Java多线程和线程池详解
多线程
1. 线程的声明周期
- 新建 :从新建一个线程对象到程序start() 这个线程之间的状态,都是新建状态;
- 就绪 :线程对象调用start()方法后,就处于就绪状态,等到JVM里的线程调度器的调度;
- 运行 :就绪状态下的线程在获取CPU资源后就可以执行run(),此时的线程便处于运行状态,运行状态的线程可变为就绪、阻塞及死亡三种状态。
- 等待/阻塞/睡眠 :在一个线程执行了sleep(睡眠)、suspend(挂起)等方法后会失去所占有的资源,从而进入阻塞状态,在睡眠结束后可重新进入就绪状态。
- 终止 :run()方法完成后或发生其他终止条件时就会切换到终止状态。
2. 线程的创建方法
2.1 继承Thread类
实现步骤:
- 定义类继承Thread
- 重写Thread类中的run方法
- 调用线程的start方法
public class ThreadDemo1 {
public static void main(String[] args) {
//创建两个线程
ThreadDemo td = new ThreadDemo("zhangsan");
ThreadDemo tt = new ThreadDemo("lisi");
//执行多线程特有方法,如果使用td.run();也会执行,但会以单线程方式执行。
td.start();
tt.start();
//主线程
for (int i = 0; i < 5; i++) {
System.out.println("main" + ":run" + i);
}
}
}
//继承Thread类
class ThreadDemo extends Thread{
//设置线程名称
ThreadDemo(String name){
super(name);
}
//重写run方法。
public void run(){
for(int i = 0; i < 5; i++){
//currentThread() 获取当前线程对象(静态)。 getName() 获取线程名称。
System.out.println(this.getName() + ":run" + i);
}
}
}
2.2 实现Runnable接口
接口应该由那些打算通过某一线程执行其实例的类来实现。类必须定义一个称为run 的无参方法。
实现步骤:
- 定义类实现
Runnable接口 - 覆盖
Runnable接口中的run方法 - 通过Thread类建立线程对象
- 将
Runnable接口的子类对象作为实际参数传递给Thread类的构造函数。 - 调用Thread类的start方法开启线程并调用Runnable接口子类的run方法。
public class RunnableDemo {
public static void main(String[] args) {
RunTest rt = new RunTest();
//建立线程对象
Thread t1 = new Thread(rt);
Thread t2 = new Thread(rt);
//开启线程并调用run方法。
t1.start();
t2.start();
}
}
//定义类实现Runnable接口
class RunTest implements Runnable{
private int tick = 10;
//覆盖Runnable接口中的run方法,并将线程要运行的代码放在该run方法中。
public void run(){
while (true) {
if(tick > 0){
System.out.println(Thread.currentThread().getName() + "..." + tick--);
}
}
}
}
2.3 通过Callable和Future创建线程
实现步骤:
- 创建Callable接口的实现类,并实现call()方法,改方法将作为线程执行体,且具有返回值。
- 创建Callable实现类的实例,使用FutureTask类进行包装Callable对象,FutureTask对象封装了Callable对象的call()方法的返回值
- 使用FutureTask对象作为Thread对象启动新线程。
- 调用FutureTask对象的get()方法获取子线程执行结束后的返回值。
public class CallableFutrueTest {
public static void main(String[] args) {
CallableTest ct = new CallableTest(); //创建对象
//使用FutureTask包装CallableTest对象
FutureTask<Integer> ft = new FutureTask<Integer>(ct);
for(int i = 0; i < 100; i++){
