batchEventProcessor.getSequence());
Executors.newFixedThreadPool(1).submit(batchEventProcessor);
// 单线程消费者逻辑完成
// 单线程生产者逻辑
for (int num = 0; ; num++) {
long sequence = ringBuffer.next();
try {
ringBuffer.get(sequence).set(num);
} finally {
ringBuffer.publish(sequence);
}
Thread.sleep(200);
}
// 单线程生产者逻辑结束
}
}
下面是单线程生产者(多线程与单线程生产者的代码都是自己实现的,随意写),多线程消费者的代码逻辑
import com.lmax.disruptor.*;
import com.lmax.disruptor.dsl.ProducerType;
import java.util.concurrent.Executors;
public class DisruptorMain {
public static class MyEvent{
private int value;
public int get() {
return value;
}
public void set(int value) {
this.value = value;
}
}
public static void main(String[] args) throws Exception {
// 创建一个RingBuffer环形队列
RingBuffer<MyEvent> ringBuffer = RingBuffer.create(ProducerType.SINGLE, new EventFactory<MyEvent>() {
@Override
public MyEvent newInstance() {
return new MyEvent();
}
},16,new BlockingWaitStrategy());
// 单线程消费者逻辑
SequenceBarrier sequenceBarrier = ringBuffer.newBarrier();
// 创建一组消费者
WorkHandler[] workHandlers = new WorkHandler[10];
for(int i=0;i<workHandlers.length;i++){
workHandlers[i] = new WorkHandler<MyEvent>() {
@Override
public void onEvent(MyEvent myEvent) throws Exception {
System.out.println("Thread:"+Thread.currentThread().getId()+",Value: "+myEvent.get());
}
};
}
// 创建消费者工作池
WorkerPool<MyEvent> workerPool = new WorkerPool<MyEvent>(
ringBuffer,
sequenceBarrier,
new ExceptionHandler<MyEvent>() {
@Override
public void handleEventException(Throwable throwable, long l, MyEvent myEvent) {
}
@Override
public void handleOnStartException(Throwable throwable) {
}
@Override
public void handleOnShutdownException(Throwable throwable) {
}
},
workHandlers);
// 给ringBuffer添加上batchEventProcessor的序列号,用于判断最后消费的是哪个序列号,以便生产者插入新消息时知道下一个位置可不可以写入覆盖
ringBuffer.addGatingSequences(workerPool.getWorkerSequences());
// 使用线程池启动workPool
workerPool.start(Executors.newFixedThreadPool(workHandlers.length));
// 多线程消费逻辑完成
// 单线程生产者逻辑
for (int num = 0; ; num++) {
long sequence = ringBuffer.next();
try {
ringBuffer.get(sequence).set(num);
} finally {
ringBuffer.publish(sequence);
}
Thread.sleep(200);
}
// 单线程生产者逻辑结束
}
}
我们在工厂中经常看到工人在流水线上高效的作业,每个工人(CPU)都不会闲着,产品生产速度达到最大化。
同样的原理可以适用于软件,在RingBuffer这条流水线上,我们同样可以安排N多个工人进行高效作业,保证产品生产速度最大化。一套完善的任务分解方案(力度够细,且相互不影响)非常重要,可以保证各个CPU的高效协同作业,保证运行速度的最大化
当前的RingBuffer是单机性能优化到极致,同样的原理也可以应用于集群分布式场景,例如流处理等
import com.lmax.disruptor.*;
import com.lmax.disruptor.dsl.ProducerType;
import java.util.concurrent.Executors;
public class DisruptorMain {
public static class MyEvent{
private String value;
public String get() {
return value;
}
public void set(String value) {
this.value = value;
}
}
public static void main(String[] args) throws Exception {
// 创建一个RingBuffer环形队列
RingBuffer<MyEvent> ringBuffer = RingBuffer.create(ProducerType.SINGLE, new EventFactory<MyEvent>() {
@Override
public MyEvent newInstance() {
return new MyEvent();
}
},16,new BlockingWaitStrategy());
// stage 1
BatchEventProcessor batchEventProcessor = new BatchEventProcessor<MyEvent>(ringBuffer,
ringBuffer.newBarrier(),
new EventHandler<MyEvent>() {
@Override
public void onEvent(MyEvent myEvent, long l, boolean b) throws Exception {
myEvent.set("age:"+myEvent.get());
System.out.println("我需要将这个值追加一个前缀:age,"+myEvent.get());
}
});
// 给ringBuffer添加上batchEventProcessor的序列号,用于判断最后消费的是哪个序列号,以便生产者插入新消息时知道下一个位置可不可以写入覆盖
