#Python实战:selenium模拟浏览器运行,获取软科网站2023中国大学排名
在爬取一些加密的网页时,可以使用selenium模拟浏览器运行,再从网页中提取想要的数据。
使用的库
本文使用到的 Python 库有:selenium、bs4、pandas
使用selenium解决网页的反爬
使用bs4对html网页进行解析和提取数据
使用pandas对获取到的数据保存到excel表
目标网页
2023 中国大学排名:
https://www.shanghairanking.cn/rankings/bcur/2023
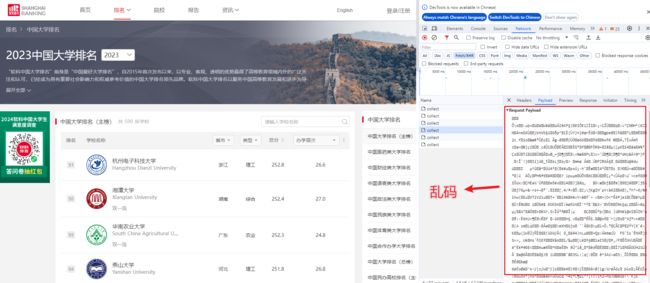
在爬取软科网站时,由于请求是加密的,不能简单使用 request 库直接爬取,换用 Selenium 库模拟真实用户去访问网页。
Selenium 是广泛使用的模拟浏览器运行的库,它是一个用于 Web 应用程序测试的工具。 Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。
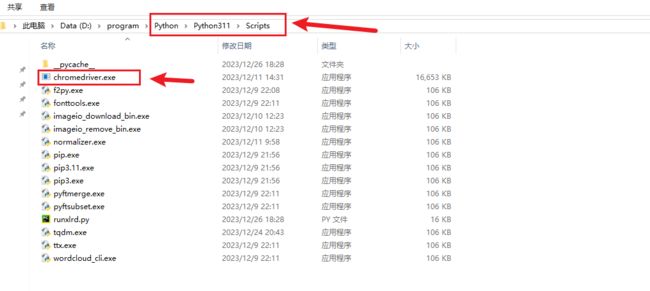
使用 selenium 需要下载 chromedriver 驱动,放在 Python 安装的路径下。
可以去这个链接下载最新版本 chromedriver 驱动 https://googlechromelabs.github.io/chrome-for-testing/
(本文首发在“程序员coding”公众号)
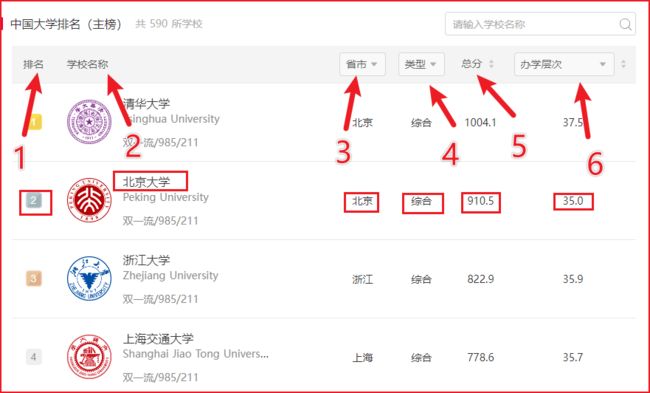
爬取的字段
爬取“排名”、“学校名称”、“省市”、“类型”、“总分”、“办学层次”这 6 个字段。
启动谷歌浏览器
#(本文首发在“程序员coding”公众号)
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
import bs4
option = webdriver.ChromeOptions()
# option是让谷歌一直开着,而不是只打开一下子就关掉
option.add_experimental_option("detach", True)
# 定义url
url = "https://www.shanghairanking.cn/rankings/bcur/2023"
# 启动谷歌浏览器
browser = webdriver.Chrome(options=option)
# # 浏览器最大化
# browser.maximize_window()
# 访问url
browser.get(url)
# 隐式等待
browser.implicitly_wait(5)
提取数据
检索网页中的数据,这些数据都在“tbody”里面,取出来放进数组里面。
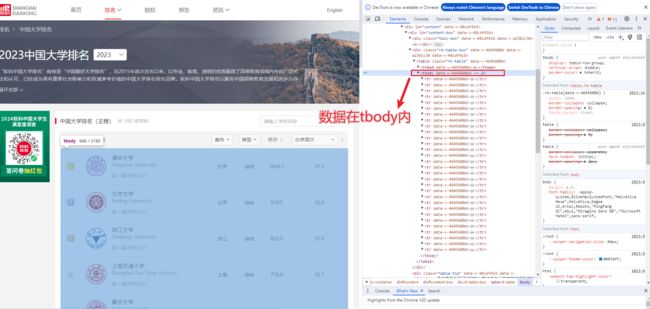
# 先创建一个数组,保存结果
contents = []
# 检索数据取出放进数组里面
def get_data():
# 获取全部网页信息
html = browser.page_source
soup = BeautifulSoup(html, "html.parser")
# 找到tbody的子节点
for tr in soup.find('tbody').children:
