史上最全深度解析Flink内存管理--大数据技术
目前,大数据计算引擎主要使用Java或基于JVM的编程语言实现的,例如Apache Hadoop,Apache Spark,Apache
Drill,Apache Flink等。但同样会面临一个问题,就是如何在内存中存储大量的数据(包括缓存和高效处理)。
JVM内存管理的不足:
1)Java对象存储密度低。Java的对象在内存中存储包含3个主要部分:对象头,实例数据,拆分填充部分。例如,一个只包含boolean属性的对象占16byte:对象头占8byte,boolean属性占1字节,为了对齐达到8的倍数额外占7字节。而实际上只需要一个bit(1/8字节)就够了。
2)Full GC会极大地影响性能。尤其是为了处理大量数据而开了很大的内存空间的JVM来说,GC会达到秒级甚至分钟级。
3)OOM问题影响稳定性。OutOfMemoryError是分布式计算框架经常会遇到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会发生OutOfMemory Error错误,导致JVM崩溃,分散框架的健壮性和性能都会受到影响。
4)缓存未命中中问题。CPU进行计算的时候,是从CPU缓存中获取数据。这样就会大大降低CacheMiss。使得CPU集中处理业务,而不是空转。(Java的对象在堆上存储的时候并不是连续的,所以从内存中读取的Java对象时,缓存的邻近的内存区域的数据往往不是CPU后续计算所需要的,这就是缓存未命中。此时CPU需要空转等待从内存中重新读取数据。)
Flink并不是将大量对象存在堆内存上,或者将对象都序列化到一个预分配的内存块上,这个内存块称为MemorySegment,它代表了一段固定长度的内存(大小为32KB),也是Flink中最小的内存分配单元,并且提供了非常高效的读写方法,很多运算可以直接操作二进制数据,不需要反序列化即可执行中。
1. 内存模型

1.1 JobManager内存模型
在1.10中,Flink统一了TM端的内存管理和配置,相应的在1.11中,Flink进一步对JM端的内存配置进行了修改,使它的选项和配置方式与TM端的配置方式保持一致。
1.10版本
# The heap sizefor the JobManager JVM
jobmanager.heap.size:1024m
1.11版本及以后
# The totalprocess memory size for the JobManager.
#
# Note thisaccounts for all memory usage within the JobManager process, including JVMmetaspace and other overhead.
jobmanager.memory.process.size:1600m
1.2 TaskManager内存模型
Flink 1.10对TaskManager的内存模型和Flink应用程序的配置选项进行了重大更改,让用户能够更加严格地控制其内存消耗。

TaskExecutorFlinkMemory.java

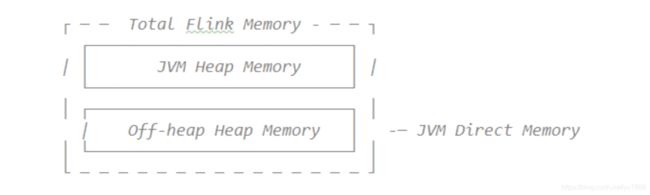
1.3 JVM堆:JVM堆上内存
(1)Framework HeapMemory:Flink框架本身使用的内存,即TaskManager本身所占用的堆上内存,不计入插槽的资源中。
配置参数:taskmanager.memory.framework.heap.size = 128MB,可用128MB
(2)任务堆内存:任务执行用户代码时所使用的堆上内存。
配置参数:taskmanager.memory.task.heap.size
1.4 堆外内存:JVM堆外内存
(1)DirectMemory:JVM直接内存
①FrameworkOff-Heap内存:Flink框架本身所使用的内存,即TaskManager本身所占用的外部内存,不计入Slot资源。
配置参数:taskmanager.memory.framework.off-heap.size = 128MB,设置128MB
②TaskOff-HeapMemory:任务执行用户代码所使用的外部内存。
配置参数:taskmanager.memory.task.off-heap.size = 0,设为0
③网络内存:网络数据交换所使用的堆外内存大小,如网络数据交换长度
配置参数:
taskmanager.memory.network.fraction:0.1
taskmanager.memory.network.min:64mb
taskmanager.memory.network.max:1gb
(2)托管内存:Flink管理的堆外部内存,用于排序,哈希表,缓存中间结果及RocksDB StateBackend的本地内存。
配置参数:
taskmanager.memory.managed.fraction = 0.4
taskmanager.memory.managed.size
1.5 JVM特定内存:JVM本身使用的内存
(1)JVM元空间:JVM元空间
(2)JVM开销执行开销:JVM执行时自身所需要的内容,包括线程线程,IO,编译缓存等所使用的内存。
配置参数:
taskmanager.memory.jvm-overhead.min = 192mb
taskmanager.memory.jvm-overhead.max = 1gb
taskmanager.memory.jvm-overhead.fraction = 0.1
1.6 总体内存
(1)总进程内存:Flink Java应用程序(包括用户代码)和JVM运行整个进程所消耗的总内存。
总进程内存= Flink使用内存+ JVM元空间+ JVM执行开销
配置项:taskmanager.memory.process.size:1728m
(2)Flink总内存:仅Flink Java应用程序消耗的内存,包括用户代码,但不包括JVM为此运行而分配的内存
1.7 Flink使用内存:框架堆内外+任务堆内外+网络+管理
配置项:taskmanager.memory.flink.size:1280m
配置项详细信息查看如下链接
1.8 内存分配
1.8.1 JobManager内存分配
YarnClusterDescriptor.java
private ApplicationReport startAppMaster(
