SDM: Sharing-enabled Disaggregated Memory System with Cache Coherent Compute Express Link——论文阅读
PACT 2023 Paper CXL论文阅读汇总
问题
分离式内存作为一种有望解决数据中心中内存容量扩展和更好利用内存资源的方案,已经引起了极大的关注。然而,可以同时实现高性能和用户透明度的分离式内存系统仍然不可用。尽管一些现代互连技术现在具有硬件一致性协议,可以潜在地实现在多个计算节点之间以用户透明的方式共享数据,但是将这些技术朴素地应用于分离式内存系统会导致非常大的性能开销。
为了应对内存墙的三个层次:设备层(HBM[44]和HMC[42])、模块层(NVM)、系统层(分布式存储器系统)
背景
分离式内存系统
分离式内存系统使用场景。分离式内存系统可以用作本地主内存的交换空间[5]、[21]、[36]、[37],也可以用作扩展的主内存池[2]、[10]、[17]、[22]、[32]、[34]、[40]、[46]。我们假设分离式内存系统是为了主内存池的扩展而构建的,因为这对性能和系统可靠性很有吸引力。
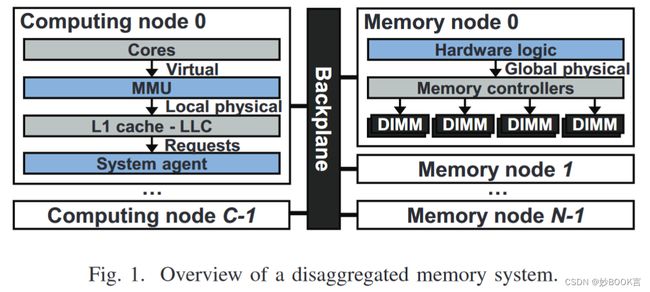
分离式内存系统的概览。如图1所示,分为三个部分:内存节点、背板和计算节点。内存节点由几个内存模块组成,具有简单的硬件逻辑,将事务请求转换为模块兼容的命令,反之亦然。从内存节点中去除处理器和存储能够降低内存节点的成本,从而实现更大的内存容量。背板将一个节点的请求或响应重定向到另一个节点。计算节点由基本硬件组件组成,运行用户应用程序。
分离式内存系统通常需要进行第二级页表遍历,将节点级地址翻译为系统级地址。如图1所示,内存管理单元(MMU)首先将虚拟地址翻译为本地物理地址,成为内存请求地址。一旦发生最后一级缓存(LLC)缺失,系统代理根据请求地址将LLC的内存请求多路复用到本地内存或背板。在背板中,第二级页表遍历将本地物理地址翻译为全局物理地址。然后,在检查访问权限标志后访问内存节点数据。
CXL
CXL中计算节点的一致性状态存储在专用的一致性目录中,该目录是特定于实现的。目录区域由CXL主代理和一致性桥(COHB)组件访问,两者都位于系统代理中。CXL不考虑瞬态一致性状态,因为在CXL中,组件一次只允许对给定缓存行地址发出一个嗅探,该组件必须等待收到嗅探响应后,才能发出对该地址的下一个嗅探。
类型1设备适用于完全一致的外部缓存设备或加速器。其只在CXL.cache通道上传输与缓存一致性相关的消息,不包含CXL.mem,因此,设备附加内存对该设备私有。在实际应用中,一些专用领域的加速器(例如NPU),主动使用主机数据的加速器可以制造成类型1设备。
类型2适用于设备附加内存完全一致而且对主机可见。主机可见内存被称为主机管理的设备内存,主机管理的设备内存通过CXL.mem访问,通过CXL.cache通道上的一致性状态和嗅探的交互消息进行访问。类型2设备在主机方面充当直接的数据提供者,例如,通过类型2设备可以避免在GPU和主机之间进行高成本的复制操作(例如,cudaMalloc)。
类型3设备用于扩展内存池。类型3设备仅包括主机管理的设备内存,通过CXL.mem通道访问。类型3具有类似于逻辑卷的特性,即多逻辑设备,它将内存设备分成16个隔离的逻辑区域,跨越不同进程的安全和隔离区域。最近,内存制造商已经宣布了基于类型3的内存扩展产品[45]、[47]。
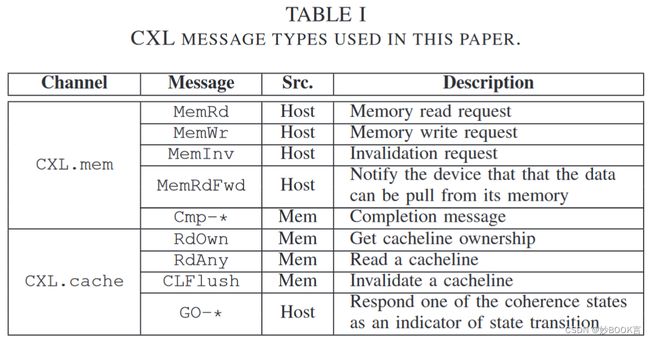