ringBuffer.addGatingSequences(batchEventProcessor.getSequence());
// stage 2
// 创建一组消费者
WorkHandler[] workHandlers = new WorkHandler[10];
for(int i=0;i<workHandlers.length;i++){
workHandlers[i] = new WorkHandler<MyEvent>() {
@Override
public void onEvent(MyEvent myEvent) throws Exception {
System.out.println("Thread:"+Thread.currentThread().getId()+",我只是将这个字符串打印出来,StringValue: "+myEvent.get());
}
};
}
// 创建消费者工作池
WorkerPool<MyEvent> workerPool = new WorkerPool<MyEvent>(
ringBuffer,
ringBuffer.newBarrier(batchEventProcessor.getSequence()),
new ExceptionHandler<MyEvent>() {
@Override
public void handleEventException(Throwable throwable, long l, MyEvent myEvent) {
}
@Override
public void handleOnStartException(Throwable throwable) {
}
@Override
public void handleOnShutdownException(Throwable throwable) {
}
},
workHandlers);
// 给ringBuffer添加上batchEventProcessor的序列号,用于判断最后消费的是哪个序列号,以便生产者插入新消息时知道下一个位置可不可以写入覆盖
ringBuffer.addGatingSequences(workerPool.getWorkerSequences());
// 启动processor
Executors.newFixedThreadPool(1).submit(batchEventProcessor);
// 使用线程池启动workPool
workerPool.start(Executors.newFixedThreadPool(workHandlers.length));
// 多线程消费逻辑完成
// 单线程生产者逻辑
for (int num = 0; ; num++) {
long sequence = ringBuffer.next();
try {
ringBuffer.get(sequence).set(num+"");
} finally {
ringBuffer.publish(sequence);
}
Thread.sleep(200);
}
// 单线程生产者逻辑结束
}
}
从以上的代码示例中,我们可以得到这么一个结论:我们可以在RingBuffer中对Event进行先行处理,使用屏障来保证各处理任务之间的执行顺序,以达到高并发的性能效果
等待策略
//BlockingWaitStrategy 是最低效的策略,但其对CPU的消耗最小并且在各种不同部署环境中能提供更加一致的性能表现
WaitStrategy BLOCKING_WAIT = new BlockingWaitStrategy();
//SleepingWaitStrategy 的性能表现跟BlockingWaitStrategy差不多,对CPU的消耗也类似,但其对生产者线程的影响最小,适合用于异步日志类似的场景
WaitStrategy SLEEPING_WAIT = new SleepingWaitStrategy();
//YieldingWaitStrategy 的性能是最好的,适合用于低延迟的系统。在要求极高性能且事件处理线数小于CPU逻辑核心数的场景中,推荐使用此策略;例如,CPU开启超线程的特性
WaitStrategy YIELDING_WAIT = new YieldingWaitStrategy();
Disruptor用例
RingBuffer是Disruptor的核心,下面是Disruptor的一个demo示例
/** 每1秒钟向Disruptor插入一个数据,消费者读取数据并打印(单线程) **/
import com.lmax.disruptor.*;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType;
import java.util.concurrent.ThreadFactory;
public class DisruptorMain {
public static class MyEvent{
private int value;
public int get() {
return value;
}
public void set(int value) {
this.value = value;
}
}
public static void main(String[] args) throws Exception {
// 生产者的线程工厂
ThreadFactory threadFactory = new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "simpleThread");
}
};
// RingBuffer生产工厂,初始化RingBuffer的时候使用
EventFactory<MyEvent> eventFactory = new EventFactory<MyEvent>() {
@Override
public MyEvent newInstance() {
return new MyEvent();
}
};
// 处理Event的handler
EventHandler<MyEvent> eventHandler = new EventHandler<MyEvent>() {
@Override
public void onEvent(MyEvent event, long sequence, boolean endOfBatch) {
System.out.println("Element: " + event.get());
}
};
// 创建disruptor,采用单生产者模式
Disruptor<MyEvent> disruptor = new Disruptor(eventFactory, 256, threadFactory, ProducerType.SINGLE, new BlockingWaitStrategy());
// 设置EventHandler
disruptor.handleEventsWith(eventHandler);
// 启动disruptor的线程
disruptor.start();
RingBuffer<MyEvent> ringBuffer = disruptor.getRingBuffer();
// 单线程插入数据
for (int num = 0; ; num++) {
long sequence = ringBuffer.next();
try {
ringBuffer.get(sequence).set(num);
} finally {
ringBuffer.publish(sequence);
}
Thread.sleep(1000);
}
}
}
参考文档:
https://tech.meituan.com/2016/11/18/disruptor.html