Configuration configuration,
String applicationName,
String yarnClusterEntrypoint,
JobGraph jobGraph,
YarnClient yarnClient,
YarnClientApplication yarnApplication,
ClusterSpecification clusterSpecification) throws Exception {
... ...
final JobManagerProcessSpec processSpec = JobManagerProcessUtils.processSpecFromConfigWithNewOptionToInterpretLegacyHeap(
flinkConfiguration,
JobManagerOptions.TOTAL_PROCESS_MEMORY);
final ContainerLaunchContextamContainer = setupApplicationMasterContainer(
yarnClusterEntrypoint,
hasKrb5,
processSpec);
... ...
}
JobManagerProcessUtils.java
public static JobManagerProcessSpec processSpecFromConfigWithNewOptionToInterpretLegacyHeap(
Configuration config,
ConfigOption newOptionToInterpretLegacyHeap) {
try {
return processSpecFromConfig(
getConfigurationWithLegacyHeapSizeMappedToNewConfigOption(
config,
newOptionToInterpretLegacyHeap));
} catch (IllegalConfigurationExceptione) {
throw new IllegalConfigurationException("JobManager memory configuration failed:" + e.getMessage(), e);
}
}
static JobManagerProcessSpec processSpecFromConfig(Configurationconfig) {
return createMemoryProcessSpec(PROCESS_MEMORY_UTILS.memoryProcessSpecFromConfig(config));
}
ProcessMemoryUtils.java
public CommonProcessMemorySpec<FM> memoryProcessSpecFromConfig(Configurationconfig) {
if(options.getRequiredFineGrainedOptions().stream().allMatch(config::contains)) {
// all internal memory optionsare configured, use these to derive total Flink and process memory
return deriveProcessSpecWithExplicitInternalMemory(config);
} else if(config.contains(options.getTotalFlinkMemoryOption())) {
// internal memory options arenot configured, total Flink memory is configured,
// derive from total flinkmemory
// 如果只配置了JM的Flink总内存,调用下面方法
return deriveProcessSpecWithTotalFlinkMemory(config);
} else if(config.contains(options.getTotalProcessMemoryOption())) {
// total Flink memory is notconfigured, total process memory is configured,
// derive from total processmemory
return deriveProcessSpecWithTotalProcessMemory(config);
}
return failBecauseRequiredOptionsNotConfigured();
}
private CommonProcessMemorySpec<FM> deriveProcessSpecWithTotalFlinkMemory(Configurationconfig) {
MemorySize totalFlinkMemorySize = getMemorySizeFromConfig(config,options.getTotalFlinkMemoryOption());
// 获取JM的Flink总内存
FM flinkInternalMemory = flinkMemoryUtils.deriveFromTotalFlinkMemory(config,totalFlinkMemorySize);
// 获取JM的JVM元空间和执行开销
JvmMetaspaceAndOverhead jvmMetaspaceAndOverhead = deriveJvmMetaspaceAndOverheadFromTotalFlinkMemory(config,totalFlinkMemorySize);
return newCommonProcessMemorySpec<>(flinkInternalMemory, jvmMetaspaceAndOverhead);
}
JobManagerFlinkMemoryUtils.java
public JobManagerFlinkMemory deriveFromTotalFlinkMemory(Configurationconfig, MemorySize totalFlinkMemorySize) {
