【Python】正则表达式及re模块
活动地址:CSDN21天学习挑战赛
**
学习日记 Day1
**
正则表达式被用来处理字符串,用来检查一个字符串是否与定义的字符序列的某种模式匹配。
1. 正则表达式语法
如下是正则表达式模式语法中的特殊元素。(re表示自己写的某一个具体匹配模式)
| 模式 | 描述 |
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的结尾 |
| . | 匹配除 "\n" 之外的任何单个字符。"[.\n]"可以匹配包括 “\n"在内的任何字符 |
| [...] | 表示一组字符,单独列出;如[amk]匹配 'a'、'm'或'k' |
| [^...] | 匹配不在[]中的字符;如[^abc]表示匹配除了a,b,c之外的字符 |
| re* | 匹配0个或多个表达式 |
| re+ | 匹配1个或多个表达式 |
| re? | 匹配0个或1个片段,非贪婪方式 |
| re{n} | 匹配n个表达式;如 ”o{2}"可以匹配“food",不能匹配”Bob |
| re{n,} | 精确匹配n个表达式;如 "o{2}"不能匹配“Bob",可以匹配"fooooood"中的所有"o" |
| re{n,m} | 匹配n到m次正则表达式定义的片段,贪婪方式 |
| 'a | b' |
| (re) | 匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i、m、x,只影响括号中的区域 |
| (?-imx) | 正则表达式关闭i、m或x可选标志,只影响括号中的区域 |
| (?:re) | 类似(...),不表示一个组 |
| (?imx:re) | 在括号中使用i,m或x可选标志 |
| (?-imx:re) | 在括号中不使用i,m或x可选标志 |
| (?#...) | 注释 |
| (?=re) | 前向肯定界定符。如果所含正则表达式,以...表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?!re) | 前向否定界定符,与肯定界定符相反;当所含表达式不能再字符串当前位置匹配时成功。 |
| (?>re) | 匹配的独立模式,省去回溯 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Aa-z0-9_]' |
| \W | 匹配任何非单词字符,等价于'[^A-Za-z0-9_]' |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等,等价于 '[\f\n\r\t\v]' |
| \S | 匹配任何非空白字符,等价于 '[^\f\n\r\t\v]' |
| \d | 匹配任意数字,等价于'[0-9]' |
| \D | 匹配一个非数字字符,等价于 '[^0-9]' |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果存在换行,只匹配到换行前的结束字符串 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置 |
| \b | 匹配一个单词边界,即指单词和空格间的位置。例如, 'er\b' 可以匹配 ‘never’中的'er',但不能匹配 'verb'中的'er' |
| \B | 匹配非单词边界,例如, 'er\b' 不能匹配 ‘never’中的'er',可以匹配 'verb'中的'er' |
| \n、\t等 | 匹配一个换行符,匹配一个制表符等 |
| \1...\9 | 匹配第n个分组的内容 |
| \10 | 匹配第n个分组的内容,如果它已经匹配,则指的是八进制字符码的表达式 |
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位OR(|)指定。如re.I | re.M表示被设置成I和M标志。
| 修饰符 | 描述 |
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别匹配 |
| re.M | 多行匹配,影响^ $ |
| re.S | 使 . 匹配包括换黄在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响\w,\W,\b,\B |
| re.X | 该标志通过给予更灵活的格式使正则表达式写得更易于理解 |
正则表达式从左到右计算,并遵循优先级顺序,与算数算术表达式类似。
正则表达式运算符的优先级顺序如下:
| 运算符 | 描述 |
| \ | 转义符 |
| (),(?;),(?=),[] | 圆括号和方括号 |
| *,+,?,{n},{n,},{n,m} | 限定符 |
| ^,$,\任何元字符、任何字符 | 定位点和序列,即位置和顺序 |
2. python中的正则表达式re模块
python中通过正则表达式对字符串进行匹配时,需要导入re模块,调用模块中的函数进行匹配操作。
2.1 re.match()匹配起始位置
首先需要导入re模块,然后使用re.match()进行匹配操作。最后提取数据。如下:
# 1. 导入python的正则表达式模块:re
import re
# 2. 使用match()方法进行匹配
result = re.match(正则表达式,要匹配的字符串)
# 3. 如果匹配到数据,使用group()提取数据
result.group() 简单使用示例:
import re
result = re.match("pyth","python")
print(result.group()) # 输出 pyth
result = re.match("thon","python")
if result is None:
