应用层—HTTP详解(抓包工具、报文格式、构造http等……)
文章目录
- HTTP
-
- 1. 抓包工具的使用
-
- 1.1 配置信息
- 1.2 观察数据
- 2. 分析 https 抓包结果
- 3. HTTP请求详解
-
- 3.1 认识 URL
-
- 3.1.1 URL 基本格式
- 3.1.2 查询字符串 (query string)
- 3.1.3 关于 URL Encode
- 3.2 认识 http 方法
-
- 3.2.1 [经典问题] Get 和 Post 主要的区别是什么??
- 3.2.2 除了get和post还有什么方法??
- 3.3 认识请求报头(header)
- 4. HTTP响应详解
-
- 4.1 认识状态码
- 5. 构造 HTTP 请求
-
- 5.1 通过 html 中的 form 表单
- 5.2 通过 js 的 ajax
- 5.3 java 代码(其他各种语言的代码)
- 5.4 借助一些第三方工具
HTTP
HTTP (全称为 “超文本传输协议”) 是一种应用非常广泛的 应用层协议。
我们平时打开一个网站,就是通过 Http 协议来传输数据的。
学习 Http 需要先了解 http 协议格式,这里就需要用到 抓包工具。抓包工具本质上是一个代理。
代理:代理是一种网络服务,它充当客户端和目标服务器之间的中间人。代理服务器可以用于多种目的,包括提高访问速度、保护隐私、绕过网络限制等。
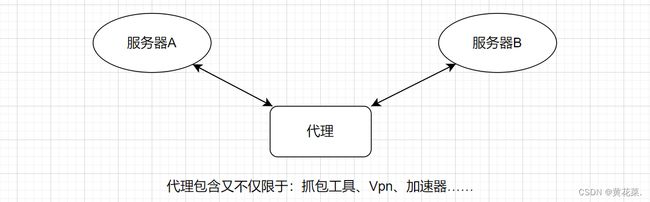
1. 抓包工具的使用
抓包工具有很多,比如:wireshark、fiddler等…
这里我们使用 fiddler 来抓包,同学们可以自行下载。
1.1 配置信息
在我们刚装好 fiddler 之后,默认只能抓到 http 的数据,抓不到 https ,而现在网络上 https 是主流。因此我们要稍微设置一下让 fiddler 能够抓到 https。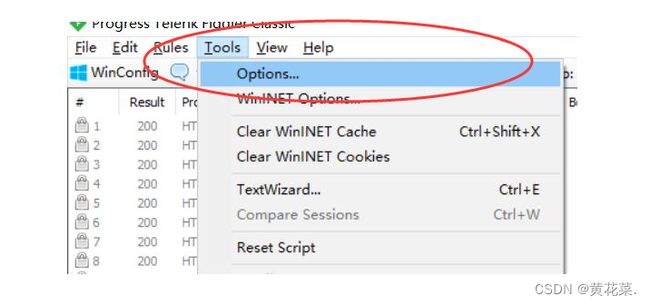

