非线性最小二乘问题的数值方法 —— 从高斯-牛顿法到列文伯格-马夸尔特法 (II, Python 简单实例)
Title: 非线性最小二乘问题的数值方法 —— 从高斯-牛顿法到列文伯格-马夸尔特法 (II, Python 简单实例)
姊妹博文
非线性最小二乘问题的数值方法 —— 从高斯-牛顿法到列文伯格-马夸尔特法 (I)
文章目录
-
- 0.前言
- 1. 最优问题实例
- 2. 列文伯格-马夸尔特法 (Levenberg-Marquardt Method) 计算
- 3. 结果显示
- 4. 结论
0.前言
本篇博文作为对前述 “非线性最小二乘问题的数值方法 —— 从高斯-牛顿法到列文伯格-马夸尔特法 (I)” 的简单实践扩展.
理论部分参见前述博文, 此处不再重复. 这里只是补充一个简单的 Python 实例.
1. 最优问题实例
m i n i m i z e g ( x ) = 1 2 ∥ r ( x ) ∥ 2 2 = 1 2 ∑ i = 1 3 r i ( x ) 2 (I-1) {\rm minimize}\quad {g}(\mathbf{x}) = \frac{1}{2}\|\mathbf{r}(\mathbf{x})\|_2^2 = \frac{1}{2}\sum_{i=1}^{3} r_i(\mathbf{x})^2 \tag{I-1} minimizeg(x)=21∥r(x)∥22=21i=1∑3ri(x)2(I-1)
其中
x = [ x 1 , x 2 ] T \mathbf{x} = \begin{bmatrix} x_1, x_2 \end{bmatrix}^{\small\rm T} x=[x1,x2]T
r ( x ) = [ r 1 ( x ) , r 2 ( x ) , r 3 ( x ) ] T \mathbf{r}(\mathbf{x}) = \begin{bmatrix} r_1(\mathbf{x}), \, r_2(\mathbf{x}) ,\,r_3(\mathbf{x}) \end{bmatrix}^{\small\rm T} r(x)=[r1(x),r2(x),r3(x)]T
r 1 ( x ) = sin x 1 − 0.4 r_1(\mathbf{x}) = \sin x_1 -0.4 r1(x)=sinx1−0.4
r 2 ( x ) = cos x 2 + 0.8 r_2(\mathbf{x}) = \cos x_2 + 0.8 r2(x)=cosx2+0.8
r 3 ( x ) = x 1 2 + x 2 2 − 1 r_3(\mathbf{x}) = \sqrt{x_1^2 +x_2^2} -1 r3(x)=x12+x22−1
可以推得
∂ r ( x ) ∂ x = [ cos x 1 0 0 − sin x 2 x 1 x 1 2 + x 2 2 x 2 x 1 2 + x 2 2 ] \frac{\partial \mathbf{r}(\mathbf{x})}{\partial \mathbf{x}} = \begin{bmatrix}\cos x_1 & 0\\ 0 &-\sin x_2 \\ \frac{x_1}{\sqrt{x_1^2+x_2^2}} & \frac{x_2}{\sqrt{x_1^2+x_2^2}} \end{bmatrix} ∂x∂r(x)= cosx10x12+x22x10−sinx2x12+x22x2
g ( x ) = 1 2 [ ( sin x 1 − 0.4 ) 2 + ( cos x 2 + 0.8 ) 2 + ( x 2 2 + x 1 2 − 1 ) 2 ] g(\mathbf{x})=\frac{1}{2} \left[{ {{\left( \sin{ {x_1} }-0.4\right) }^{2}}+{{\left( \cos{ {x_2} }+0.8\right) }^{2}}+{{\left( \sqrt{{{{x_2}}^{2}}+{{{x_1}}^{2}}}-1\right) }^{2}}}\right] g(x)=21[(sinx1−0.4)2+(cosx2+0.8)2+(x22+x12−1)2]