本文使用的CXL消息。如表I描所示,CXL定义的消息比表中的更多,我们只解释基线和提出的控制流所需的消息类型。第三列指示了每个消息类型的来源。表中提到的一致性状态是M(修改)、E(独占)、S(共享)和I(无效),与MESI协议相同。RdOwn和RdAny都是来自内存的读请求消息。对于Cmp-*和GO-*,“*”可以用一致性状态(即MESI)来重载,以指定缓存行的一致性状态。例如,在设备向主机发出RdOwn或RdAny后,设备将收到附带一致性状态的响应,这将是该设备中的一致性状态。根据CXL规范,不允许RdOwn接收GO-S(共享)的响应,而RdAny允许接收GO-I、GO-S、GO-E和GO-M。
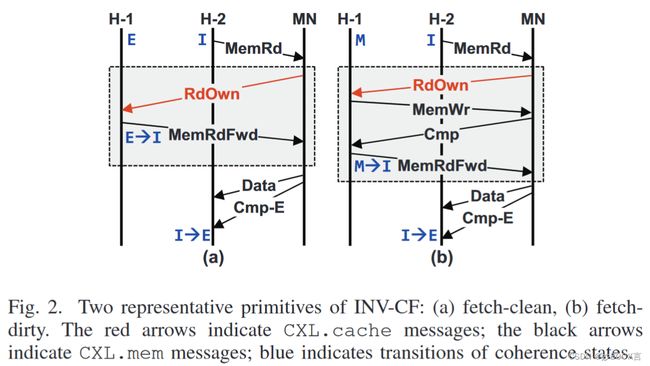
CXL 3.0中引入了管理多个计算节点一致性的反向失效通道(即从设备到主机的BISnp和从主机到设备的BIRsp)。例如,与图2(b)中的INV-CF操作相比,计算节点H-2请求另一个计算节点H-1缓存的高速缓存行。在收到来自H-2的MemRd后,内存节点发出BISnpInv使H-1中的缓存数据失效。如果缓存的数据是脏的,H-1将数据连同MemWr消息转发到内存节点;如果数据是干净的,则直接向内存节点回复BIRspI消息。最后,内存节点向H-2发送Cmp-E和数据。
挑战和现有方法局限性
现有的分离式内存系统面临的关键问题:远程访问开销和用户透明度。
远程访问开销高
与访问本地内存相比,访问远程内存节点会产生较高的延迟,同时需要二级地址转换。
-
在使用传统的基于网络的事务(例如TCP)时,涉及多个软件层次的数据缓冲区复制 [23]。尽管已经提出了基于RDMA的分离式内存系统,以在最小化数据复制和涉及的软件层次的同时直接访问远程内存区域 [5], [10], [17], [21], [34], [46], [50], [53],但使用RDMA仍需要在软件级别进行基于队列对的事务的附加复制操作 [20]。
-
二级地址转换也是导致高远程访问开销的一个关键因素。在分离式内存系统中,每个计算节点运行自己的操作系统,需要通过二级地址转换将来自每个计算节点的节点级物理地址转换为系统/全局物理地址。这种从节点到系统的地址映射需要存储在内存节点中,导致更多的远程访问。
-
通过缓存可以优化地址转换。第一个方案地址翻译缓存,以减少由两级地址翻译引起的远程访问次数(见背景-分离式内存系统)。第二个方案是数据缓存机制,在计算节点中缓存内存节点的数据。图4比较了两种情况的延迟图,我们假设本地物理地址已经被转换为全局物理地址,有一个主机节点(H),背板(B)和一个内存节点(MN)。图4(a)显示了仅使用地址翻译缓存的控制流,内存请求(例如,MemWr)发送到MN,因为H不缓存数据;B从MN请求权限标志以检查访问权限;如果B确认没有权限问题,将内存请求转发到MN。图4(b)显示了组合方案的时序图。H已经在其缓存中具有所请求的数据,但是内存请求仍需要检查数据访问权限。H向MN请求权限标志以检查访问权限;B将接收到的标志转发给H。性能提升就是两个请求回复之间的时间差。

缺乏用户透明度
-
实现用户应用对内存节点的透明访问对分离式内存系统至关重要。然而,基于RDMA的分离式内存系统要求用户通过修改其应用程序,使用RDMA动词的API(例如libibverbs [30])来传输数据到/从远程内存区域。
多个计算节点之间的数据一致性
-
现有方法很少考虑多节点间数据一致性,或使用软件同步[2]、[22]、[40]在不同节点之间提供数据共享。但软件同步将产生显著的性能开销,如对传统多核和分布式系统的研究[12],[19]所示。