MemorySize offHeapMemorySize = ProcessMemoryUtils.getMemorySizeFromConfig(config,JobManagerOptions.OFF_HEAP_MEMORY);
if(totalFlinkMemorySize.compareTo(offHeapMemorySize) < 1) {
throw new IllegalConfigurationException(
"The configuredTotal Flink Memory (%s) is less than the configured Off-heap Memory(%s).",
totalFlinkMemorySize.toHumanReadableString(),
offHeapMemorySize.toHumanReadableString());
}
MemorySize derivedJvmHeapMemorySize =totalFlinkMemorySize.subtract(offHeapMemorySize);
return createJobManagerFlinkMemory(derivedJvmHeapMemorySize,offHeapMemorySize);
}
private static JobManagerFlinkMemory createJobManagerFlinkMemory(
MemorySize jvmHeap,
MemorySize offHeapMemory) {
verifyJvmHeapSize(jvmHeap);
return new JobManagerFlinkMemory(jvmHeap, offHeapMemory);
}
1.8.2 TaskManager内存分配
ActiveResourceManager.java
private void requestNewWorker(WorkerResourceSpecworkerResourceSpec) {
final TaskExecutorProcessSpectaskExecutorProcessSpec =
TaskExecutorProcessUtils.processSpecFromWorkerResourceSpec(flinkConfig,workerResourceSpec);
... ...
}
TaskExecutorProcessUtils.java
public static TaskExecutorProcessSpec processSpecFromWorkerResourceSpec(
final Configuration config, finalWorkerResourceSpec workerResourceSpec) {
final MemorySize frameworkHeapMemorySize =TaskExecutorFlinkMemoryUtils.getFrameworkHeapMemorySize(config);
final MemorySize frameworkOffHeapMemorySize = TaskExecutorFlinkMemoryUtils.getFrameworkOffHeapMemorySize(config);
final TaskExecutorFlinkMemory flinkMemory = new TaskExecutorFlinkMemory(
frameworkHeapMemorySize,
frameworkOffHeapMemorySize,
workerResourceSpec.getTaskHeapSize(),
workerResourceSpec.getTaskOffHeapSize(),
workerResourceSpec.getNetworkMemSize(),
workerResourceSpec.getManagedMemSize());
final JvmMetaspaceAndOverhead jvmMetaspaceAndOverhead =
PROCESS_MEMORY_UTILS.deriveJvmMetaspaceAndOverheadFromTotalFlinkMemory(
config,flinkMemory.getTotalFlinkMemorySize());
return newTaskExecutorProcessSpec(workerResourceSpec.getCpuCores(), flinkMemory, jvmMetaspaceAndOverhead);
}
2. 内存数据结构
2.1 内存段
内存段在Flink内部叫MemorySegment,是Flink中最小的内存分配单元,大小为32KB。它即可以是堆上内存(Java的字节分配),也可以是堆外内存(基于Netty的DirectByteBuffer),同时提供了对二进制数据进行读取和写入的方法。

HeapMemorySegment:用来分配堆上内存
HybridMemorySegment:使用了分配堆外部内存和堆上内存,2017年以后的版本实际上只使用了HybridMemorySegment。
如下图展示一个内嵌型的Tuple3

其中int占4个字节,double占8个字节,POJO多个一个字节的标头,PojoSerializer只负责将标头序列化进去,并委托每个细分对应的serializer对细分进行序列化。
2.2 内存页
内存页面是MemorySegment之上的数据访问视图,数据读取抽象为DataInputView,数据写入抽象为DataOutputView。使用时不需担心MemorySegment的细节,会自动处理跨MemorySegment的读取和写入。
2.3 缓冲
Task算子之间在网络上层传输数据,使用的是缓冲区,申请和释放由Flink自管,实现类为NetworkBuffer。1个NetworkBuffer包装了1个MemorySegment。
public class NetworkBuffer extends AbstractReferenceCountedByteBuf implements Buffer {
/** The backing {@link MemorySegment}instance. */
private final MemorySegment memorySegment;
... ...