//输出主线程
System.out.println(Thread.currentThread().getName() + "主线程的i为:" + i);
//当主线程执行第30次之后开启子线程
if(i == 30){
Thread td = new Thread(ft,"子线程");
td.start();
}
}
//获取并输出子线程call()方法的返回值
try {
System.out.println("子线程的返回值为" + ft.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
class CallableTest implements Callable<Integer>{
//复写call() 方法,call()方法具有返回值
public Integer call() throws Exception {
int i = 0;
for( ; i<100; i++){
System.out.println(Thread.currentThread().getName() + "的变量值为:" + i);
}
return i;
}
}
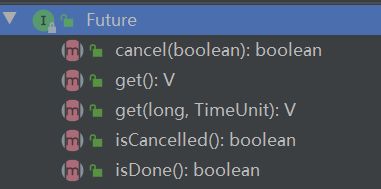
2.3.1 拓展——Future和FutureTask是什么
从源码看Future是一个接口,文档说得很清楚,里面定义了获得异步计算结果的方法,如图
而FutureTask是一个具体类,继承实现关系如下:
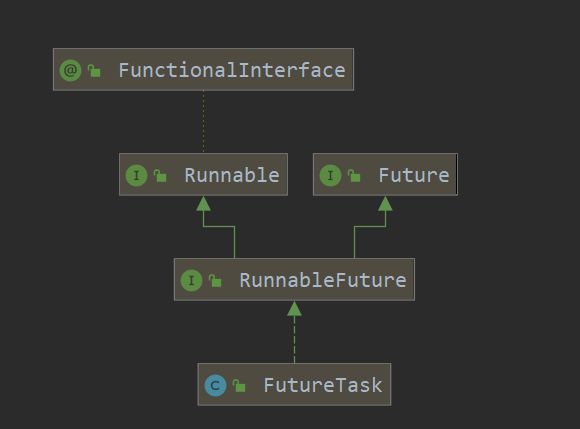
它实现了Future接口和Runnable接口,其中Runnable接口应该不陌生,它是线程创建的默认接口。而Future接口提供了获取返回值的必要方法。那么,它和Callable接口有什么关系呢?
直接看源码
public class FutureTask<V> implements RunnableFuture<V> {
/**
* The run state of this task, initially NEW. The run state
* transitions to a terminal state only in methods set,
* setException, and cancel. During completion, state may take on
* transient values of COMPLETING (while outcome is being set) or
* INTERRUPTING (only while interrupting the runner to satisfy a
* cancel(true)). Transitions from these intermediate to final
* states use cheaper ordered/lazy writes because values are unique
* and cannot be further modified.
*
* Possible state transitions:
* NEW -> COMPLETING -> NORMAL
* NEW -> COMPLETING -> EXCEPTIONAL
* NEW -> CANCELLED
* NEW -> INTERRUPTING -> INTERRUPTED
*/
private volatile int state;
private static final int NEW = 0;
private static final int COMPLETING = 1;
private static final int NORMAL = 2;
private static final int EXCEPTIONAL = 3;
private static final int CANCELLED = 4;
private static final int INTERRUPTING = 5;
private static final int INTERRUPTED = 6;
/** The underlying callable; nulled out after running */
private Callable<V> callable;
//.....省略很多方法
public void run() {
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call(); //这里返回了结果
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);//这里传送出去
}
} finally {
//....
}
}
}
看到下方private Callable可以直观地了解到FutureTask是通过聚合Callable变量和重写run方法的方式对Runnable进行了增强
2.4 三种方法的对比
| 方法 | 优势 | 劣势 |
|---|---|---|
| 继承Thread | 编写简单,可直接用this.getname()获取当前线程,不必使用Thread.currentThread()方法。 |
已经继承了Thread类,无法再继承其他类。 |
| 实现Runnable | 避免了单继承的局限性、多个线程可以共享一个target对象,非常适合多线程处理同一份资源的情形。 | 比较复杂、访问线程必须使用Thread.currentThread()方法、无返回值。 |
| 实现Callable | 有返回值、避免了单继承的局限性、多个线程可以共享一个target对象,非常适合多线程处理同一份资源的情形。 | 比较复杂、访问线程必须使用Thread.currentThread()方法 |
线程池
1. 线程池的优势
总体来说,线程池有如下的优势:
(1)降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
(2)提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
(3)提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
2. 线程池的使用
线程池的真正实现类是ThreadPoolExecutor,其构造方法有如下4种:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
可以看到,其需要如下几个参数:
-
corePoolSize(必需):核心线程数。默认情况下,核心线程会一直存活,但是当将allowCoreThreadTimeout设置为true时,核心线程也会超时回收。 -
maximumPoolSize(必需):线程池所能容纳的最大线程数。当活跃线程数达到该数值后,后续的新任务将会阻塞。 -
keepAliveTime(必需):线程闲置超时时长。如果超过该时长,非核心线程就会被回收。如果将allowCoreThreadTimeout设置为true时,核心线程也会超时回收。 -
unit(必需):指定keepAliveTime参数的时间单位。常用的有:TimeUnit.MILLISECONDS(毫秒)、TimeUnit.SECONDS(秒)、TimeUnit.MINUTES(分)。 -
workQueue(必需):任务队列。通过线程池的execute()方法提交的Runnable对象将存储在该参数中。其采用阻塞队列实现。 -
threadFactory(可选):线程工厂。用于指定为线程池创建新线程的方式。 -
handler(可选):拒绝策略。当达到最大线程数时需要执行的饱和策略。
线程池的使用流程如下:
// 创建线程池
Executor threadPool = new ThreadPoolExecutor(CORE_POOL_SIZE,
MAXIMUM_POOL_SIZE,
KEEP_ALIVE,
TimeUnit.SECONDS,
sPoolWorkQueue,
sThreadFactory);
// 向线程池提交任务
threadPool.execute(new Runnable() {
@Override
public void run() {
... // 线程执行的任务
}
});
// 关闭线程池
threadPool.shutdown(); // 设置线程池的状态为SHUTDOWN,然后中断所有没有正在执行任务的线程
threadPool.shutdownNow(); // 设置线程池的状态为 STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表
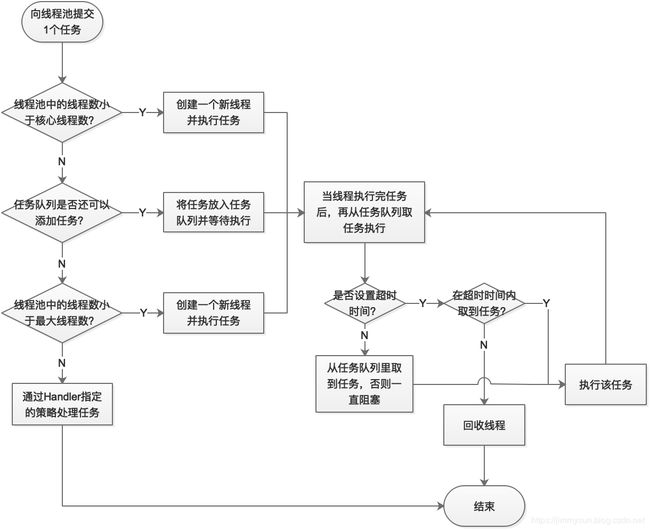
3. 线程池的工作原理
下面来描述一下线程池工作的原理,同时对上面的参数有一个更深的了解。其工作原理流程图如下:
4. 线程池的参数
4.1 任务队列(workQueue)
任务队列是基于阻塞队列实现的,即采用生产者消费者模式,在Java中需要实现BlockingQueue接口。但Java已经为我们提供了7种阻塞队列的实现:
ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列(数组结构可配合指针实现一个环形队列)。LinkedBlockingQueue: 一个由链表结构组成的有界阻塞队列,在未指明容量时,容量默认为Integer.MAX_VALUE。PriorityBlockingQueue: 一个支持优先级排序的无界阻塞队列,对元素没有要求,可以实现Comparable接口也可以提供Comparator来对队列中的元素进行比较。跟时间没有任何关系,仅仅是按照优先级取任务。DelayQueue:类似于PriorityBlockingQueue,是二叉堆实现的无界优先级阻塞队列。要求元素都实现Delayed接口,通过执行时延从队列中提取任务,时间没到任务取不出来。SynchronousQueue: 一个不存储元素的阻塞队列,消费者线程调用take()方法的时候就会发生阻塞,直到有一个生产者线程生产了一个元素,消费者线程就可以拿到这个元素并返回;生产者线程调用put()方法的时候也会发生阻塞,直到有一个消费者线程消费了一个元素,生产者才会返回。LinkedBlockingDeque: 使用双向队列实现的有界双端阻塞队列。双端意味着可以像普通队列一样FIFO(先进先出),也可以像栈一样FILO(先进后出)。LinkedTransferQueue: 它是ConcurrentLinkedQueue、LinkedBlockingQueue和SynchronousQueue的结合体,但是把它用在ThreadPoolExecutor中,和LinkedBlockingQueue行为一致,但是是无界阻塞队列。
注意有界队列和无界队列的区别:如果使用有界队列,当队列饱和时并超过最大线程数时就会执行拒绝策略;而如果使用无界队列,因为任务队列永远都可以添加任务,所以设置maximumPoolSize没有任何意义。
4.2 线程工厂(threadFactory)
线程工厂指定创建线程的方式,需要实现ThreadFactory接口,并实现newThread(Runnable r)方法。该参数可以不用指定,Executors框架已经为我们实现了一个默认的线程工厂:
/**
* The default thread factory.
*/
private static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
4.3 拒绝策略
当线程池的线程数达到最大线程数时,需要执行拒绝策略。拒绝策略需要实现RejectedExecutionHandler接口,并实现rejectedExecution(Runnable r, ThreadPoolExecutor executor)方法。不过Executors框架已经为我们实现了4种拒绝策略:
AbortPolicy(默认):丢弃任务并抛出RejectedExecutionException异常。CallerRunsPolicy:由调用线程处理该任务。DiscardPolicy:丢弃任务,但是不抛出异常。可以配合这种模式进行自定义的处理方式。DiscardOldestPolicy:丢弃队列最早的未处理任务,然后重新尝试执行任务。
5. 功能线程池
嫌上面使用线程池的方法太麻烦?其实Executors已经为我们封装好了4种常见的功能线程池,如下:
- 定长线程池(
FixedThreadPool) - 定时线程池(
ScheduledThreadPool) - 可缓存线程池(
CachedThreadPool) - 单线程化线程池(
SingleThreadExecutor)
5.1 定长线程池(FixedThreadPool)
创建方法的源码:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
- 特点:只有核心线程,线程数量固定,执行完立即回收,任务队列为链表结构的有界队列。
- 应用场景:控制线程最大并发数。
使用示例:
// 1. 创建定长线程池对象 & 设置线程池线程数量固定为3
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
// 2. 创建好Runnable类线程对象 & 需执行的任务
Runnable task =new Runnable(){
public void run() {
System.out.println("执行任务啦");
}
};
// 3. 向线程池提交任务
fixedThreadPool.execute(task);
5.2 定时线程池(ScheduledThreadPool)
创建方法源码:
private static final long DEFAULT_KEEPALIVE_MILLIS = 10L;
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE,
DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,
new DelayedWorkQueue());
}
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE,
DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,
new DelayedWorkQueue(), threadFactory);
}
- 特点:核心线程数量固定,非核心线程数量无限,执行完闲置10ms后回收,任务队列为延时阻塞队列。
- 应用场景:执行定时或周期性的任务
使用示例:
// 1. 创建 定时线程池对象 & 设置线程池线程数量固定为5
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);
// 2. 创建好Runnable类线程对象 & 需执行的任务
Runnable task =new Runnable(){
public void run() {
System.out.println("执行任务啦");
}
};
// 3. 向线程池提交任务
scheduledThreadPool.schedule(task, 1, TimeUnit.SECONDS); // 延迟1s后执行任务
scheduledThreadPool.scheduleAtFixedRate(task,10,1000,TimeUnit.MILLISECONDS);// 延迟10ms后、每隔1000ms执行任务
5.3 可缓存线程池(CachedThreadPool)
创建方法源码:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
- 特点:无核心线程,非核心线程数量无限,执行完闲置60s后回收,任务队列为不存储元素的阻塞队列。
- 应用场景:执行大量、耗时少的任务。
使用示例:
// 1. 创建可缓存线程池对象
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
// 2. 创建好Runnable类线程对象 & 需执行的任务
Runnable task =new Runnable(){
public void run() {
System.out.println("执行任务啦");
}
};
// 3. 向线程池提交任务
cachedThreadPool.execute(task);
5.4 单线程化线程池(SingleThreadExecutor)
创建方法的源码:
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
- 特点:只有1个核心线程,无非核心线程,执行完立即回收,任务队列为链表结构的有界队列。
- 应用场景:不适合并发但可能引起IO阻塞性及影响UI线程响应的操作,如数据库操作、文件操作等。
使用示例:
// 1. 创建单线程化线程池
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
// 2. 创建好Runnable类线程对象 & 需执行的任务
Runnable task =new Runnable(){
public void run() {
System.out.println("执行任务啦");
}
};
// 3. 向线程池提交任务
singleThreadExecutor.execute(task);
5.5 对比
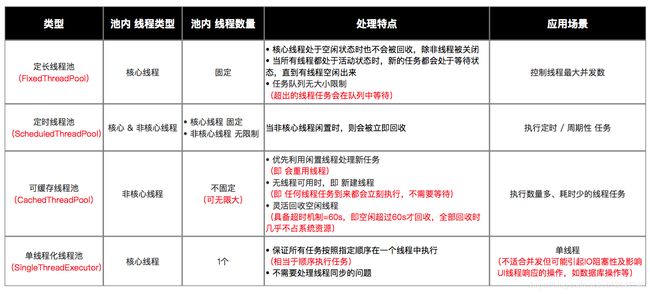
Executors的4个功能线程池虽然方便,但现在已经不建议使用了,而是建议直接通过使用ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
其实Executors的4个功能线程有如下弊端:
FixedThreadPool和SingleThreadExecutor:主要问题是堆积的请求处理队列均采用LinkedBlockingQueue,可能会耗费非常大的内存,甚至OOM。CachedThreadPool和ScheduledThreadPool:主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM。
最佳用例
public static void main(String[] args) {
final int[][] testNumber = {{1,100000},{100001,200000},{200001,300000},{300001,400000},{400001,500000},{500001,600000}};
ThreadPoolExecutor threadPool = (ThreadPoolExecutor)Executors.newFixedThreadPool(6);
List<Future<Long>> futureList = new ArrayList<>();
for(int i = 0;i < 6;i++){
Future<Long> future = threadPool.submit(new CallableTest(testNumber[i][0], testNumber[i][1]));
futureList.add(future);
}
Long num = 0L;
Long startTime = System.currentTimeMillis();
do {
for(int i = 0;i < futureList.size();i++){
Future<Long> future = futureList.get(i);
System.out.printf("Task %d : %s \n",i,future.isDone());
}
}while (threadPool.getCompletedTaskCount() < futureList.size());
for (Future<Long> future : futureList) {
try {
num += future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
Long endTime = System.currentTimeMillis();
System.out.println("用时:"+(endTime-startTime)+"ms");
System.out.println(num);
threadPool.shutdown();
}
面试题
1 调用两次start会发生什么
首先我们来看源码
public synchronized void start() {
/**
* This method is not invoked for the main method thread or "system"
* group threads created/set up by the VM. Any new functionality added
* to this method in the future may have to also be added to the VM.
*
* A zero status value corresponds to state "NEW".
*/
if (threadStatus != 0)
throw new IllegalThreadStateException();
/* Notify the group that this thread is about to be started
* so that it can be added to the group's list of threads
* and the group's unstarted count can be decremented. */
group.add(this);
boolean started = false;
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
/* do nothing. If start0 threw a Throwable then
it will be passed up the call stack */
}
}
}
结论很明显,会抛出IllegalThreadStateException异常,线程创建时,会有一个初始状态status对应创建,就绪,阻塞,等待,运行,终止等不同的状态,如果想重复start,会先去检查这个状态,如果不是初始值,就会报错
2 直接调用run会发生什么
@Override
public void run() {
if (target != null) {
target.run();
}
}
还是看上面两个的源码,首先看run(),让当前Tjhread直接调用run方法,没有经过start方法,如果有线程池,不能添加到线程池中;
run()方法只是类中的一个方法,直接调用run()方法,那还是一个主线程,执行完第一个run()在执行下一个调用的run(),是个单线程;
start()是创建了一个线程,使新线程运行Thread类的run()方法里面的代码,而主线程继续,实现了多线程,
3 execute和submit的区别
从源码来看
//-----------------------------submit
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
//----------------------------execute
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
//看线程池的工作原理 上面线程池->3.线程池的工作原理
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
- submit不管是Runnable还是Callable类型的任务都可以接受,而且都返回了
Future - execute只支持Runnable类型,而且返回值为
null - 但是他们实际上都调用了execute方法,不同的时
submit做了RunnableFuture方法ftask = newTaskFor(...)
从异常来看
都会抛出空指针异常,或者根据拒绝策略返回
4 怎么确认线程数
- IO密集型:因为阻塞,所以可以两倍甚至更多
- 计算密集型:最好和cpu线程数相当
Java 确定线程池中工作线程数的大小
5 happen-before
[Chapter 17 of the Java Language Specification] defines the happens-before relation on memory operations such as reads and writes of shared variables.The results of a write by one thread are guaranteed to be visible to a read by another thread only if the write operation happens-before the read operation. The synchronized and volatile constructs, as well as the Thread.start() and Thread.join() methods, can form happens-before relationships. In particular:
· Each action in a thread happens-before every action in that thread that comes later in the program's order.
· An unlock (synchronized block or method exit) of a monitor happens-before every subsequent lock (synchronized block or method entry) of that same monitor. And because the happens-before relation is transitive, all actions of a thread prior to unlocking happen-before all actions subsequent to any thread locking that monitor.
· A write to a volatile field happens-before every subsequent read of that same field. Writes and reads of volatile fields have similar memory consistency effects as entering and exiting monitors, but do not entail mutual exclusion locking.
· A call to start on a thread happens-before any action in the started thread.
· All actions in a thread happen-before any other thread successfully returns from a join on that thread.
渣翻一下:
happens-before其实有两种不同的解释,一种是多线程情况下对共享变量的内存操作(例如读写)问题说明(请看)(如果写操作发生在读操作前,那么必须保证一个线程的写操作在另一个线程的读操作之前可见);另一种是synchronized和volatile关键字修饰的区域,还有Thread.start()和Thread.join()方法也遵循happens-before的关系
- 同一个线程中所有的代码都是顺序执行的(ActionA和ActionB属于同一个线程,且ActionA在前,ActionA happens-before ActionB)
- 对于同一个
monitor监视器的对象,它的解锁unlock(包括synchronized修饰的代码块或方法退出)操作happens-before之后的加锁lock(包括synchronized修饰的代码块或方法进入同步区域)操作。而且因为happens-before具有可传递性,对于同一个monitor监视器的对象,线程对它的所有解锁操作优先于其他线程对它进行的加锁操作 - 对于同一个
volatile修饰的变量,在对它进行读操作之前,之前发生的所有写操作必须完成。 - 线程的
start方法优先于线程的其他方法 - 在
join方法之前,这个线程的所有动作都已经发生,这样其他线程才能成功接收到join的返回
引用
Java多线程:彻底搞懂线程池