-
例如使用基于失效的控制流(INV-CF)执行MESI一致性协议时,会产生额外的事务。如图2中阴影部分所示,fetch-clean会产生两个额外的事务,而fetch-dirty需要四个事务才能使数据无效。
将CXL技术应用于分离式内存系统带来的新挑战
CXL是一种缓存一致的事务级协议,使用自己的内存语法抽象I/O路径,与底层设备介质无关 [29]。借助其内存语法,CXL可以在对操作系统进行最小修改的情况下透明地扩展主内存池。
-
CXL 2.0仅支持单个计算节点(即主机)与多个CXL设备之间的一致性。尽管CXL 3.0支持多个计算节点之间的数据一致性,但计算节点需要在同一时间独占缓存数据,通过使其他计算节点中相同数据无效,从而影响展现出高数据局部性的应用程序的性能。
-
即使使用CXL数据共享,与其他缓存方案协调一致仍然具有挑战性,因为现代分离式内存系统采用地址转换缓存方案,该方案将访问权限检查与地址转换解耦 [32],检查访问权限不可避免地需要远程访问。访问数据(无论是否缓存)必须在进行权限检查之后进行,从而由于串行化导致系统性能不佳。
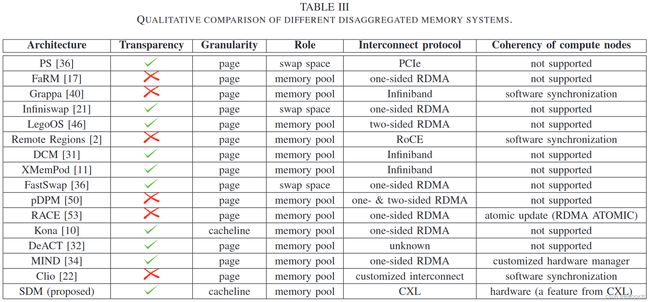
分离式内存的相关工作
本文工作
我们提出了支持共享的分离式内存系统,即SDM,它允许多个计算节点在无需昂贵的无效操作的情况下访问共享数据。
-
SDM采用支持共享的控制流(SHA-CF),该控制流对请求主机之外的所有节点进行抽象,其中内存节点利用CXL.cache和CXL.mem消息类型,在不违反其自己的协议的情况下模拟对其他主机的嗅探事务。
-
内存节点的资源管理基元也是至关重要的,如分配、释放和地址转换。这些基元不应干扰CXL的正常读写事务通道(即CXL.mem和CXL.cache)。我们利用CXL.io通道进行设备控制,以管理内存节点资源。
-
提出了一种具有推测性访问的方案,以结合地址转换缓存和数据缓存。关键思想是通过推测性地重叠数据访问和权限检查,以增加请求处理吞吐量,一旦检测到违规,会断开会话连接。
基于一个内部仿真框架进行了设计评估,该框架使用详细的分析模型模拟了具有缓存一致性的多节点解聚内存系统。结果显示,SDM在计算密集型和内存密集型工作负载上分别比类似于采用CXL 3.0的优化基准系统提高了5.77倍和2.65倍。
SDM 架构
图5展示了SDM的体系结构概述。在高层次上,SDM由计算节点、背板和存储节点组成。
在计算节点中,系统代理通过在主机桥的I/O路径中引入CXL相关功能(包括一致性桥接器(COHB)和主机代理)而得到增强。主机代理充当计算节点与背板之间的接口。一旦主机代理接收到CXL消息(例如,RdOwn),它将消息重定向到CXL规范中定义的COHB。COHB读取并更新存储在本地内存中的一致性目录。一致性目录保存属于该计算节点的每个缓存行的一致性状态,一致性目录支持连续分配,它可以使用代数计算进行索引。计算目录索引的延迟相对于其他延迟(例如,互连)是可以忽略的。然而,在我们的评估中,没有考虑在缓存目录中查找,因此实际实现可能对一致性管理具有更长的路径。与中断处理器不同,CXL功能利用直接内存访问(DMA)引擎,以便直接与本地内存进行通信。最后,主机代理生成CXL消息,以根据COHB引用的状态响应传入的请求消息。
在背板上,CXL交换机将来自不同计算节点的CXL请求分发给内存节点。在仲裁请求之前,CXL交换机与地址转换单元(ATU i)进行通信,ATU i执行二级页表遍历,将本地物理地址转换为全局物理地址。