∇ g ( x ) = [ x 1 ( x 2 2 + x 1 2 − 1 ) x 2 2 + x 1 2 + cos x 1 ( sin x 1 − 0.4 ) x 2 ( x 2 2 + x 1 2 − 1 ) x 2 2 + x 1 2 − sin x 2 ( cos x 2 + 0.8 ) ] \nabla g(\mathbf{x}) = \begin{bmatrix}\frac{{x_1} \left( \sqrt{{{{x_2}}^{2}}+{{{x_1}}^{2}}}-1\right) }{\sqrt{{{{x_2}}^{2}}+{{{x_1}}^{2}}}}+\cos{ {x_1} } \left( \sin{ {x_1} }-0.4\right) \\ \frac{{x_2} \left( \sqrt{{{{x_2}}^{2}}+{{{x_1}}^{2}}}-1\right) }{\sqrt{{{{x_2}}^{2}}+{{{x_1}}^{2}}}}- \sin{ {x_2} } \left( \cos{ {x_2} }+0.8\right) \end{bmatrix} ∇g(x)= x22+x12x1(x22+x12−1)+cosx1(sinx1−0.4)x22+x12x2(x22+x12−1)−sinx2(cosx2+0.8)
H ~ ( x ) = [ x 1 2 x 2 2 + x 1 2 + ( cos x 1 ) 2 x 1 x 2 x 2 2 + x 1 2 x 1 x 2 x 2 2 + x 1 2 ( sin x 2 ) 2 + x 2 2 x 2 2 + x 1 2 ] \widetilde{\mathbf{H}}(\mathbf{x})=\begin{bmatrix}\frac{{{{x_1}}^{2}}}{{{{x_2}}^{2}}+{{{x_1}}^{2}}}+{{(\cos{ {x_1} })}^{2}} & \frac{{x_1} {x_2}}{{{{x_2}}^{2}}+{{{x_1}}^{2}}}\\ \frac{{x_1} {x_2}}{{{{x_2}}^{2}}+{{{x_1}}^{2}}} & {{(\sin{ {x_2} )}}^{2}}+\frac{{{{x_2}}^{2}}}{{{{x_2}}^{2}}+{{{x_1}}^{2}}}\end{bmatrix} H (x)=[x22+x12x12+(cosx1)2x22+x12x1x2x22+x12x1x2(sinx2)2+x22+x12x22]
具体的符号推导参见非线性最小二乘问题的数值方法 —— 从牛顿迭代法到高斯-牛顿法 (实例篇 V).
2. 列文伯格-马夸尔特法 (Levenberg-Marquardt Method) 计算
基于列文伯格-马夸尔特法的算法流程实现如下简单 Python Demo:
from mpl_toolkits.mplot3d import axes3d
import matplotlib.pyplot as plt
import numpy as np
from numpy.linalg import inv, det, norm
from math import cos
from math import sin
from math import sqrt
from math import pow
# multiplication of two matrixs
def multiply_matrix(A, B):
if A.shape[1] == B.shape[0]:
C = np.zeros((A.shape[0], B.shape[1]), dtype = float)
[rows, cols] = C.shape
for row in range(rows):
for col in range(cols):
for elt in range(len(B)):
C[row, col] += A[row, elt] * B[elt, col]
return C
else:
return "Cannot multiply A and B. Please check whether the dimensions of the inputs are compatible."
