pandas数据分析详细解读(一)
(一)Series对象
- 类似于一维数组
- 由一组数据以及与这种数据有管的标签(索引)组成

1.1创建series对象
- pd.Series(data,index=index)
import pandas as pd
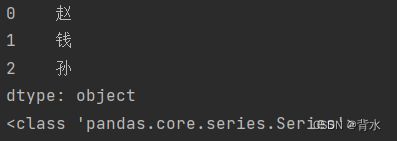
data=['赵','钱','孙']#数据为一维列表
s=pd.Series(data=data)#这里没有设置索引,默认为从0开始
print(s)
print(type(s))运行结果
下面是设置索引的
s=pd.Series(data=data,index=['a','b','c'])#设置索引为a,b,c
1.2Series索引操作
- 位置索引:索引范围[0,N-1]
- 标签索引:[索引名称],若获得多个[[标签名1],[标签名2],....]
- 切片索引:[start:stop:step]#开始:结束:步长
- 获取索引和值:s.index,s.values
import pandas as pd
data=['赵','钱','孙']#数据为一维列表
s=pd.Series(data=data)#设置索引为a,b,c
print(s[0])#位置索引,运行结果:赵
print(s[0:2])#结果:赵,钱import pandas as pd
data=['赵','钱','孙']#数据为一维列表
s=pd.Series(data=data,index=['a','b','c'])#设置索引为a,b,c
print(s['a':'b'])#标签索引,注意包括结束位置
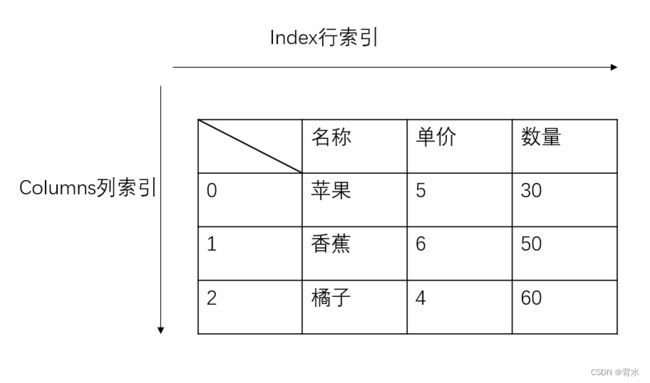
#结果:赵,钱(二)DataFrame对象
- 类似于二维表,由行和列组成
- 与Series一样支持多种数据类型
2.1创建DataFrame对象
- pd.DataFrame(data,index,columns,dtype)
#用列表创建
import pandas as pd
data=[['苹果',5,30],['香蕉',6,50],['橘子',4,60]]#第二维度列表代表一行
columns=['名称','数量','单价']#创建列索引
df=pd.DataFrame(data=data,columns=columns)
print(df)
#用字典创建
data={'名称':['苹果','香蕉','橘子'],#key为列索引,value为数据内容
'单价':[5,6,4],
'数量':[30,50,60]}
df=pd.DataFrame(data=data)
print(df)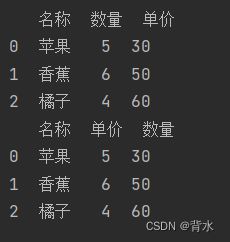
2.2DataFrame的重要属性
- 查看与修改索引
import pandas as pd
data=[['苹果',5,30],['香蕉',6,50],['橘子',4,60]]#第二维度列表代表一行
columns=['名称','数量','单价']#创建列索引
df=pd.DataFrame(data=data,columns=columns)
print(df)
print(df.index,'\n',df.columns)
df.columns=['you','are','good']#修改索引
print(df)
- 行列数据转换
import pandas as pd
data=[['苹果',5,30],['香蕉',6,50],['橘子',4,60]]
columns=['名称','数量','单价']
df=pd.DataFrame(data=data,columns=columns)
print(df)
new_df=df.T#相当于转置
print(new_df)
- 查看前后n条数据
print(df.head(n))#前n条
print(df.tail(n))#后n条
2.3DataFrame重要函数
- describe():查看每列的统计信息
- count():返回每一列非空数值个数
- sum():返回每一列的和
- max():返回每一列最大值
- min():返回每一列最小值
(三)导入Excel文件
- pd.read_excel(io,sheet_name,header)
- 常用参数说明
- io:表示文件路径
- sheet_name:表示工作表,取值如下
- header:默认值为0,取第一行的值为列名,数据为除列名以外的数据,如果数据不包含列名,则设置header=None
| 值 |
说明 |
| sheet_name=0 |
第一个sheet页中数据为对象 |
| sheet_name=1 |
第二个sheet页中数据为对象 |
| sheet_name=‘Sheet1’ |
名称为’Sheet1’的页数据为对象 |
| sheet_name=[0,1,’Sheet3’] |
第1、2和名称为Sheet3的页数据为对象 |
| Sheet_name=None |
读取所有工作表 |
- 导入一列数据
import pandas as pd
df=pd.read_excel('名称',sheet_name='工作表页',usecols=[1])#这里面useclos表示导入 列 按照索引导入
df=pd.read_excel('名称',sheet_name='工作表页',usecols=['姓名','成绩'])#这里面useclos表示导入 列 按照标签读取(四)数据提取
4.1:loc属性和iloc属性

- loc属性
