rancher和k8s接口地址
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux/Windows/Mac 机器上。容器镜像正成为一个新的标准化软件交付方式。为了能够获取到 Docker 容器的运行状态,用户可以通过 Docker 的 stats 命令获取到当前主机上运行容器的统计信息,可以查看容器的 CPU 利用率、内存使用量、网络 IO 总量以及磁盘 IO 总量等信息。
显然如果我们想对监控数据做存储以及可视化的展示,那么 docker 的 stats 是不能满足的。
为了解决 docker stats 的问题(存储、展示),谷歌开源的 cadvisor 诞生了,cadvisor 不仅可以搜集一台机器上所有运行的容器信息,还提供基础查询界面和 http 接口,方便其他组件如 Prometheus 进行数据抓取,或者 cAdvisor + influxDB + grafana 搭配使用。cAdvisor 可以对节点机器上的资源及容器进行实时监控和性能数据采集,包括 CPU 使用情况、内存使用情况、网络吞吐量及文件系统使用情况
监控原理
cAdvisor 使用 Go 语言开发,利用 Linux 的 cgroups 获取容器的资源使用信息,在 K8S 中集成在 Kubelet 里作为默认启动项,官方标配。
Docker 是基于 Namespace、Cgroups 和联合文件系统实现的
Cgroups 不仅可以用于容器资源的限制,还可以提供容器的资源使用率。不管用什么监控方案,底层数据都来源于 Cgroups
Cgroups 的工作目录 /sys/fs/cgroup 下包含了 Cgroups 的所有内容。Cgroups 包含了很多子系统,可以对 CPU,内存,PID,磁盘 IO 等资源进行限制和监控。
Heapster
Heapster 是容器集群监控和性能分析工具,天然的支持 Kubernetes 和 CoreOS。
Heapster 首先从 K8S Master 获取集群中所有 Node 的信息,然后通过这些 Node 上的 kubelet 获取有用数据,而 kubelet 本身的数据则是从 cAdvisor 得到。所有获取到的数据都被推到 Heapster 配置的后端存储中,并还支持数据的可视化。现在后端存储 + 可视化的方法,如 InfluxDB + grafana。
Heapster 可以收集 Node 节点上的 cAdvisor 数据,还可以按照 kubernetes 的资源类型来集合资源,比如 Pod、Namespace 域,可以分别获取它们的 CPU、内存、网络和磁盘的 metric。默认的 metric 数据聚合时间间隔是 1 分钟。
注意 :Kubernetes 1.11 不建议使用 Heapster,就 SIG Instrumentation 而言,这是为了转向新的 Kubernetes 监控模型的持续努力的一部分。仍使用 Heapster 进行自动扩展的集群应迁移到 metrics-server 和自定义指标 API。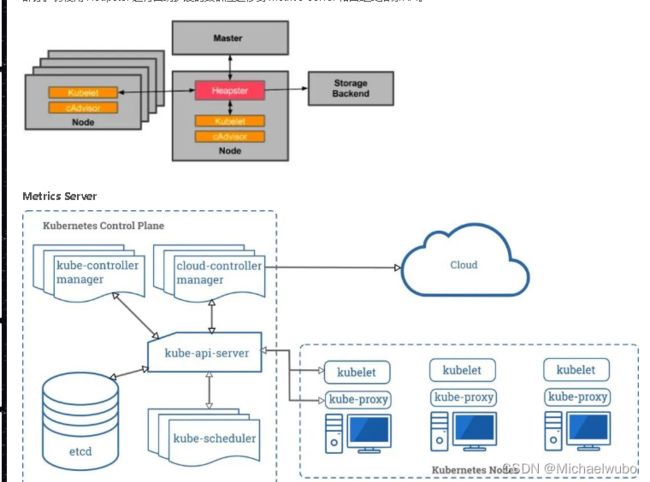
kubernetes 集群资源监控之前可以通过 heapster 来获取数据,在 1.11 开始开始逐渐废弃 heapster 了,采用 metrics-server 来代替,metrics-server 是集群的核心监控数据的聚合器,它从 kubelet 公开的 Summary API 中采集指标信息,metrics-server 是扩展的 APIServer,依赖于 kube-aggregator,因为我们需要在 APIServer 中开启相关参数。
Metrics Server 并不是 kube-apiserver 的一部分,而是通过 Aggregator 这种插件机制,在独立部署的情况下同 kube-apiserver 一起统一对外服务的。
Aggregator
通过聚合层扩展 Kubernetes API使用聚合层(Aggregation Layer),用户可以通过额外的 API 扩展 Kubernetes, 而不局限于 Kubernetes 核心 API 提供的功能。这里的附加 API 可以是现成的解决方案比如 metrics server, 或者你自己开发的 API。聚合层不同于 定制资源(Custom Resources)。后者的目的是让 kube-apiserver 能够认识新的对象类别(Kind)。
聚合层聚合层在 kube-apiserver 进程内运行。在扩展资源注册之前,聚合层不做任何事情。要注册 API,用户必须添加一个 APIService 对象,用它来“申领” Kubernetes API 中的 URL 路径。自此以后,聚合层将会把发给该 API 路径的所有内容(例如 /apis/myextension.mycompany.io/v1/…) 转发到已注册的 APIService。
APIService 的最常见实现方式是在集群中某 Pod 内运行 扩展 API 服务器。如果你在使用扩展 API 服务器来管理集群中的资源,该扩展 API 服务器(也被写成“extension-apiserver”) 一般需要和一个或多个控制器一起使用。apiserver-builder 库同时提供构造扩展 API 服务器和控制器框架代码。