# g(x) = (1/2) ||r(x)||_2^2
def g(x_1, x_2):
return ( pow(sin(x_1)-0.4, 2)+ pow(cos(x_2)+0.8, 2) + pow(sqrt(pow(x_2,2)+pow(x_1,2))-1, 2) ) /2
# r(x) = [r_1, r_2, r_3]^{T}
def r(x_1, x_2):
return np.array([[sin(x_1)-0.4],
[cos(x_2)+0.8],
[sqrt(pow(x_1,2)+pow(x_2,2))-1]], dtype=object)
# \partial r(x) / \partial x
def dr(x_1, x_2):
if sqrt(pow(x_2,2)+pow(x_1,2)) < 1e-3: ## 人为设置
return np.array([[cos(x_1), 0],
[0, -sin(x_2)],
[0, 0]], dtype=object)
else:
return np.array([[cos(x_1), 0],
[0, -sin(x_2)],
[x_1/sqrt(pow(x_2,2)+pow(x_1,2)), x_2/sqrt(pow(x_2,2)+pow(x_1,2))]], dtype=object)
# Simplified Hessian matrix in Gauss-Newton method
# refer to eq. (I-1-2) in blog "非线性最小二乘问题的数值方法 —— 从高斯-牛顿法到列文伯格-马夸尔特法 (I)"
def sH(x_1, x_2):
return multiply_matrix(np.transpose(dr(x_1, x_2)), dr(x_1, x_2))
# \nabla g(x_1, x_2)
# refer to eq. (I-1-3) in blog "非线性最小二乘问题的数值方法 —— 从高斯-牛顿法到列文伯格-马夸尔特法 (I)"
def dg(x_1, x_2):
return multiply_matrix(np.transpose(dr(x_1, x_2)), r(x_1, x_2))
# model for the cost function g
def L_model(h_vector, g_i, dg_i, sH_i):
return g_i + multiply_matrix( dg_i.transpose(), h_vector) + 0.5 * multiply_matrix(multiply_matrix(h_vector.transpose(), sH_i), h_vector)
def levenberg_marquardt_method(x_1, x_2, epsilon_1, epsilon_2, max_iter):
iter = 0
tau = 1
found = False
sH_i = sH(x_1, x_2)
dg_i = dg(x_1, x_2)
mu_i = tau * np.max(np.diag(sH_i))
# if np.max(np.abs(dg_i)) < epsilon_1:
if norm(dg_i, np.inf) < epsilon_1:
found = True
x_current_1 = x_1
x_current_2 = x_2
x_current_vector = np.array([[x_current_1], [x_current_2]], dtype=object)
g_current = g(x_current_1, x_current_2)
array_x_1 = []
array_x_2 = []
array_x_3 = []
array_x_1.append(x_current_1)
array_x_2.append(x_current_2)
array_x_3.append(g_current)
# new_x = np.matrix([[0],[0]])
x_new_1 = 0
x_new_2 = 0
g_new = np.inf
while (found == False) and (iter < max_iter):
iter += 1
inv_sH_i = inv(sH_i + mu_i * np.diag(np.diag(sH_i)))
h_step = - multiply_matrix(inv_sH_i, dg_i)
if norm(h_step, 2) <= epsilon_2*(norm(x_current_vector) + epsilon_2):
found = True
else:
x_new_1 = x_current_1 + h_step[0]
x_new_2 = x_current_2 + h_step[1]
if g_new != np.inf:
g_current = g_new
g_new = g(x_new_1, x_new_2)
rho = (g_current - g_new) / (g_current - L_model(h_step, g_current, dg_i, sH_i))
