字典嵌套列表 与 列表嵌套字典 导出为csv 的方法
字典嵌套列表 导出csv
{'rank': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30'], 'school_name': ['清华大学', '北京大学', '浙江大学', '上海交通大学', '复旦大学', '南京大学', '中国科学技术大学', '华中科技大学', '武汉大学', '西安交通大学', '四川大学', '中山大学', '哈尔滨工业大学', '同济大学', '北京航空航天大学', '东南大学', '北京师范大学', '北京理工大学', '中国人民大学', '南开大学', '天津大学', '山东大学', '中南大学', '西北工业大学', '华南理工大学', '厦门大学', '吉林大学', '华东师范大学', '中国农业大学', '电子科技大学'], 'school_position': ['北京', '北京', '浙江', '上海', '上海', '江苏', '安徽', '湖北', '湖北', '陕西', '四川', '广东', '黑龙江', '上海', '北京', '江苏', '北京', '北京', '北京', '天津', '天津', '山东', '湖南', '陕西', '广东', '福建', '吉林', '上海', '北京', '四川'], 'school_sum': ['999.4', '912.5', '825.3', '783.3', '697.8', '683.4', '609.9', '609.3', '607.1', '570.2', '561.7', '559.4', '549.8', '548.4', '546.7', '538.5', '534.7', '530.9', '514.7', '497.4', '490.8', '484.3', '475.8', '467.9', '466.7', '458.8', '450.3', '440.7', '433.7', '432.0'], 'school_level': ['37.6', '34.4', '34.1', '35.5', '35.9', '37.7', '40.0', '32.3', '32.8', '34.2', '32.0', '31.4', '32.7', '32.8', '33.2', '34.9', '34.6', '33.1', '34.2', '31.3', '33.0', '29.2', '30.7', '32.7', '30.8', '33.7', '31.2', '32.6', '31.9', '32.3']}
import csv
date={ 'rank':['1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16','17','18','19','20','21','22','23','24','25','26','27','28','29','30'],'school_position':['北京','北京','浙江','上海','上海','江苏','安徽','湖北','湖北','陕西','四川','广东','黑龙江','上海','北京','江苏','北京','北京','北京','天津','天津','山东','湖南','陕西','广东','福建','吉林','上海','北京','四川'],'school_sum':['999.4','912.5','825.3','783.3','697.8','683.4','609.9','609.3','607.1','570.2','561.7','559.4','549.8','548.4','546.7','538.5','534.7','530.9','514.7','497.4','490.8','484.3','475.8','467.9','466.7','458.8','450.3','440.7','433.7','432.0'] }
with open('F:/zly1.csv','w',encoding='utf8', newline='') as f:
w = csv.writer(f)
fieldnames=['排名', '学校名称', '学校地点', '办学总分', '办学层级']
# fieldnames=data.keys() 以字典原有键作为表头
w.writerow(fieldnames)
for x,y,z,m,n in zip(data['rank'],data['school_name'],data['school_sum'],data['school_position'],data['school_level']):
# w.writerow([x, y,z,m,n])
for x in zip(*date.values()):
print(x)
w.writerow([*x]) # 可改为 w.writerows([x])第二种方法 with open 同上
fieldnames=['排名','学校名称','学校地点','办学总分','办学层级']
# fieldnames=data.keys() #以字典原有键作为表头
if fieldnames is not None:
item = [str(i) for i in fieldnames]
f.write(','.join(item) + "\n")
for item in zip(*data.values()):
item = [str(i) for i in item]
f.write(','.join(item) + "\n")第三种:pandas库
a=pandas.DataFrame(data)
lables=['排名','学校名称','学校地点','办学总分','办学层级']
a.to_csv('F:/zly.csv',header=lables,sep=',',index=False,encoding='utf8')在与zip(…)结合使用时,writerow是单行写入,将一个列表全部写入csv的同一行,