设置完后,我们可以看到,左侧是当前机器上有哪些 http / https数据报在交互(不仅仅能抓浏览器,而且能抓到所有程序的)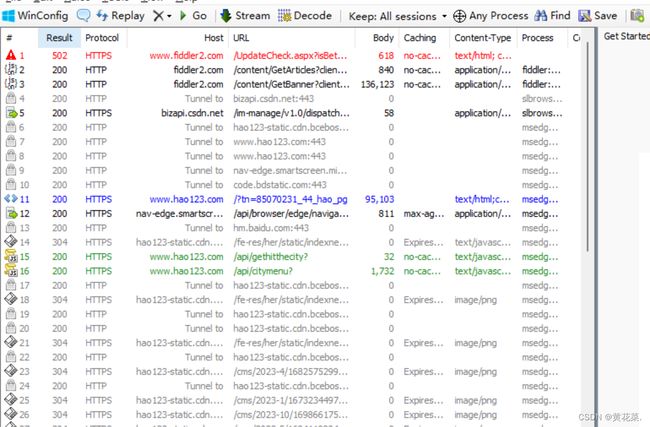
当我们选中某个数据后,右侧就能显示出详细信息,右上角显示的是请求的详情,右下角显示的是响应的内容(在标签栏中点击 Raw 显示 请求/响应 的原始数据内容)
1.2 观察数据
相比于 UDP、TCP 的二进制信息传输来说,Http 则是文本传输格式。如果看不清蓝色信息栏中的数据,我们可以点击下方 View in Notepad 在记事本中打开
观察下面响应信息,为什么会出现乱码呢?
在网络传输过程中,为了节省空间大小,因此会对响应信息进行压缩(点击图片上面黄色区域就会进行解压缩)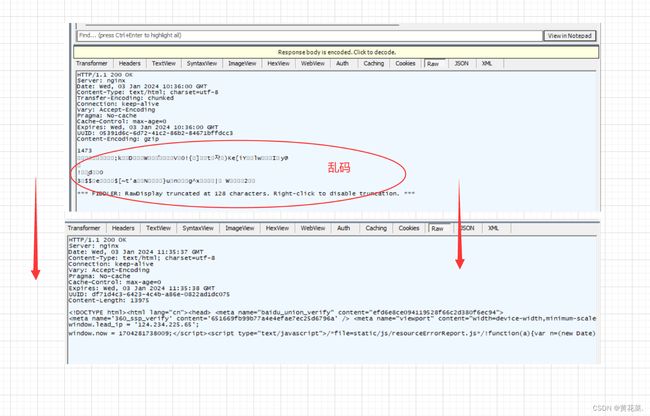
2. 分析 https 抓包结果
下面是一个 HTTPS请求/响应 的抓包结果。

首行组成格式:[方法] + [URL] + [版本];

请求头(header):是请求的属性,用冒号来分割的键值对。每组属性之间用
\n来分隔,遇到空行表示 header 部分 结束。body:空行后面的都是正文(body),body允许为空字符串。如果 body 存在,则在 header 中会有一个 Conent- Length 属性来标识 Body 的长度。

首行:[版本号] + [状态码] + [状态码解释]
响应头:同请求头。也是由键值对组成,由
\n分隔。正文:同请求的正文格式。如果服务器返回了一个 html 页面,那么 html 页面内容就是在 body 中。

3. HTTP请求详解
3.1 认识 URL
3.1.1 URL 基本格式
URL 的格式通常如下:
协议://主机名[:端口号]/路径?查询参数

实际上,对于 URL 来说,上述的几个部分都是可以省略的,此操作是非常常见的。
3.1.2 查询字符串 (query string)
下面举一个具体的例子来说明 URL 格式中的查询字符串。
我们在搜狗上搜索“程序猿”。可以看到服务器是搜狗服务器。同时在搜狗服务器上访问的是 web 资源。后续再在资源中查找“程序猿”这个字符串以及其它字符串。
我们虽然认识了 query string(查询字符串) 的格式,但其内容和含义是什么呢??
其实是这里的 键 和 值 的含义,都是程序猿自定义的。这个东西具体是啥意思?只有搜狗的程序员知道。