- 以列名(cloumns)和行名(index)作为参数,当只有一个参数时,默认是行名,即抽取整数行数据,包括所有列。
- iloc属性
- 以行和列位置索引(即:0,1,2....)作为参数,0表示第一行,1表示第二行,以此类推。当只有一个参数时,默认是行索引,即抽取整行数据,包括所有列。
4.2按行提取
import pandas as pd
data=[[90,110,120],[100,115,115],[105,130,135]]
index=['张三','李四','王五']
columns=['语文','数学','英语']
df=pd.DataFrame(data=data,columns=columns,index=index)
print(df)print('______________________________')
print(df.loc['张三'])#行索引编号
print(df.iloc[0])#行索引名称
print('--------提取多行数据-------------')
print(df.loc[['张三','王五']])
print(df.iloc[[0,2]])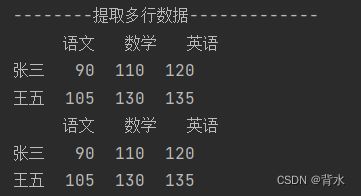
print('--------提取连续多行数据-----------')
print(df.loc['张三':'王五'])#包含王五
print(df.iloc[0:2])#不包含王五
4.3按列提取
print(df[['数学','英语']])#直接使用列名提取
print('-----------------------------')
print(df.loc[:,['数学','英语']])#逗号左侧表示的是行,右侧表示的是列
print(df.iloc[:,[1,2]])
print('---------提取连续列-----------')
print(df.loc[:,'语文':'英语'])
4.4提取区域数据
print('-----提取区域数据----------------')
print(df.loc['张三','数学'])
print(df.loc[['张三','王五'],['语文','数学']])
4.5提取指定条件数据
print(df['语文']>100)
print(df.loc[df['语文']>100])#loc默认是行索引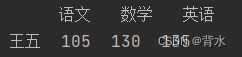
4.6注意事项
在Pandas中,使用df[]索引进行数据筛选和提取有以下几种常见用法:
-
使用单个列名或列名的列表:可以通过传递单个列名或列名的列表来选择一个或多个列。例如,
df['语文']选择了单个列,并返回一个Series对象,df[['语文', '数学']]选择了多个列,并返回一个新的DataFrame对象。 -
使用布尔索引:可以通过传递一个布尔索引来选择满足条件的行。布尔索引可以通过使用比较运算符(例如
>,<,==等)创建,或者通过使用逻辑运算符(例如&,|,~)进行组合。例如,df[df['语文'] > 100]返回满足“语文”列大于100的行。 -
使用切片:可以使用切片来选择一定范围内的行。切片使用行的位置进行索引。例如,
df[1:3]选择了索引为1和2的行(起始索引包含在内,结束索引不包含在内)。 -
需要注意的是,使用
df[]索引时,提取的是列数据而不是行数据。若要选择行数据,应该使用df.loc[]或df.iloc[]等方法
(五)增加数据
5.1按列直接赋值
5.1.1在,末尾加入
print('-----增加数据----------------')
df['物理']=[80,85,95]#直接赋值
print(df)
df.loc[:,'化学']=[75,85,90]
print(df)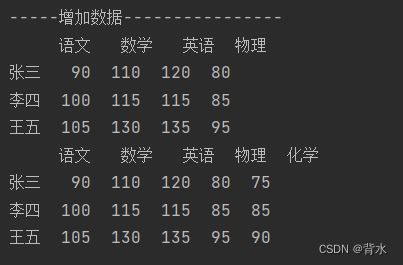
5.1.2在中间加入
list=[70,75,85]
df.insert(1,'历史',list)#在索引为1的位置加入历史
print(df)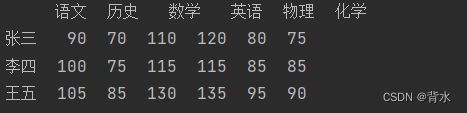
(六)数据清洗
6.1查看缺失值
import pandas as pd
# 创建包含缺失值的数据框
data = {'A': [1, 2, None, 4],
'B': [None, 6, 7, 8],
'C': [9, 10, 11, 12]}
df = pd.DataFrame(data)
print(df)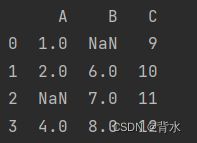
6.1.1使用info()函数
print(df.info())
6.1.2isnull()函数
print(df.isnull())#数据不为null时为False,为NUll时值为True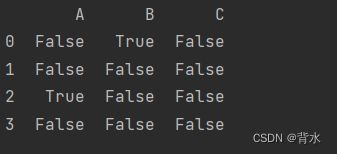
6.1.3notnull()函数
print(df.notnull())#数据为null时为False,不为NUll时值为True
6.2缺失值处理方式
6.2.1直接删除
6.2.1.1dropna()函数
使用dropna()函数(drop,nall的,有助记忆)
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)- axis:可选参数,表示删除行还是列。默认值为0,表示删除包含缺失值的行;设置为1表示删除包含缺失值的列。
- how:可选参数,表示删除的条件。默认值为’any’,表示只要存在一个缺失值就删除整行或整列;设置为’all’表示只有当整行或整列都是缺失值时才删除。