# 判断tr是否属于子节点中
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
# 获取文本,清除换行符,清空空格
name = tr.find(class_="name-cn").text.replace('\n', '').strip()
contents.append([tds[0].text.strip(), name, tds[2].text.strip(), tds[3].text.strip(),
tds[4].text.strip(), tds[5].text.strip()])
print("总计获取到", len(contents), "个学校排名")
翻页爬取
排名的数据一共有 20 页,定位到翻页元素,使用click()点击事件,切换到下一页,再调用get_data()函数提取网页中的数据。
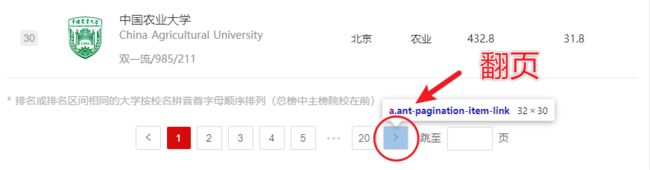
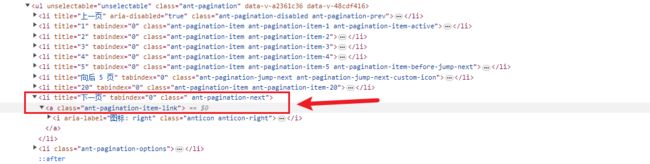
def get_all():
page = 1
while page <= 20: # 循环页数
# print("开始爬取第", page, "页")
get_data(page) # 每次循环都要调用一次获取数据的函数
next_page = browser.find_element(By.CSS_SELECTOR, 'li.ant-pagination-next>a')
next_page.click() # 点击下一页,selenium内置的点击事件
page += 1 # 循环完加一
保存到excel表
使用 pandas 将列表中的数据转为 DataFram 类型,对"排名"、“总分”、"办学层次"3 字段处理,这 3 个字段数据类型是 str 字符串类型,将字符串类型转为 int 和 float 数据类型,再保存到 excel 表中。
由于"办学层次"字段有空值,需要使用pd.to_numeric函数,将 errors 参数设为coerce,可以将无效解析设置为NaN。
errors 有 3 种类型{‘ignore’, ‘raise’, ‘coerce’},默认为raise,这里选择使用corece,将无效解析设置为NaN。
raise参数:无效的解析将引发异常
corece参数:将无效解析设置为 NaN
ignore参数:**无效的解析将返回输入
def save_data(data):
first_name = ["排名", "学校名称", "省市", "类型", "总分", "办学层次"]
rank = pd.DataFrame(data, columns=first_name)
# 将字符串转为int或float类型
rank["排名"] = rank["排名"].astype(int)
rank["总分"] = rank["总分"].astype(float)
# pd.to_numeric函数errors参数设为'coerce',可以将无效解析设置为NaN
rank["办学层次"] = rank["办学层次"].apply(pd.to_numeric, errors='coerce')
print(rank.head())
rank.to_excel("2023中国大学排名2.xlsx", index=False)
print("保存成功!")