if rho > 0: # step acceptable
x_current_1 = x_new_1
x_current_2 = x_new_2
x_current_vector = np.array([[x_current_1], [x_current_2]], dtype=object)
sH_i = sH(x_current_1, x_current_2)
dg_i = dg(x_current_1, x_current_2)
if norm(dg_i, np.inf) < epsilon_1:
found = True
mu_i = mu_i * np.max( np.array([1/3, 1-pow(2*rho-1,3)], dtype=object))
v_i = 2
array_x_1.append(x_new_1)
array_x_2.append(x_new_2)
array_x_3.append(g_new)
else: # step unacceptable
mu_i = mu_i * v_i
v_i = 2* v_i
return array_x_1, array_x_2, array_x_3
def result_plot(trajectory):
fig = plt.figure()
ax3 = plt.axes(projection='3d')
xx = np.arange(-5,5,0.1)
yy = np.arange(-4,4,0.1)
X, Y = np.meshgrid(xx, yy)
Z = np.zeros((X.shape[0], Y.shape[1]), dtype = float)
for i in range(X.shape[0]):
for j in range(Y.shape[1]):
Z[i,j] = g(X[0,j], Y[i,0])
ax3.plot_surface(X, Y, Z, rstride = 1, cstride = 1, cmap='rainbow', alpha=0.25)
ax3.contour(X, Y, Z, offset=-1, cmap = 'rainbow')
ax3.plot(trajectory[0], trajectory[1], trajectory[2], "r--")
offset_data = -1*np.ones(len(trajectory[0]))
ax3.plot(trajectory[0], trajectory[1], offset_data,'k--')
ax3.set_title('Levenberg-Marquardt Method (Initial point [%.1f, %.1f])' %(trajectory[0][0], trajectory[1][0]))
ax3.set_xlabel("r_1")
ax3.set_ylabel("r_2")
ax3.set_zlabel("g")
file_name_prefix = "./Levenberg_Marquardt"
file_extension = ".png"
file_name = f"{file_name_prefix}_{trajectory[0][0]}_{trajectory[1][0]}{file_extension}"
print(file_name)
plt.draw()
plt.savefig(file_name)
if __name__ == "__main__":
test_data = np.array([[4.9, 3.9], [-2.9, 1.9], [0.1, -0.1], [-0.1, 0.1], [0,-3.8],[1,2.5], [0,0]], dtype=object)
for inital_data in test_data:
print("\nInitial point:")
print(inital_data)
x_1 = inital_data[0]
x_2 = inital_data[1]
epsilon_1 = 1e-6
epsilon_2 = 1e-5
max_iter = 1000
trajectory = levenberg_marquardt_method(x_1, x_2, epsilon_1, epsilon_2, max_iter)
result_plot(trajectory)
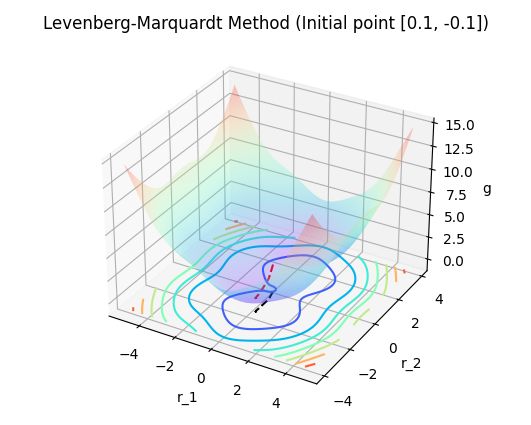
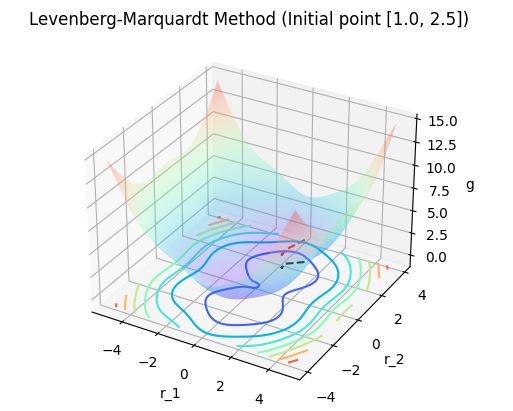
3. 结果显示
| 测试显示 | 测试显示 |
|---|---|
 |
 |
 |
 |
 |
 |
4. 结论
此处结果显示对比非线性最小二乘问题的数值方法 —— 从牛顿迭代法到高斯-牛顿法 (实例篇 V) 中应用高斯-牛顿法得到的结果显示可以看出,
- 列文伯格-马夸尔特法逐步收敛于极小值点的过程, 迭代步更加平滑, 较少振荡;
- 高斯-牛顿法在迭代过程中有点 “横冲直撞” 的意味.
所以列文伯格-马夸尔特法在实际中应用更广,
但高斯-牛顿法是后面这些更优方法的源头.