3.1.3 关于 URL Encode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了。因此这些字符不能随意出现。
比如,某个参数中需要带有这些特殊字符,就必须先对特殊字符进行转义。
一个中文字符由 UTF-8 或者 GBK 这样的编码方式构成, 虽然在 URL 中没有特殊含义, 但是仍然需
要进行转义. 否则浏览器可能把 UTF-8/GBK 编码中的某个字节当做 URL 中的特殊符号.
转义的规则如下: 将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式。
比如 “+” 被转义成了 “%2B”
UrlEncode - 在线URL网址编码、解码
3.2 认识 http 方法
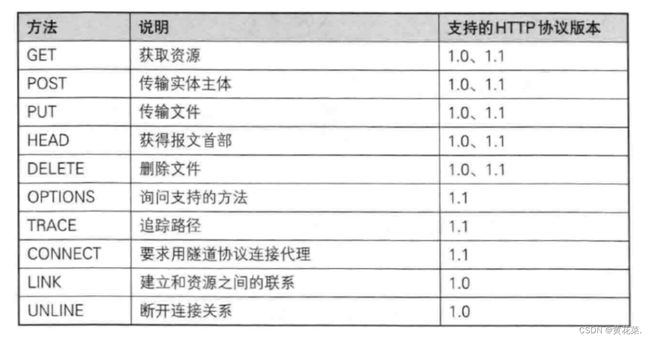
上图中都是http的请求方法,如果说天下文才分十斗,Get就占8斗,Post占1斗,剩下的所有方法占1斗。由此可见各个方法的使用频率不同,Get、Post方法作为我们要熟知的方法,剩下的了解即可。
不同方法之间,“语义”是不同的,描述的是此次方法用来干什么。
- Get:“从服务器获取 xxx”
- Post:“向服务器传输一个 xxxx”
上面我们介绍过 Get 的请求格式,接下来介绍 Post 的几个常见场景:
-
登录

-
上传

此处的 body 中的 value 就是把整个图片都进行转码,转成字符串,填写在这里。
3.2.1 [经典问题] Get 和 Post 主要的区别是什么??
Get 是把一些自定义的数据放到 query string (在 URL 中) 里,body 通常是空的。
Post 是把一些自定义的数据放到 body 里,query string 通常是空的。
因为这些数据都是要传输给服务器的,所以放哪都是放,本质上没啥区别。
- 直接放在 url 中,用户能直接看到。
- 放在 body 中,用户没法直接看到。
因为 post 和 get 数据放哪里本质上都可以,两者经常也可以相互替代。
盖棺定论:GET 和 POST 没有本质区别。从习惯上来看,GET 通常把数据放到 query string 中,POST 通常把数据放到 body 中
对于 Get 和 Post 区别的理解。
3.2.2 除了get和post还有什么方法??
下面这些方法相较于 get、post 比较少见,可以简单了解。