而writerows则可多行写入,将一个二维列表的每一个列表写为一行
列表嵌套字典导出csv
# coding:utf-8
date=[{'大学排名': '1', '大学名称': '清华大学 ', '省市': '北京', '类型': '综合', '总分': '852.5'}, {'大学排名': '2', '大学名称': '北京大学 ', '省市': '北京', '类型': '综合', '总分': '746.7'}, {'大学排名': '3', '大学名称': '浙江大学 ', '省市': '浙江', '类型': '综合', '总分': '649.2'}, {'大学排名': '4', '大学名称': '上海交通大学 ', '省市': '上海', '类型': '综合', '总分': '625.9'}, {'大学排名': '5', '大学名称': '南京大学 ', '省市': '江苏', '类型': '综合', '总分': '566.1'}, {'大学排名': '6', '大学名称': '复旦大学 ', '省市': '上海', '类型': '综合', '总分': '556.7'}, {'大学排名': '7', '大学名称': '中国科学技术大学 ', '省市': '安徽', '类型': '理工', '总分': '526.4'}, {'大学排名': '8', '大学名称': '华中科技大学 ', '省市': '湖北', '类型': '综合', '总分': '497.7'}, {'大学排名': '9', '大学名称': '武汉大学 ', '省市': '湖北', '类型': '综合', '总分': '488.0'}, {'大学排名': '10', '大学名称': '中山大学 ', '省市': '广东', '类型': '综合', '总分': '457.2'}, {'大学排名': '11', '大学名称': '西安交通大学 ', '省市': '陕西', '类型': '综合', '总分': '452.5'}, {'大学排名': '12', '大学名称': '哈尔滨工业大学 ', '省市': '黑龙江', '类型': '理工', '总分': '450.2'}, {'大学排名': '13', '大学名称': '北京航空航天大学 ', '省市': '北京', '类型': '理工', '总分': '445.1'}, {'大学排名': '14', '大学名称': '北京师范大学 ', '省市': '北京', '类型': '师范', '总分': '440.9'}, {'大学排名': '15', '大学名称': '同济大学 ', '省市': '上海', '类型': '理工', '总分': '439.0'}, {'大学排名': '16', '大学名称': '四川大学 ', '省市': '四川', '类型': '综合', '总分': '435.7'}, {'大学排名': '17', '大学名称': '东南大学 ', '省市': '江苏', '类型': '综合', '总分': '432.7'}, {'大学排名': '18', '大学名称': '中国人民大学 ', '省市': '北京', '类型': '综合', '总分': '409.7'}, {'大学排名': '19', '大学名称': '南开大学 ', '省市': '天津', '类型': '综合', '总分': '402.1'}, {'大学排名': '20', '大学名称': '北京理工大学 ', '省市': '北京', '类型': '理工', '总分': '395.6'}, {'大学排名': '21', '大学名称': '天津大学 ', '省市': '天津', '类型': '理工', '总分': '390.3'}, {'大学排名': '22', '大学名称': '山东大学 ', '省市': '山东', '类型': '综合', '总分': '387.9'}, {'大学排名': '23', '大学名称': '厦门大学 ', '省市': '福建', '类型': '综合', '总分': '383.3'}, {'大学排名': '24', '大学名称': '吉林大学 ', '省市': '吉林', '类型': '综合', '总分': '379.5'}, {'大学排名': '25', '大学名称': '华南理工大学 ', '省市': '广东', '类型': '理工', '总分': '379.4'}, {'大学排名': '26', '大学名称': '中南大学 ', '省市': '湖南', '类型': '综合', '总分': '378.6'}, {'大学排名': '27', '大学名称': '大连理工大学 ', '省市': '辽宁', '类型': '理工', '总分': '365.1'}, {'大学排名': '28', '大学名称': '西北工业大学 ', '省市': '陕西', '类型': '理工', '总分': '359.6'}]
with open('F:/zly1.csv','w',encoding='utf8', newline='') as f:
w = csv.writer(f)
# for x, y,z,m,n in zip(data['rank'],data['school_name'],data['school_sum'],data['school_position'],data['school_level']):
# w.writerow([x, y,z,m,n])
w.writerow(date[0].keys())
for x in date:
w.writerow(x.values())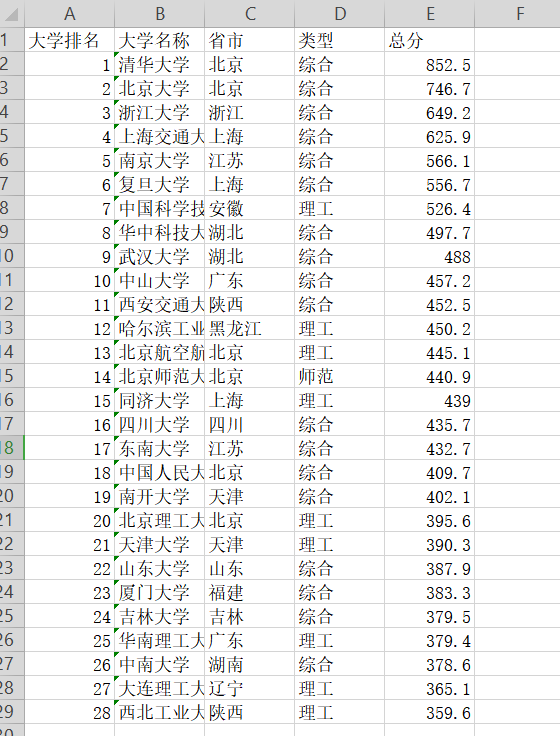
^(* ̄(oo) ̄)^注:
如有导出csv有间隔性空行,可在with open中加入newline 参数
如有编解码 错误,可尝试在代码首行添加 # coding:utf-8