关闭浏览器
# 关闭浏览器
browser.quit()
保存的 excel 表如下,总共获取到 590 个学校排名:
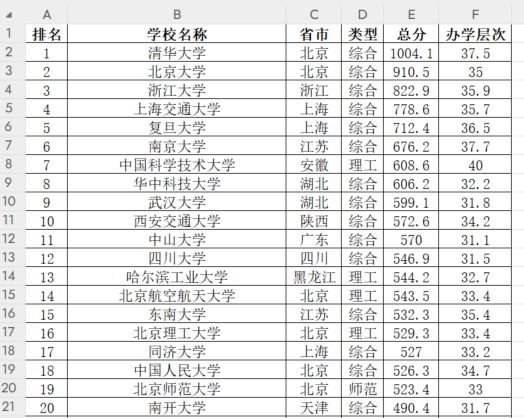
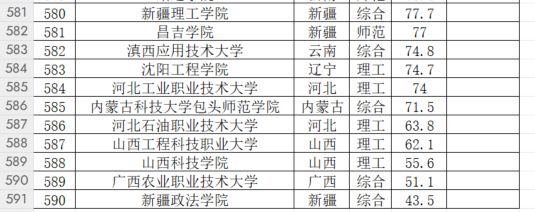
(本文首发在“程序员coding”公众号)
更多排名
使用类似的方法,可以爬取软科网站的其他排名,有兴趣的可以自己试一试。
难点
本文使用 selenium 模拟浏览器运行,使用了翻页爬取,获取了软科网站 2023 中国大学排名,获取到 20 页网页 590 个学校的排名。爬取过程中的困难主要是使用 selenium 定位元素,需要多练习。
完整代码
整合代码,完美运行。完整代码如下:
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
import bs4
option = webdriver.ChromeOptions()
# option是让谷歌一直开着,而不是只打开一下子就关掉
option.add_experimental_option("detach", True)
# 定义url
url = "https://www.shanghairanking.cn/rankings/bcur/2023"
# 启动谷歌浏览器
browser = webdriver.Chrome(options=option)
# # 浏览器最大化
# browser.maximize_window()
# 访问url
browser.get(url)
# 隐式等待
browser.implicitly_wait(5)
# 先创建一个数组,保存结果
contents = []
# 检索数据取出放进数组里面
def get_data(page):
# 获取全部网页信息
html = browser.page_source
soup = BeautifulSoup(html, "html.parser")
# 找到tbody的子节点
for tr in soup.find('tbody').children:
# 判断tr是否属于子节点中
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
# 获取文本,清除换行符,清空空格
name = tr.find(class_="name-cn").text.replace('\n', '').strip()
contents.append([tds[0].text.strip(), name, tds[2].text.strip(), tds[3].text.strip(),
tds[4].text.strip(), tds[5].text.strip()])
print("开始爬取第", page, "页", "总计获取到", len(contents), "个学校排名")
def get_all():
page = 1
while page <= 20: # 循环页数
# print("开始爬取第", page, "页")
get_data(page) # 每次循环都要调用一次获取数据的函数
next_page = browser.find_element(By.CSS_SELECTOR, 'li.ant-pagination-next>a')
next_page.click() # 点击下一页,selenium内置的点击事件
page += 1 # 循环完加一
def save_data(data):
first_name = ["排名", "学校名称", "省市", "类型", "总分", "办学层次"]
rank = pd.DataFrame(data, columns=first_name)
# 将字符串转为int或float类型
rank["排名"] = rank["排名"].astype(int)
rank["总分"] = rank["总分"].astype(float)
# pd.to_numeric函数errors参数设为'coerce',可以将无效解析设置为NaN
rank["办学层次"] = rank["办学层次"].apply(pd.to_numeric, errors='coerce')
print(rank.head())
rank.to_excel("2023中国大学排名2.xlsx", index=False)
print("保存成功!")
if __name__ == '__main__':
get_all()
save_data(contents)
# 关闭浏览器
browser.quit()
本文首发在“程序员coding”公众号,欢迎关注与我一起交流学习。