3.3 认识请求报头(header)
header 的整体格式也是“键值对”结构。每个键值对占一行,键和值之间使用分号分割。
以下面的请求报头为例,进行分析:
可以看到此报头也是键值对结构,每一行都是一个键值对,键和值之间用 “:空格” 来分割。
query string / body 中的键值对,完全是程序员自定义的。
header 中的键值对,主要是标准规定的。有哪些键(对应的取值是有哪些,都有规定),也有部分是可以自定义的。
下面来挑几个重要的键值对来分析一下:
-
Host:表示服务器主机的地址和端口。(用于解决粘包问题) -
Content-Length:表示 body 中的数据长度 。 -
Content-Type:表示请求的 body 中的数据格式。(针对这个数据,如何理解?http协议有很多用途,传输的数据也有很多种类)在HTTP请求中,Content-Type有三种主要的情况。-
application/x-www-form-urlencoded:body的格式就和query string一样.(登录请求)
-
multipart/form-data:一般上传文件/图片会是这种情况(不绝对。码云的上传图片就不是这种)
-
application/json:body是 json格式。(很多网站都会广泛使用 json)
如果是响应 body,情况就会更复杂。
可能是 html:text/html,也可能是 css:text/css,还可能是 js:application/javascript,图片 image/png image/jpg 等…
通过 Content-Type 就可以区分出 body 的数据的格式是啥。尤其是浏览器,需要根据不同的格式来决定如何处理。
-
-
User-Agent:表示浏览器/操作系统的属性,现在主要用来区分 PC 端还是 移动端。形如Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 -
Referer:**描述了当前页面从哪来。**如果你是通过浏览器地址来直接输入URL/点击收藏夹 打开的网站,这个请求中不带 referer。但是如果你点击了某个网页的内容,产生跳转,就是带 referer。拓展了解:http由于不带加密传输,因此网络运营商为了卖广告或者其他经济利益,可以直接修改用户的访问源头,就是针对 referer 进行修改,此操作称为运营商劫持。解决办法就是使用https,进行加密传输。
-
Cookie:**是浏览器本地存储数据的一种机制。**在用户操作浏览器的时候会产生很多“临时性”的数据,有的临时数据就直接放到服务器这边存储,下次可以直接获取到。有的不太重要的,就直接放在浏览器这边存储(下次访问也可以直接使用,但是换个电脑可能就没了)其中,Cookie 就是一个主要的保存机制。浏览器要保存数据,为啥要放到 Cookie 中??直接放到硬盘,写入一个文件不行吗? 不行的!如果让网页能够轻易的访问你的文件系统,是非常危险的!!很容易中病毒!
为了保证安全,浏览器会对网页的功能做出限制。(禁止直接访问硬盘,就是其中一个规则),同时又能存储数据,浏览器就提供了Cookie 功能(后来又有了其他功能)
是按照键值对的方式来存储一些字符串。这些键值对往往都是服务器返回回来的。浏览器把这些键值对按照"域名"维度,分类存储。
首次访问网站,注册不考虑,登录成功之后,就相当于,网站就给你了一个就诊卡(身份标识 也叫sessionid)。身份标识就通过服务器返回给浏览器的响应,保存在浏览器的Cookie 中了(键值对)。于此同时,人家网站服务器这边,也就会创建出一个对应的Session (电子档案)Session 中就会记录我的一些关键信息。人家的网站服务器肯定不只一个用户,有很多用户。每个用户都有自己的Session。并且他们的sessionld 各不相同。服务器就会使用类似于hash表这样的方式,以sessionld为key,以Session为value,把所有的数据组织起来。
1.Cookie 从哪里来?
Cookie是从服务器返回给浏览器的。2.Cookie 保存在哪里?
Cookie 保存在浏览器上,浏览器所在电脑的硬盘上。每个域名都有自己的一组Cookie。3.Cookie里的内容是啥?
Cookie 中的内容是键值对结构的数据。这里的键值对都是程序猿自定义的。
其中往往会有一个键值对,作为用户的身份标识 (不同网站身份标识的 key 和 value 可能都是不同的)4.Cookie的内容到哪里去?
后续再访问这个网站中的各个页面,就都会在请求中带上Cookie 。服务器就可以进一步的知道客户端的详细情况了。
4. HTTP响应详解
4.1 认识状态码
响应的首行和请求的首行差异是比较大的。
响应首行由:[版本号] + [状态码] + [状态码解释]组成
HTTP/1.1 200 OK
状态码,就是对这次响应的定性(成功/失败/其它情况)

200成功
404访问的资源不存在
403访问的资源没有权限
502服务器挂了
504服务器超时了
302重定向(浏览器会自动跳转到其他的界面)
重定向:使用浏览器访问 www.aaa.com 这个url ,此时,请求发给对应的服务器。结果服务器返回了一个302,同时告诉你,你要去访问 www.bbb.com 于是浏览器收到这个响应之后,就会自动跳转到 www.bbb.com。
5. 构造 HTTP 请求
5.1 通过 html 中的 form 表单
HTML 也是一种编译语言,和 Java、C 风格差异很大。
HTML:是在描述一个“形态”,一个网页上,都有啥。(形态)
Java、C:是在描述一个“逻辑”,先干啥后干啥,什么情况下要干什么。(动作)
这里编写 html 推荐使用 VSCode,因为可以直接白嫖的,对于前端也同样支持。
对于 html 代码编写起来是非常好理解的,下面是编写 html 的起手式,快捷键是!+tab.
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
head>
<body>
body>
html>