}
2.4 缓冲资源池
BufferPool用于管理Buffer,包含Buffer的申请,释放,销毁,可用Buffer通知等,实现类是LocalBufferPool,每个任务拥有自己的LocalBufferPool。
BufferPoolFactory用于提供BufferPool的创建和销毁,唯一的实现类是NetworkBufferPool,每个TaskManager只有一个NetworkBufferPool。同一个TaskManager的任务共享NetworkBufferPool,在TaskManager启动的时候创建并分配内存。
3. 内存管理器
MemoryManager用于管理Flink中用于排序,哈希表,中间结果的缓存或使用堆外部内存的状态替换(RocksDB)的内存。
1.10之前的版本,负责TaskManager所有内存。
1.10版本开始,管理范围是插槽等级。
3.1 堆外内存资源申请:
MemoryManager.java
public void allocatePages(
Object owner,
Collection<MemorySegment> target,
int numberOfPages)throws MemoryAllocationException {
... ...
allocatedSegments.compute(owner,(o, currentSegmentsForOwner) -> {
Set<MemorySegment> segmentsForOwner = currentSegmentsForOwner == null ?
new HashSet<>(numberOfPages) : currentSegmentsForOwner;
for (long i =numberOfPages; i > 0; i--) {
MemorySegment segment = allocateOffHeapUnsafeMemory(getPageSize(),owner, pageCleanup);
target.add(segment);
segmentsForOwner.add(segment);
}
return segmentsForOwner;
});
}
... ...
MemorySegmentFactory.java
public static MemorySegment allocateOffHeapUnsafeMemory(int size, Objectowner, Runnable customCleanupAction) {
long address =MemoryUtils.allocateUnsafe(size);
ByteBuffer offHeapBuffer = MemoryUtils.wrapUnsafeMemoryWithByteBuffer(address, size);
MemoryUtils.createMemoryGcCleaner(offHeapBuffer,address, customCleanupAction);
return new HybridMemorySegment(offHeapBuffer, owner);
}
3.2 RocksDB自己负责内存申请和释放
RocksDBOperationUtils.java
public static OpaqueMemoryResource<RocksDBSharedResources> allocateSharedCachesIfConfigured(
RocksDBMemoryConfiguration memoryConfig,
MemoryManager memoryManager,
double memoryFraction,
Logger logger) throws IOException {
... ...
try {
if(memoryConfig.isUsingFixedMemoryPerSlot()) {
assertmemoryConfig.getFixedMemoryPerSlot() != null;
logger.info("Gettingfixed-size shared cache for RocksDB.");
return memoryManager.getExternalSharedMemoryResource(
FIXED_SLOT_MEMORY_RESOURCE_ID,allocator, memoryConfig.getFixedMemoryPerSlot().getBytes());
}
else {
logger.info("Gettingmanaged memory shared cache for RocksDB.");
return memoryManager.getSharedMemoryResourceForManagedMemory(MANAGED_MEMORY_RESOURCE_ID,allocator, memoryFraction);
}
}
... ...
}
MemoryManager.java
public <Textends AutoCloseable> OpaqueMemoryResource<T> getExternalSharedMemoryResource(
String type,
LongFunctionWithException<T,Exception> initializer,
long numBytes) throws Exception {
// This object identifies the lease inthis request. It is used only to identify the release operation.
// Using the object to represent thelease is a bit nicer safer than just using a reference counter.