这里,Aggregator APIServer 的工作原理,可以用如下所示的一幅示意图来表示清楚 :

因为 k8s 的 api-server 将所有的数据持久化到了 etcd 中,显然 k8s 本身不能处理这种频率的采集,而且这种监控数据变化快且都是临时数据,因此需要有一个组件单独处理他们,于是 metric-server 的概念诞生了。
Metrics server 出现后,新的 Kubernetes 监控架构将变成下图的样子
- 核心流程(黑色部分):这是 Kubernetes 正常工作所需要的核心度量,从 Kubelet、cAdvisor 等获取度量数据,再由 metrics-server 提供给 Dashboard、HPA 控制器等使用。
- 监控流程(蓝色部分):基于核心度量构建的监控流程,比如 Prometheus 可以从 metrics-server 获取核心度量,从其他数据源(如 Node Exporter 等)获取非核心度量,再基于它们构建监控告警系统。

注意:
-
metrics-sevrer 的数据存在内存中。
-
metrics-server 主要针对 node、pod 等的 cpu、网络、内存等系统指标的监控
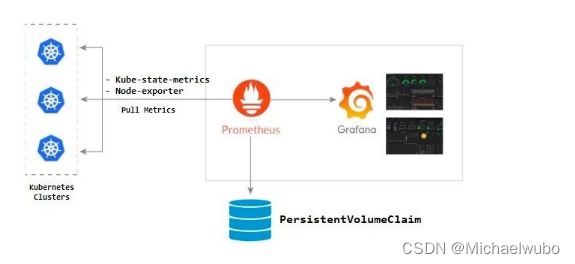
kube-state-metrics
已经有了 cadvisor、heapster、metric-server,几乎容器运行的所有指标都能拿到,但是下面这种情况却无能为力:
- 我调度了多少个 replicas?现在可用的有几个?
- 多少个 Pod 是 running/stopped/terminated 状态?
- Pod 重启了多少次?
- 我有多少 job 在运行中
而这些则是 kube-state-metrics 提供的内容,它基于 client-go 开发,轮询 Kubernetes API,并将 Kubernetes 的结构化信息转换为 metrics。
kube-state-metrics 与 metrics-server 对比
我们服务在运行过程中,我们想了解服务运行状态,pod 有没有重启,伸缩有没有成功,pod 的状态是怎么样的等,这时就需要 kube-state-metrics,它主要关注 deployment,、node 、 pod 等内部对象的状态。而 metrics-server 主要用于监测 node,pod 等的 CPU,内存,网络等系统指标。
- metric-server(或 heapster)是从 api-server 中获取 cpu、内存使用率这种监控指标,并把他们发送给存储后端,如 influxdb 或云厂商,他当前的核心作用是:为 HPA 等组件提供决策指标支持。
- kube-state-metrics 关注于获取 k8s 各种资源的最新状态,如 deployment 或者 daemonset,之所以没有把 kube-state-metrics 纳入到 metric-server 的能力中,是因为他们的关注点本质上是不一样的。metric-server 仅仅是获取、格式化现有数据,写入特定的存储,实质上是一个监控系统。而 kube-state-metrics 是将 k8s 的运行状况在内存中做了个快照,并且获取新的指标,但他没有能力导出这些指标
- 换个角度讲,kube-state-metrics 本身是 metric-server 的一种数据来源,虽然现在没有这么做。
- 另外,像 Prometheus 这种监控系统,并不会去用 metric-server 中的数据,他都是自己做指标收集、集成的(Prometheus 包含了 metric-server 的能力),但 Prometheus 可以监控 metric-server 本身组件的监控状态并适时报警,这里的监控就可以通过 kube-state-metrics 来实现,如 metric-serverpod 的运行状态。
1.k8s原生api地址
k8s的REST API:
http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/nodes
http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/nodes/
http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/namespace//pods/
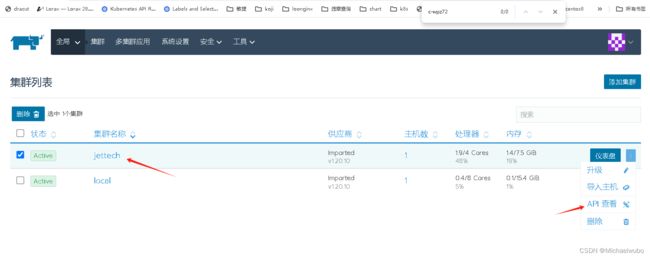
2.rancher看k8s接口地址
2.1)看集群的api
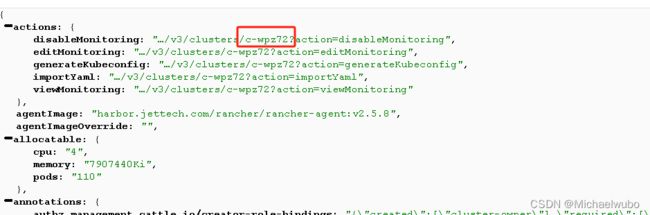
2.2)通过集群api查看id
2.3)通过rancher看k8s的api地址
rancher的REST API:
总接口:https://rancher.jettech.cn/k8s/clusters/c-wpz72/
node:https://rancher.jettech.cn/k8s/clusters/c-wpz72/apis/metrics.k8s.io/v1beta1/nodes
pod:https://rancher.jettech.cn/k8s/clusters/c-wpz72/apis/metrics.k8s.io/v1beta1/pods
细说k8s监控架构 - 知乎