锁(synchronized)和死锁
文章目录
- 前言
- 一.为什么要有锁(synchronized)
-
- 1.线程安全
- 2.线程不安全的原因
-
- 修改共享数据
- 原子性
- 可见性
- 二.synchronized的使用
-
- 1.解决之前的线程不安全问题
- 2.特性
-
- 1)互斥
- 2)刷新内存
- 3)可重入
- 3.使用示例
-
- 1)直接修饰普通方法
- 2)修饰静态方法
- 3)修饰代码块
- 三.死锁
-
- 1.死锁的成因
- 2.解决方法
前言
上一篇是讲述的进程和线程, 并讲述了他们之间的联系和不同之处, 多线程的存在很大程度上的解决了频繁创建销毁进程的开销过大, 但同时多线程在带来便利的同时带来了线程安全的问题, 这其中就包括我们经常能听到的死锁问题
一.为什么要有锁(synchronized)
1.线程安全
我们先来看下面一段代码:
static class Counter {
public int count = 0;
void increase() {
count++;
}
}
public static void main(String[] args) throws InterruptedException {
final Counter counter = new Counter();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(counter.count);
}
上面的代码的大致思路是这样的: 创建了一个count的用来计数的变量, 然后用t1, t2两个线程调用increase()方法来对count分别累加5000次, 那么理论上合起来应是累加了10000次, 但运行结果真的是这样吗 ? ? ?
运行结果:


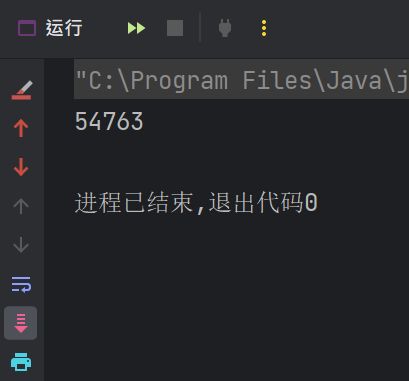
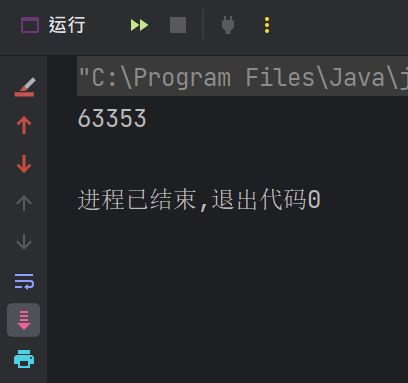
上面是运行了四次的运行结果, 可以发现每次的结果都不一样, 这是为什么呢 ? ? ?
如果这里的代码是单线程, 那么就没有问题了, 但是在多线程的情况下这种对同一个变量进行修改他的值就属于线程不安全 ! ! !
2.线程不安全的原因
修改共享数据
上述代码是t1,t2两个线程分别对counter.count变量进行修改, 此时这个counter.count就是共享数据
原子性
修改数据这个操作不是原子性的 ! ! !
在修改数据时的过程 : CPU通过地址找到数据在内存中保存的位置, 然后读取数据加载到寄存器中, 进行修改 (如加, 减, 乘, 除) 后再写回到原内存地址

而在多个线程同时修改同一变量时, 因修改变量不是原子性的原因, 就会发生吞掉某一次修改等情况的发生. 如t1现在是以及修改完毕, 在他把新的变量写回内存之前, t2读取了在内存中的旧数据, 而非t1修改后的新数据, 那么等t2修改完写回内存时, 就相当于吞掉了t1先前的修改.
这也就是为什么上面的代码我们通过t1, t2两个线程来对counter.count分别自增5000得出的结果总是小于10000
可见性
可见性是指: 一个线程对变量的修改, 能够及时被其他线程看到
二.synchronized的使用
1.解决之前的线程不安全问题
static class Counter {
public int count = 0;
synchronized void increase() {
count++;
}
}
public static void main(String[] args) throws InterruptedException {
final Counter counter = new Counter();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(counter.count);
}
运行结果 :

通过对修改变量的操作加锁, 把其变成一个原子操作, 那么问题就解决了
2.特性
1)互斥
synchronized会起到互斥效果, 某个线程执行到某个对象的synchronized的时, 其他线程如果也执行到同一个对象的synchronized就会等待阻塞
- 进入synchronized修饰的代码块, 相当于加锁
- 退出synchronized修饰的代码块, 相当于解锁
synchronized用的锁是存在Java对象头里面的.

阻塞等待 :
针对每一把锁, 操作系统内部维护了一个等待队列, 当这个锁被某个线程占有的时候, 其他线程尝试进行加锁, 就加不上了, 就会阻塞等待, 一直等到之前的线程释放锁后, 有操作系统唤醒一个新的线程, 再来获取到这个锁
注意 :
- 上一个线程解锁后, 下一个线程并不能立即就获取到锁, 而是等操作系统唤醒, 这也是操作系统线程调度的一部分
- 重新获取锁并不遵从先来后到的原则, 要看具体的调度算法来决定
synchronized的底层是使用操作系统的mutex lock实现的.
2)刷新内存
synchronized的工作流程 :
- 获得互斥锁
- 从内存读数据存到寄存器
- 执行代码
- 将更改后的值刷新到内存
- 释放互斥锁
故他刷新了内存, 保证了内存可见性, 与volatile的刷新内存一样
3)可重入
synchronized 同步块对同一线程来说是可重入的, 不会出现把自己锁死的问题.
也就是说synchronized是允许下面代码的存在的 :
synchronized (locker) {
synchronized (locker) {
synchronized (locker) {
synchronized (locker) {
}
}
}
}
}
但释放锁只能在最外层才可以, 那么如何知道是否是最外层呢 ?
在可重入锁的内部, 包含了"线程持有者"和"计数器"两个信息.
- 如果某个线程加锁的时候, 发现锁已被占用, 但是恰好占用的是自己, 那么仍然还可以继续获取到锁, 并让计数器自增
- 解锁的时候, 计数器自减为 0 时 (也就是来到了最外层) , 才能真正释放锁,
3.使用示例
1)直接修饰普通方法
锁的Demo对象 :
public class Demo {
public synchronized void fun() {
}
}
2)修饰静态方法
锁的Demo的类对象 :
public class Demo {
public synchronized static void fun() {
}
}
3)修饰代码块
锁当前对象 :
public class Demo {
public void fun() {
synchronized (this) {
}
}
}
锁类对象 :
public class Demo {
public void fun() {
synchronized (Demo.class) {
}
}
}
三.死锁
1.死锁的成因
要达成死锁需要四个必要条件:
- 互斥使用: 一个线程持有一把锁之后, 另一个线程也想获取到此锁, 就会阻塞等待
- 不可抢占: 一个资源被一个线程使用的情况下, 不能被其他线程抢占, 只能有占有他的线程主动释放
- 请求保持: 一个线程因请求资源而阻塞时, 对以获得的资源保持不放
- 循环等待: 等待依赖的关系成环了, 类似于: 汽车的钥匙锁在了家里, 家的钥匙锁在了汽车里
2.解决方法
同时达成以上四个条件, 才会发生死锁 !
所以要想避免死锁就破坏其中其一即可