接下来再说通过 html 中的 form 标签构造 HTTP 请求。
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
head>
<body>
<form action="https://www.sogou.com" method="post">
<input type="text" name="aaa">
<input type="text" name="bbb">
<input type="text" name="ccc">
<input type="submit" value="提交">
form>
body>
html>
当我们运行这段代码,再用抓包工具来抓包观察结果。
在输入框中输入的内容有什么作用吗?
其实就是向服务器提交数据,比如说我们进行用户登录,需要输入的账号和密码。
form 表单,只能支持 get 和 post,不能支持 put/delete/options 等其他方法…
5.2 通过 js 的 ajax
ajax 是 js 提供的一组 api。js 原生的 ajax api,用起来非常不方便。因此我们就会借助 js 的第三方库 jQuery,把 jQuery 引入到代码中。
jQuery cdn 是大佬们搞的一组服务器,用来放一些常用的资源。
对于jQuery cdn来说都是开源的,可以直接在网上搜


只需要把这段复制下来即可。
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
head>
<body>
<script src="https://code.jquery.com/jquery-3.7.1.min.js">script>
<script>
//正式的 js 代码,就要调用上面的 jQuery 中的方法了。
$.ajax({
type: "post",
url: "https://www.sogou.com",
contentType: "application/x-www-form-urlencoded",
data: "aaa=111&bbb=222",
success:function(body) {
console.log("ok");
}
});
script>
body>
html>
通过抓包可以看到我们访问的URL、method,以及请求的内容。
5.3 java 代码(其他各种语言的代码)
通过 java 代码的方式,本质上就是一个 tcp 的客户端,创建一个 Socket 对象,往里面按照 HTTP 协议的格式写数据即可。
public class HttpClient {
private Socket socket;
private String ip;
private int port;
public HttpClient(String ip, int port) throws IOException {
this.ip = ip;
this.port = port;
socket = new Socket(ip, port);
}
public String get(String url) throws IOException {
StringBuilder request = new StringBuilder();
// 构造首行
request.append("GET " + url + " HTTP/1.1\n");
// 构造 header
request.append("Host: " + ip + ":" + port + "\n");
// 构造 空行
request.append("\n");
// 发送数据
OutputStream outputStream = socket.getOutputStream();
outputStream.write(request.toString().getBytes());
// 读取响应数据
InputStream inputStream = socket.getInputStream();
byte[] buffer = new byte[1024 * 1024];
int n = inputStream.read(buffer);
return new String(buffer, 0, n, "utf-8");
}
public String post(String url, String body) throws IOException {
StringBuilder request = new StringBuilder();
// 构造首行
request.append("POST " + url + " HTTP/1.1\n");
// 构造 header
request.append("Host: " + ip + ":" + port + "\n");
request.append("Content-Length: " + body.getBytes().length + "\n");
request.append("Content-Type: text/plain\n");
// 构造 空行
request.append("\n");
// 构造 body
request.append(body);
// 发送数据
OutputStream outputStream = socket.getOutputStream();
outputStream.write(request.toString().getBytes());
// 读取响应数据
InputStream inputStream = socket.getInputStream();
byte[] buffer = new byte[1024 * 1024];
int n = inputStream.read(buffer);
return new String(buffer, 0, n, "utf-8");
}
public static void main(String[] args) throws IOException {
HttpClient httpClient = new HttpClient("42.192.83.143", 8080);
String getResp = httpClient.get("/AjaxMockServer/info");
System.out.println(getResp);
String postResp = httpClient.post("/AjaxMockServer/info", "this is body");
System.out.println(postResp);
}
}
5.4 借助一些第三方工具
除了上面这几种写代码的方式之外,还可以通过第三方工具,构造 HTTP 请求。
第三方工具有很多,咱们这里介绍的是 postman,一个老牌的 http 客户端工具。他可以根据你这边构造的请求,自动生成代码。
操作方法:

自动生成代码: