3.大数据技术之Flink(基础篇)
文章目录
- 1、Flink 简介
-
- 1.1 Flink 的引入
- 1.2 什么是Flink
- 2、Flink 架构体系
-
- 2.1 Flink 中的重要角⾊
-
- JobManager 处理器:
- TaskManager 处理器:
- 2.2 无界数据流与有界数据流
-
- 无界数据流:
- 有界数据流:
- 3、Flink 集群操作
- 4、DataSet API 开发
-
- 4.1 案例
-
- 4.1.1 Flink 批处理程序的一般流程
- 4.1.2 JAVA示例
- 5、DataStream API 开发
-
- 5.1 案例
-
- 5.1.1 Flink 流处理程序的一般流程
- 5.1.2 示例
- 5.1.3 步骤
- 5.1.4 参考代码
1、Flink 简介
1.1 Flink 的引入
这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有Hadoop、Storm,以及后来的Spark,他们都有着各自专注的应用场景。Spark 掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。Spark 的火热或多或少的掩盖了其他分布式计算的系统身影。就像Flink,也就在这个时候默默的发展着。
在国外一些社区,有很多人将大数据的计算引擎分成了4 代,当然,也有很多人不会认同。我们先姑且这么认为和讨论。
首先第一代的计算引擎,无疑就是Hadoop 承载的MapReduce。这里大家应该都不会对MapReduce 陌生,它将计算分为两个阶段,分别为Map 和Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个Job 的串联,以完成一个完整的算法,例如迭代计算。
由于这样的弊端,催生了支持DAG 框架的产生。因此,支持DAG 的框架被划分为第二代计算引擎。如Tez 以及更上层的Oozie。这里我们不去细究各种DAG 实现之间的区别,不过对于当时的Tez 和Oozie 来说,大多还是批处理的任务。
接下来就是以Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是Job 内部的DAG 支持(不跨越Job),以及强调的实时计算。在这里,很多人也会认为第三代计算引擎也能够很好的运行批处理的Job。
随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和SQL 等的支持。Flink 的诞生就被归在了第四代。这应该主要表现在Flink 对流计算的支持,以及更一步的实时性上面。当然Flink 也可以支持Batch 的任务,以及DAG 的运算。
首先,我们可以通过下面的性能测试初步了解两个框架的性能区别,它们都可以基于内存计算框架进行实时计算,所以都拥有非常好的计算性能。经过测试,Flink 计算性能上略好。
1.2 什么是Flink
Flink 起源于Stratosphere 项目,Stratosphere 是在2010~2014 年由3 所地处柏林的大学和欧洲的一些其他的大学共同进行的研究项目,2014 年4 月Stratosphere 的代码被复制并捐赠给了Apache 软件基金会,参加这个孵化项目的初始成员是Stratosphere 系统的核心开发人员,2014 年12 月,Flink 一跃成为Apache 软件基金会的顶级项目。
在德语中,Flink 一词表示快速和灵巧,项目采用一只松鼠的彩色图案作为logo,这不仅是因为松鼠具有快速和灵巧的特点,还因为柏林的松鼠有一种迷人的红棕色,而Flink 的松鼠logo拥有可爱的尾巴,尾巴的颜色与Apache 软件基金会的logo 颜色相呼应,也就是说,这是一只Apache 风格的松鼠。

Flink 主页在其顶部展示了该项目的理念:“Apache Flink 是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架”。
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
2、Flink 架构体系
2.1 Flink 中的重要角⾊
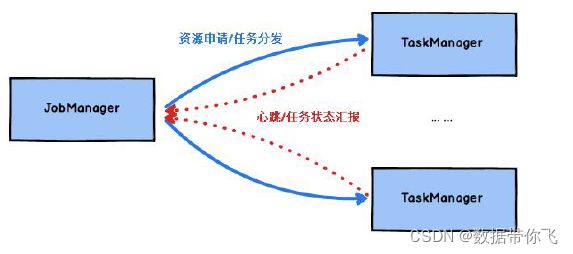
JobManager 处理器:
也称之为Master,用于协调分布式执行,它们用来调度task,协调检查点,协调失败时恢复等。Flink 运行时至少存在一个master 处理器,如果配置高可用模式则会存在多个master 处理器,它们其中有一个是leader,而其他的都是standby。
TaskManager 处理器:
也称之为Worker,用于执行一个dataflow 的task(或者特殊的subtask)、数据缓冲和datastream 的交换,Flink 运行时至少会存在一个worker 处理器。
2.2 无界数据流与有界数据流
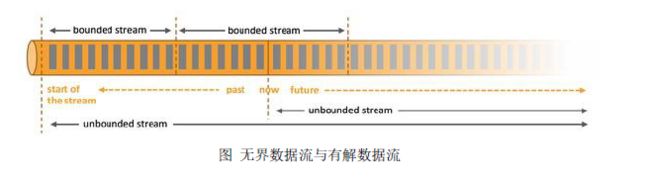
无界数据流:
无界数据流有一个开始但是没有结束,它们不会在生成时终止并提供数据,必须连续处理无界流,也就是说必须在获取后立即处理event。对于无界数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取event,以便能够推断结果完整性。
有界数据流:
有界数据流有明确定义的开始和结束,可以在执行任何计算之前通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有界数据集进行排序,有界流的处理也称为批处理。
Apache Flink 是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink 运行时(Flink Runtime),提供支持流处理和批处理两种类型应用的功能。现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型,因为它们要实现的目标是完全不相同的:流处理一般需要支持低延迟、Exactly-once 保证,而批处理需要支持高吞吐、高效处理,所以在实现的时候通常是分别给出两套实现方法,或者通过一个独立的开源框架来实现其中每一种处理方案。例如,实现批处理的开源方案有MapReduce、Tez、Crunch、Spark,实现流处理的开源方案有Samza、Storm。
Flink 在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来:Flink 是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。基于同一个Flink 运行时(Flink Runtime),分别提供了流处理和批处理API,而这两种API 也是实现上层面向流处理、批处理类型应用框架的基础。
3、Flink 集群操作
- 启动Flink 集群
cd /opt/servers/flink-1.10.1
bin/start-cluster.sh
- 通过jps 查看进程信息
--------------------- hadoop01 ----------------
86583 Jps
85963 StandaloneSessionClusterEntrypoint
86446 TaskManagerRunner
--------------------- hadoop03 ----------------
44099 Jps
43819 TaskManagerRunner
--------------------- hadoop03 ----------------
29461 TaskManagerRunner
29678 Jps
- 并运行测试任务
bin/flink run examples/batch/WordCount.jar --input hdfs://hadoop01:8020/test/input/wordcount --output hdfs://hadoop01:8020/test/output/001
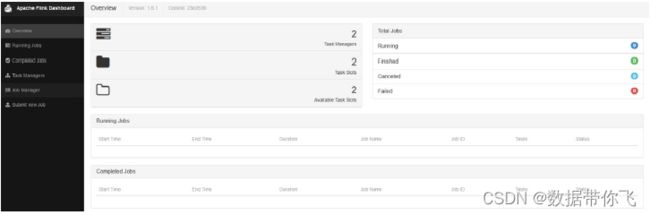
- 浏览Flink Web UI 界面
http://hadoop01:8081
5)启动/停止flink 集群
启动:bin/start-cluster.sh
停止:bin/stop-cluster.sh
4、DataSet API 开发
4.1 案例
4.1.1 Flink 批处理程序的一般流程
-
获取Flink 批处理执行环境
-
构建source
-
数据处理
-
构建sink
4.1.2 JAVA示例
导入Flink 所需的Maven 依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-coreartifactId>
<version>1.10.1version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>1.10.1version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_2.12artifactId>
<version>1.10.1version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.7.7version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.7.7version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.12artifactId>
<version>1.10.1version>
dependency>
使用java编写Flink 程序,用来统计单词的数量。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
//批处理指的是离线数据的处理
public class BatchWordCount {
public static void main(String[] args) throws Exception {
/**
* 1.读取外部文件,word.txt,词频统计
*/
//1.创建批处理运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//2.创建数据源 source
//readTextFile用于读取外部文件,既可以是本地文件,也可以是hdfs
DataSource<String> source = env.readTextFile("hdfs://hadoop01:8020/test/input/word.txt");
//3.数据处理过程, 处理过程中会调用dataset的方法,这些方法称为算子,也叫作operator
//hello world hadoop --> hello 1 world 1 hadoop 1
//常用算子map:完成数据一对一转换操作
// flatMap(扁平化处理):数据压扁,数据会形成一对多的操作
// filter :数据的过滤
// reduce: 数据的聚合
FlatMapOperator<String, Tuple2<String, Integer>> wordAndOne = source.flatMap(
//泛型表示,接收的数据类型和返回的数据类型
new FlatMapFunction<String, Tuple2<String, Integer>>() {
/**
* 会一行一行数据处理
* @param value:获取一行一行的数据
* @param out:收集器,将数据收集输出
* @throws Exception
*/
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
// value :hello world hadoop
String[] words = value.split(" ");
//将每一个词循环输出
for (String word : words) {
//将数据收集输出
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
});
//先分组,再聚合,0表示按照第一个字段分组
UnsortedGrouping<Tuple2<String, Integer>> groupByOperator = wordAndOne.groupBy(0);
//数据聚合,1表示第二个字段
AggregateOperator<Tuple2<String, Integer>> result = groupByOperator.sum(1);
//4.数据下沉 sink
//print是sink的方法,在下沉中使用
//result.print();
result.writeAsText("hdfs://hadoop01:8020/test/output111", FileSystem.WriteMode.OVERWRITE).setParallelism(1);
//flink中是惰性加载,必须加上execute
env.execute();
}
}
5、DataStream API 开发
5.1 案例
5.1.1 Flink 流处理程序的一般流程
-
获取Flink 流处理执行环境
-
构建source
-
数据处理
-
构建sink
5.1.2 示例
编写Flink 程序,用来统计单词的数量。
5.1.3 步骤
-
获取Flink 批处理运行环境
-
构建一个socket 源
-
使用flink 操作进行单词统计
-
打印
5.1.4 参考代码
public static void main(String[] args) throws Exception {
//1.创建流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.指定数据源 socket数据源中输入一行一行的数据:hello world
DataStreamSource<String> source = env.socketTextStream("hadoop01", 9999);
//3.数据处理
//hello world --》 hello 1
SingleOutputStreamOperator<Tuple2<String, Integer>> flatMapOperator = source.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
//value拆分
String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
});
//分流,聚合
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = flatMapOperator.keyBy(0);
//集合的是无界的数据流
//SingleOutputStreamOperator> result = keyedStream.sum(1);
//有界的数据流
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> windowStream = keyedStream.timeWindow(Time.seconds(10));
SingleOutputStreamOperator<Tuple2<String, Integer>> result = windowStream.sum(1);
//4.数据下沉
result.print();
env.execute();
}
注:安装netcat
yum -y install nc