print("模式没有找到匹配的字符串") # 输出 模式没有找到匹配的字符串
else:
print(result.group())re.match()函数尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回None。
re.match(pattern,string,flags=0)- 参数pattern表示匹配的正则表达式;
- 参数string表示要匹配的字符串;
- 参数flags表示标志位,用于控制正则表达式的匹配方式(re.I、re.M等),如:是否区分大小写,多行匹配等。
re.match()函数匹配成功后,返回一个match object对象,match object对象有以下方法:
- group():返回被re匹配的字符串
- start():返回匹配开始的位置
- end():返回匹配结束的位置
- span():返回一个元组包含匹配的位置
使用示例1,来源:正则查找网址_牛客题霸_牛客网 (nowcoder.com)
牛牛最近正在研究网址,他发现好像很多网址的开头都是'https://www',他想知道任意一个网址都是这样开头吗。于是牛牛向你输入一个网址(字符串形式),你能使用正则函数re.match在起始位置帮他匹配一下有多少位是相同的吗?(区分大小写)
输入描述:
输入一行字符串表示网址。
输出描述:
输出网址从开头匹配到第一位不匹配的范围。
代码:
import re
str = input()
result = re.match(r'https://www',str)
if result is None:
pass
else:
print(result.span())使用示例2,来源:截断电话号码_牛客题霸_牛客网 (nowcoder.com)
描述
牛牛记录电话号码时,习惯间隔几位就加一个-间隔,方便记忆,同时他还会在电话后面接多条#引导的注释信息。拨打电话时,-可以被手机正常识别,#引导的注释信息就必须要去掉了,你能使用正则匹配re.match将前面的数字及-信息提取出来吗,去掉后面的注释信息。
输入描述:
输入一行字符串,包括数字、大小写字母、#、-及空格。
输出描述:
输出提取的仅包含数字和-的电话号码。
示例:
输入:123-3456-789 #NiuMei #1 cool girl
输出:123-3456-789
代码,[\d-]表示匹配 数字或 -。
import re
str = input()
pattern = r'[\d-]*'
result = re.match(pattern,str)
if result:
print(result.group())2.2. re.search()匹配整个字符串
re.search()扫描整个字符串并返回第一个成功的匹配;匹配成功返回一个匹配的对象,否则返回None。
re.search(pattern,string,flags=0)- 参数pattern:匹配的正则表达式
- 参数string:要匹配的字符串
- 参数flags:标志位,用于控制正则表达式的匹配方式,比如是否区分大小写,多行匹配等
与re.match()相比,re.search()匹配整个字符串,直到找到一个匹配;re.match()只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None。二者区别示例如下:
# re.match() 与 re.search()的区别
s = "Tell me about it!"
ret_match = re.match("about",s,re.I)
ret_search = re.search("about",s,re.I)
if ret_match:
print("re.match()匹配:",ret_match.group())
else:
print("re.match()不匹配")
if ret_search:
print("re.search()匹配:",ret_search.group())
else:
print("re.search()不匹配")2.3. re.findall()匹配所有
re.findall()在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
re.findall()返回的是列表类型,不能使用group()函数获取到匹配的内容。
re.findall(pattern, string, flags=0)- 参数pattern:匹配的正则表达式
- 参数string:要匹配的字符串
- 参数flags:标志位,用于控制正则表达式的匹配方式,如是否区分大小写、多行匹配等。
与re.match()、re.search()相比,re.findall()匹配所有,前两个函数匹配一次。
s = "jack= 23,mark = 24,mary =25"
reg = "\d+"
ret = re.match(reg,s,re.I)
print("re.match()",end=" ")
if ret:
print(f"MATCH: {ret.group()}")
else:
print("NOT MATCH!!!")
ret = re.search(reg,s,re.I)
print("re.search()",end=" ")
if ret:
print(f"MATCH: {ret.group()}")
else:
print("NOT MATCH!!!")
ret = re.findall(reg,s,re.I)
print("re.findall()",end=" ")
if ret:
print(f"MATCH: {ret}")
else:
print("NOT MATCH!!!")显示结果:
re.match() NOT MATCH!!!
re.search() MATCH: 23
re.findall() MATCH: ['23', '24', '25']
如果有多个匹配模式,返回元组列表
s = "jack= 23,mark = 24,mary =25"
reg = r"(\w+)\s?=\s?(\d+)"
ret = re.findall(reg,s,re.I)
if ret:
print(f"MATCH: {ret}") # 匹配,输出MATCH: [('jack', '23'), ('mark', '24'), ('mary', '25')]
else:
print("NOT MATCH!!!")2.4 re.sub()匹配并替换
re.sub()将匹配到的数据进行替换。返回替换后的字符串
re.sub(pattern,repl,string,count=0,flags=0)- 参数pattern:正则中的模式字符串
- 参数repl:替换的字符串,也可为一个函数
- 参数string:要被查找替换的原始字符串
- 参数count:模式匹配后替换的最大次数,默认0表示替换所有的匹配
- 参数flags:编译时用的匹配模式,如是否区分大小写,多行匹配等
使用示例:
# re.sub() 使用
s = "0700-123456 # 带区号的电话号码"
reg = r"#.*$"
ret = re.sub(reg,"",s,count=0,flags=re.I)
if ret:
print(f"MATCH: {ret}")
else:
print("NOT MATCH!!!")
reg = r'\D' # 移除非数字的部分
ret = re.sub(reg,"",s,count=0,flags=re.I)
if ret:
print(f"MATCH: {ret}")
else:
print("NOT MATCH!!!")
def double(matched):
'''
将匹配的数字乘以2
return : 返回匹配到的数字*2
'''
value = int(matched.group("name"))
return str(value*2)
s = "A23D34F56G67"
reg = "(?P\d+)"
ret = re.sub(reg,double,s,count=0)
if ret:
print(f"MATCH: {ret}")
else:
print("NOT MATCH!!!") 显示结果:
MATCH: 0700-123456
MATCH: 0700123456
MATCH: A46D68F112G134
示例,来源:提取数字电话_牛客题霸_牛客网 (nowcoder.com)
描述
牛牛翻看以前记录朋友信息的电话薄,电话号码几位数字之间使用-间隔,后面还接了一下不太清楚什么意思的英文字母,你能使用正则匹配re.sub将除了数字以外的其他字符去掉,提取一个全数字电话号码吗?
输入描述:
输入一行字符串,字符包括数字、大小写字母和-
输出描述:
输出该字符串提取后的全数字信息。
示例1
输入:
2022-063-109NiuMei 输出: 2022063109
代码:
import re
str = input()
pattern = '[A-Za-z-]*' # 匹配大小写字母和横线-
result = re.sub(pattern=pattern,repl='',string=str)
if result:
print(result)2.5 re.split()匹配并切割
re.split()函数根据匹配进行切割字符串,并返回一个列表;如果找不到匹配的字符串,re.split()不会对其分割。
re.split()返回的是一个列表,不能使用group()获取匹配的内容。
re.split(pattern,string,maxsplit=0,flags=0)- 参数pattern:匹配的正则表达式
- 参数string:要匹配的字符串
- 参数maxsplit:分割次数,maxsplit=1分割1次,默认为0,表示不限制次数
- 参数flags:标志位,用于控制正则表达式的匹配当时,如是否区分大小写,多行匹配等
s = "info: CSDN python Regular_regpression"
reg = r":| "
ret = re.split(reg,s,maxsplit=0)
if ret:
print(f"MATCH: {ret}")
print(type(ret))
else:
print("NOT MATCH!!!")
reg = "-"
ret = re.split(reg,s,maxsplit=0)
if ret:
print(f"MATCH: {ret}")
print(type(ret))
else:
print("NOT MATCH!!!")显示结果:
MATCH: ['info', '', 'CSDN', 'python', 'Regular_regpression']
MATCH: ['info: CSDN python Regular_regpression']
3. 正则表达式匹配介绍
3.1 匹配单个字符
匹配单个字符可以选择如下的模式:
- . 匹配任意1个字符,除了\n
- [] 匹配[]中列举的字符
- \d 匹配数字,即[0-9]
- \D 匹配非数字,即[^0-9]
- \s 匹配空白,即空格、tab键等
- \S 匹配非空白
- \w 匹配单词字符,即[A-Za-z0-9_]
- \W 匹配非单词字符,即[^A-Za-z0-9_]
示例:
# 匹配单个字符
ret = re.match(".","M") # .匹配
print(ret.group())
ret = re.match("t.o","too")
print(ret.group())
ret = re.match("[hH]","hello python") # []匹配
print(ret.group())
ret = re.match("python\d","python3.8") # \d匹配
print(ret.group())
ret = re.match("python\d\.\d","python3.8")
print(ret.group())
ret = re.match("python\D","pythonV3.8") # \D匹配
print(ret.group())
ret = re.match("python\sV","python V3.8") # \s匹配
print(ret.group())
ret = re.match("python\SV","python-V3.8") # \S匹配
print(ret.group())
ret = re.match("python\wV","python_V3.8") # \w匹配
print(ret.group())
ret = re.match("python\WV","python-V3.8") # \W匹配
print(ret.group())
ret = re.search("python\WV","Hi python-V3.8") # \W匹配
print(ret.group())3.2 匹配多个字符
匹配多个字符时需要使用到如下修饰符:
- * 匹配前一个字符出现0次或者无限次
- + 匹配前一个字符出现1次或者无限次
- ? 匹配前一个字符出现一次或者0次
- {m} 匹配前一个字符出现m次
- {m,n} 匹配前一个字符出现从m到n次,尽可能多的匹配
示例:
print('='*30)
print("匹配多个字符")
ret = re.match("Y*","YYYY-MM-DD") # *匹配0个或多个
print(ret.group())
ret = re.match("Y+","YYYY-MM-DD") # +匹配1个或多个
print(ret.group())
ret = re.match("Y?","YYYY-MM-DD") # ?匹配1个或0个
print(ret.group())
ret = re.match("M?","YYYY-MM-DD") # ?匹配1个或0个
print(ret.group())
ret = re.match("Y{3}","YYYY-MM-DD") # {m}匹配m个
print(ret.group())
ret = re.match("Y{3,4}","YYYY-MM-DD") # {m}匹配m个
print(ret.group())
ret = re.search("M?","YYYY-MM-DD") # ?匹配1个或0个
print("search()匹配:",ret.group())
ret = re.search("Y?","YYYY-MM-DD") # ?匹配1个或0个
print("search()匹配:",ret.group())
ret = re.search("M+","YYYY-MM-DD") # ?匹配1个或0个
print("search()匹配:",ret.group())
names = ['name','_name','2_name','__name__']
reg = "[a-zA-Z_]+\w*"
for name in names:
ret = re.match(reg,name)
if ret:
print(f"变量名 {name} 符合要求")
else:
print(f"变量名 {name} 不符合要求")
# 匹配数字
reg="[1-9]+\d*$"
vars = [123,32,98,"09","23","asd"]
for var in vars:
ret = re.match(reg,str(var))
print(f"变量 {var} ",end="")
if ret:
print(f"符合数字要求,{ret.group()}")
else:
print("不符合数字要求")
# 匹配0~99之间的数字
reg = "[1-9]?\d"
vars = ["09","0","9","90","10"]
for var in vars:
ret = re.match(reg,str(var))
print(f"变量 {var} ",end="")
if ret:
print(f"符合0~99之间 {ret.group()}")
else:
print("符合0~99之间")
# 匹配密码 密码可以是大小写字母、数字、下划线,至少8位,最多20位
reg = "\w{8,20}"
ret = re.match(reg,"_python3_8_0_vscode_1_pycharm")
print("密码是:",ret.group())3.3 匹配开头结尾
匹配开头、结尾使用如下修饰符:
- ^ 匹配字符串开头
- $ 匹配字符串结尾
示例:
# 匹配开头结尾
print("="*30)
print("匹配开头结尾")
# 匹配中国移动号码段
phones = [134,135,136,137,138,139,147,150,151,152, 157,158,159,172,178,182,183,184,187,188,198]
numbers= ['12345678901','13412345678','13678349867']
for num in numbers:
for phone in phones:
reg = "^" + str(phone) + "[0-9]{8}"
ret = re.match(reg,num)
if ret:
print(f"{num} 是中国移动号:{ret.group()}")
break
if ret is None:
print(f"{num} 不是中国移动号")
# 匹配邮箱
reg = "[\w]{4,20}@163.com$"
email_lst = ["[email protected]","[email protected]","[email protected]"]
for lst in email_lst:
ret = re.match(reg,lst)
if ret:
print(f"{lst} 是163邮箱:{ret.group()}")
else:
print(f"{lst} 不是163邮箱")显示结果:
==============================
匹配开头结尾
12345678901 不是中国移动号
13412345678 是中国移动号:13412345678
13678349867 是中国移动号:13678349867
[email protected] 是163邮箱:[email protected]
[email protected] 是163邮箱:[email protected]
[email protected] 不是163邮箱
3.4 匹配分组
匹配分组的修饰符如下:
- (ab) 将括号中字符作为一个分组
- \num 引用分组num匹配到的字符串
- (?P
- (?P=name) 引用别名为name分组匹配到的字符串
对于返回结果是对象的函数,()匹配到的结果可以使用group(index)获取到,可以使用groups(0获取到匹配的元组的个数;
模式中从左到右的第一个括号匹配到的内容即为group(1),以此类推;
\number匹配的是()中的内容,从左向右第一个左括号的内容是\1,第二个左括号的内容是\2...;
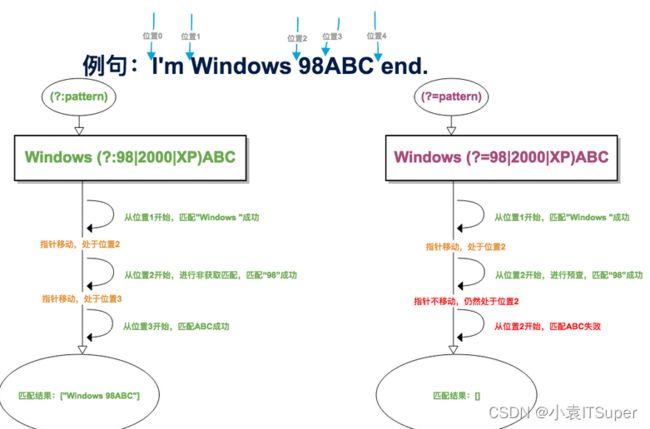
(?P 示例: 前面介绍过()是分组,()匹配的内容会被保存起来;从左到右,以分组的左括号位标志,第一个出现的分组的组号为1,第二个为2,以此类推。 (?:)表示不捕获分组,意味着匹配的内容不会被保存起来。 对比如下代码,可以看到(?:pattern)不获取匹配结果 显示结果 MATCH: ('123', 'asd', '456') 该语法是正向肯定预查,匹配pattern前面的位置,这是一个非获取匹配,即该匹配不需要获取供以后使用。 显示结果: MATCH: windows ※※※ (?:pattern)和(?=pattern)的区别: 改语法是正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,这是一个非获取匹配,该匹配不需要获取供以后使用。 示例: 显示结果: pattern:windows(?!95|7|10|11|xp) 从名字就可以看出,贪婪表示更多,那非贪婪就与贪婪相反,表示更少。 贪婪模式下正则表达式匹配时,在从左到右的顺序求值时,会尽可能的获取满足匹配的最长字符。非贪婪则尝试匹配尽可能少的字符。 python中数量词默认是贪婪的,会尝试匹配尽可能多的字符;在 *,?,+,{m,n}后面加上?会使贪婪变成非贪婪。 如下示例: 显示结果: \w+ MATCH blog.csdn.net: blog python中使用r表示模式中是原生字符串,如果不使用r,有的字符需要进行转义才能表达想要的模式。 如要匹配 “\\",如果使用r,那么模式可以为 r"\\";如果不使用r,那么模式是 "\\\\",第一个和第三个\表示转义字符。 全文参考链接:100天精通Python(进阶篇)——第34天:正则表达式大总结_无 羡ღ的博客-CSDN博客# |用法 匹配0~100之间的数字
reg = "[1-9]?\d$|100"
num_lst = ['12','123','09','9','0','100']
for num in num_lst:
ret = re.match(reg,num)
if ret:
print(f"{num} 是0~100之间的数字:{ret.group()}")
else:
print(f"{num} 不是0~100之间的数字")
# ()匹配
# 提取区号和电话号
reg = "([^-]*)-(\d+)"
phones = ['0730-123456','0700-23456','asd-23456']
for phone in phones:
ret = re.match(reg,phone)
if ret:
print(f"{phone}是正确的电话号码,区号是{ret.group(1)},电话号是{ret.group(2)}")
else:
print(f"{phone}不是正确的电话号码")
# 使用如下的模式不能识别正确的HTML标签
reg = "<[a-zA-Z]*>\w*"
html_lst = ["python","python"]
for lst in html_lst:
ret = re.match(reg,lst)
if ret:
print(f"{lst} 是正常的HTML标签:{ret.group()}")
else:
print(f"{lst} 不是正常的HTML标签")
# \用法
print("="*30)
print("\\用法")
reg = r"<([a-zA-Z]*)>\w*"
html_lst = ["python","python"]
for lst in html_lst:
ret = re.match(reg,lst)
if ret:
print(f"{lst} 是正常的HTML标签:{ret.group()}")
else:
print(f"{lst} 不是正常的HTML标签")
# \number用法
print("="*30)
print("\\number用法")
reg = r"<(\w*)><(\w*)>.*"
html_lst = ["python",
"python",
"python
",
"python"
]
for lst in html_lst:
ret = re.match(reg,lst)
if ret:
print(f"{lst} 是正常的HTML标签:{ret.group()}")
else:
print(f"{lst} 不是正常的HTML标签")
# (?P
python
",
"python",
"
csdn.com
",
"csdn.com",
"
www.itcast.cn
"
"www.itcast.cn"
]
for lst in html_lst:
ret = re.match(reg,lst)
if ret:
print(f"{lst} 是正常的HTML标签:{ret.group()}")
else:
print(f"{lst} 不是正常的HTML标签")
4. 特殊语法
4.1 特殊语法1:(?:pattern)
# (?:pattern) 不捕获分组
s = "123asd456"
reg = r"(\d*)([a-z]*)(\d*)"
ret = re.search(reg,s)
if ret:
print(f"MATCH: {ret.groups()}")
else:
print("NOT MATCH!!!")
reg = r"(?:\d*)([a-z]*)(\d*)"
ret = re.search(reg,s)
if ret:
print(f"MATCH: {ret.groups()}")
else:
print("NOT MATCH!!!")
MATCH: ('asd', '456')4.2 特殊语法2:(?=pattern)
# (?=pattern) 模式匹配
s=['windows7','windows10','windows11','windows2000','windows2010']
reg = r"windows(?=95|7|10|11|xp)"
for lst in s:
ret = re.search(reg,lst)
if ret:
print(f"MATCH: {ret.group()}")
else:
print("NOT MATCH!!!")
MATCH: windows
MATCH: windows
NOT MATCH!!!
NOT MATCH!!!
4.3 特殊语法3:(?!pattern)
s=['windows7','windows10','windows11','windows2000','windows2010']
reg = r"windows(?!95|7|10|11|xp)"
print(f"pattern:{reg}")
for lst in s:
ret = re.search(reg,lst)
if ret:
print(f"{lst} MATCH: {ret.group()}")
else:
print("NOT MATCH!!!")
NOT MATCH!!!
NOT MATCH!!!
NOT MATCH!!!
windows2000 MATCH: windows
windows2010 MATCH: windows5. 正则表达式中的贪婪和非贪婪
s = "blog.csdn.net"
reg = "\w+"
ret = re.match(reg,s)
if ret:
print(f"{reg} MATCH {s}: {ret.group()}")
else:
print("NOT MATCH!!!")
reg = "\w+?"
ret = re.match(reg,s)
if ret:
print(f"{reg} MATCH {s}: {ret.group()}")
else:
print("NOT MATCH!!!")
reg = "\w{2,5}"
ret = re.match(reg,s)
if ret:
print(f"{reg} MATCH {s}: {ret.group()}")
else:
print("NOT MATCH!!!")
reg = "\w{2,5}?"
ret = re.match(reg,s)
if ret:
print(f"{reg} MATCH {s}: {ret.group()}")
else:
print("NOT MATCH!!!")
\w+? MATCH blog.csdn.net: b
\w{2,5} MATCH blog.csdn.net: blog
\w{2,5}? MATCH blog.csdn.net: bl6. python中 r 的作用
 https://blog.csdn.net/yuan2019035055/article/details/124217883?app_version=5.7.0&csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22124217883%22%2C%22source%22%3A%22yuan2019035055%22%7D&ctrtid=dmICC&utm_source=app
https://blog.csdn.net/yuan2019035055/article/details/124217883?app_version=5.7.0&csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22124217883%22%2C%22source%22%3A%22yuan2019035055%22%7D&ctrtid=dmICC&utm_source=app