- thresh:可选参数,表示在删除之前需要满足的非缺失值的最小数量。如果行或列中的非缺失值数量小于等于thresh,则会被删除。
- subset:可选参数,用于指定要检查缺失值的特定列名或行索引。
- inplace:可选参数,表示是否对原始数据进行就地修改。默认值为False,表示不修改原始数据,而是返回一个新的数据框。
6.2.1.1删除含缺失值的行:
cleaned_df = df.dropna()
print(cleaned_df)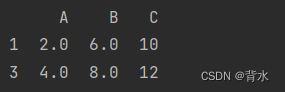
6.2.1.2删除缺失值的列:
cleaned_df = df.dropna(axis=1)
print(cleaned_df)
6.2.1.3只删除整行或整列都是缺失值的行或列
cleaned_df = df.dropna(how='all')
print(cleaned_df)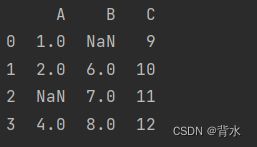
6.2.1.4至少需要2个非缺失值才保留行或列
cleaned_df = df.dropna(thresh=2)
cleaned_df6.2.1.5只在特定列中检查缺失值
cleaned_df = df.dropna(subset=['A', 'C'])
cleaned_df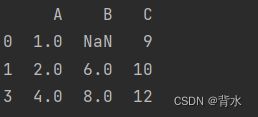
6.2.1.6在原始数据上进行就地修改
df.dropna(inplace=True)
print(df)6.2.1.7灵活处理
删除具体一列的缺失值(假设用来判断的列名称为’订单号‘):
new_de=df.loc[df['订单号'].notnull,:]#这里notnull返回值为True的保留,返回值为False的不保留
print(new_df)
#注意df['列名'].操作,最后返回的值按照行索引返回,所以行为True的都保留上面的实质为把缺失值删除,并将操作后的数据重新赋值给另一个变量。
6.2.2fillna()填充
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
6.2.2.1inplace参数
inplace参数的取值:True、False
True:直接修改原对象
False:创建一个副本,修改副本,原对象不变(缺省默认)6.2.2.2method参数
method参数的取值 : {‘pad’, ‘ffill’,‘backfill’,‘bfill’,None}, default None
pad/ffill:用前一个非缺失值去填充该缺失值
backfill/bfill:用下一个非缺失值填充该缺失值
None:指定一个值去替换缺失值(缺省默认这种方式)6.2.2.3用常数填充
import pandas as pd
# 创建包含缺失值的数据框
data = {'A': [1, 2, None, 4],
'B': [None, 6, 7, 8],
'C': [9, 10, 11, 12]}
df = pd.DataFrame(data)
print(df)
df.fillna(5,inplace=True)
print(df)
6.2.2.4用字典填充
da={'A':6,'B':7,'C':8}
df.fillna(da,inplace=True)
print(df)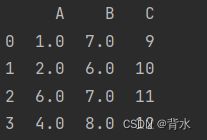
6.3查看重复值
6.3.1drop_duplicates与duplicated函数
- DataFrame.duplicated(subset=None,keep='first')
- DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
- subset:列标签,可选, 默认使用所有列,只考虑某些列来识别重复项传入列标签或者列标签的序列
- keep:{'first','last',False},默认'first'
first:删除除了第一次出现的重复项。
last:删除重复项,除了最后一次出现。
false:删除所有重复项
- inplace:是否替换原数据,默认是生成新的对象,可以复制到新的DataFrame,如果设置为True则乎替换原有数据,通常不建议设置为True
import pandas as pd
df = pd.DataFrame({
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
})
print(df)
print(df.duplicated())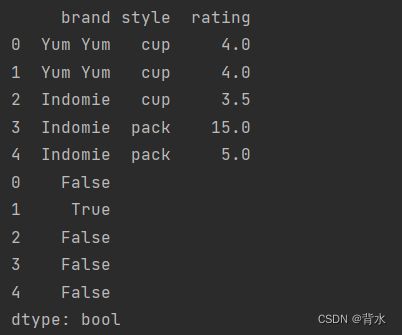
print(df.duplicated(subset=['brand','style']))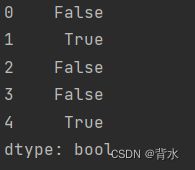
df=df.drop_duplicates(keep='last')
print(df)
- 注意:drop_duplicates函数操作后返回DataFrame类型,而duplicated函数操作后返回bool类型
参考资料:
[1]:pandas数据去重:drop_duplicates与duplicated函数 - 知乎 (zhihu.com)
[2]:【Kaggle】fillna()函数详解 - 知乎 (zhihu.com)
[3]:Python——Pandas——dropna()函数 - 知乎 (zhihu.com)