final Object leaseHolder = new Object();
final SharedResources.ResourceAndSize<T>resource =
sharedResources.getOrAllocateSharedResource(type,leaseHolder, initializer, numBytes);
// 创建资源释放函数
final ThrowingRunnable<Exception> disposer = () -> sharedResources.release(type,leaseHolder);
return new OpaqueMemoryResource<>(resource.resourceHandle(),resource.size(), disposer);
}
4. 网络传输中的内存管理

网络上传输的数据会写到Task的InputGate(IG)中,通过Task的处理后,再由Task写到ResultPartition(RS)中。每个Task都包括了输入和输入,输入和输出的数据存在Buffer中(都是字节数据)。Buffer是MemorySegment的包装类。
1)TaskManager(TM)在启动时,会先初始化NetworkEnvironment对象,TM中所有与网络相关的东西都由该类来管理(如Netty连接),其中就包括NetworkBufferPool。根据配置,Flink会在NetworkBufferPool中生成一定数量(大小2048)的内存块MemorySegment(关于Flink的内存管理,后续文章会详细介绍),内存块的总数量就代表了网络传输中所有可用的内存。NetworkEnvironment和NetworkBufferPool是任务之间共享的,每个TM只会实例化一个。
2)任务线程启动时,会向NetworkEnvironment注册,NetworkEnvironment会为任务的InputGate(IG)和ResultPartition(RP)分别创建一个LocalBufferPool(缓冲池)并设置可申请的MemorySegment(内存块)数量。池初始的内存块数量与IG中InputChannel数量一致,RP对应的缓冲池初始的内存块数量与RP中的ResultSubpartition数量一致。不过,每当创建或销毁缓冲池时,NetworkBufferPool会计算剩余的内存块数量数量,并平均分配给已创建的缓冲池。注意,这个过程只是指定了缓冲池所能使用的内存块数量,并没有真正分配内存块,只有当需要时才分配。为什么要动态地为缓冲池扩容呢?因为内存越多,意味着系统可以更轻松地应对瞬态压力(如GC),不会交替地进入反压状态,所以我们要利用起那部分闲置的内存块。
3)在任务线程执行过程中,当Netty接收端收到数据时,为了将Netty中的数据复制到Task中,InputChannel(实际是RemoteInputChannel)会向其对应的缓冲池申请内存块(上图的) ①)。如果缓冲池中也没有可用的内存块且已申请的数量还没到池子上限,则向NetworkBufferPool申请内存块(上图的②)并提交InputChannel填上数据(上图的) ③和④)。如果缓冲池已申请的数量达到上限了呢?或者NetworkBufferPool也没有可用的内存块了呢?这时候,任务的NettyChannel会暂停重新传输,上游的发送端会立即响应停止发送,拓扑会进入反压状态。当任务线程写入数据到ResultPartition时,也会向缓冲池请求内存块,如果没有可用的内存块时,会在请求缓存块的地方,达到暂停写入的目的。
4)当一个内存块被消费完成之后(在输入端是指内存块中的字节被反序列化成对象了,在输出端是指内存块中的字节写入到Netty Channel了),会调用如果LocalBufferPool中当前申请的数量超过了池子容量(由于上面提到的动态容量,由于新注册的任务导致该池子容量变小),则LocalBufferPool会初始化内存块回收给NetworkBufferPool(上图的⑥)。如果没超过池子容量,逐渐继续留在池子中,减少重复申请的费用。
4.1 反压的过程

1)记录“ A”进入了Flink并且被任务1处理。(这里省略了Netty接收,反序列化等过程)
2)记录被序列化到buffer中。
3)该缓冲区被发送到任务2,然后任务2从这个缓冲区中读取记录。
记录能被Flink处理的预期是:必须有适当可用的Buffer。
结合上面两张图看:任务1在输出端有一个相关联的LocalBufferPool(称缓冲池1),任务2在输入端也有一个相关联的LocalBufferPool(称缓冲池2)。可用的缓冲区来序列化记录“ A”,我们就序列化并发送该缓冲区。
4.2 注意两个场景:
1)本地传输:如果Task1和Task 2运行在同一个工作者的程序(TaskManager)上,该缓冲区可以直接发送到下一个Task。再次Task 2消费了该buffer,则该buffer会被缓冲池1回收。如果Task 2的速度比1慢,那么buffer的回收率速度就会赶不上Task 1取buffer的速度,导致缓冲池1无可用的buffer,Task 1等待在可用的buffer上。最终形成Task 1的降速。
2)远程传输:如果Task1和Task 2运行在不同的worker路由器上,那么buffer会在发送到网络(TCP Channel)后被回收。在接收端,会从LocalBufferPool中申请buffer,然后复制网络中的数据到缓冲区中。如果没有可用的缓冲区,会停止从TCP连接中读取数据。在输出端,通过Netty的水位值机制来保证不往网络中写入太多数据(后面会说)。如果网络中的数据(Netty输出缓冲中的字节数)超过了高水位值,我们会等到其降到低水位值以下才继续写入数据。这保证了网络中不会有太多的数据。如果接收端停止消费网络中的数据(由于接收端缓冲池没有可用的缓冲区),网络中的缓冲数据就会堆积,那么发送端也会暂停发送。在向LocalBufferPool请求缓冲区,分开了作家往ResultSubPartition写数据。
这种固定大小的缓冲池就像是两块一样,保证了Flink有一套健壮的反压机制,因此任务生产数据的速度不会快于消费的速度。的数据传输自然地扩展到更复杂的管道。