在内存节点中,还包括两个额外的特性:CXL解析器,从传入的CXL请求中获取源和请求类型信息;设备一致性代理(DCOH),该代理在CXL规范中定义,保存内存节点的一致性状态,并根据从CXL解析器提取的信息生成CXL.cache消息。内存节点还需要一个目录,即由DCOH逻辑管理的偏置表,该偏置表保存内存节点缓存其他节点的私有数据的缓存一致性状态。
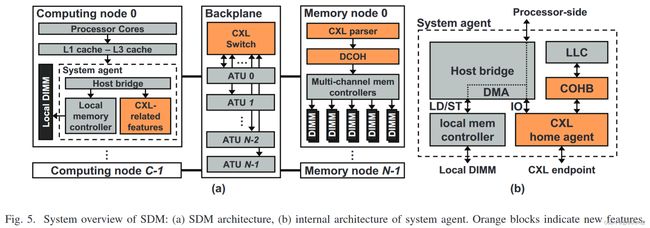
在SDM中,必须详细考虑几个设计方面。第一,需要一个控制流来促进多主机分离式内存系统的数据共享,而不是采用高开销的控制流(即INV-CF),而且,该控制流不应与CXL规范相冲突。第二,必须有一组远程内存管理机制,用于页面分配、释放和页表遍历。这些管理机制不应干扰正常的内存事务通道(即CXL.mem和CXL.cache),以确保更高的系统性能。我们观察到这些机制可以通过巧妙地利用一个特殊的CXL通道来实现,而无需引入额外的旁路协议。第三,提出了一种预测的方法,将地址转换缓存方案和数据缓存方案和谐地结合起来。
SHA-CF:启用共享的控制流
【就是基于嗅探的MESI协议,利用CXL反向失效稍微优化一点】
我们提出了一致性控制流SHA-CF,该控制流在SDM中实现了多个计算节点之间的数据共享。SHA-CF的关键思想是将所有节点(除了请求节点)抽象为一个内存设备,并利用CXL.cache消息模拟在多个主机上的嗅探。图6显示了SHA-CF关键原语的三种场景:获取-独占(fetch-exclusive)、获取-共享(fetch-share)、修改之前使无效(invalidate-before-modify)。此图中的所有场景都假定有两个主机(H-1和H-2)和一个内存节点(MN),SHA-CF可以推广为支持多个计算和内存节点。我们的SHA-CF严格遵守CXL规范中定义的事务协议(即请求和响应消息是成对的),没有任何重新定义。
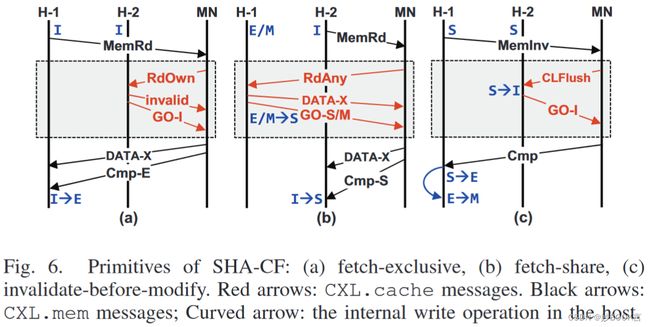
获取-独占原语,图6(a),定义了当主机(H-1)获取其他主机未共享的数据时的控制流。H-1发送MemRd消息以从内存节点读取数据DATA-X。然后,内存节点广播RdOwn以检查其他主机中是否存在DATA-X。一旦内存节点从H-2接收到带有无效行的GO-I,内存节点发送Cmp-E和DATA-X,让H-1将一致性状态更新为E状态(独占)。
获取-共享原语,图6(b),假设H-1最初持有DATA-X。H-2向内存节点发出对DATA-X的读取请求。然后,内存节点广播类似于获取-独占原语的RdAny。与获取-独占的情况不同,如果数据不是脏的,H-1会响应DATA-X并附带GO-S。如果DATA-X是脏的,将返回GO-M,以便将最新数据转发给H-2。如果内存节点收到GO-M和DATA-X,内存节点需要写回DATA-X。
修改之前使无效原语,图6(c),两个主机共享DATA-X,DATA-X将被H-1修改。在更新DATA-X之前,H-1向内存节点发出MemInv以通知反向失效。内存节点广播CLFlush以使DATA-X失效。在失效其缓存行后,H-2向内存节点响应GO-I。在H-1收到作为MemInv响应的Cmp后,H-1修改DATA-X。使用CXL 3.0中的反向失效消息,可以用更少的事务来实现修改之前使无效的原语。
远程内存管理
【基于CXL.io执行内存管理,不影响CXL.cache和CXL.mem,其他没啥特别的】
我们解释了SDM中管理页面分配的机制。为了防止干扰正常内存事务,SDM利用了厂商定义的消息字段。提出的机制包含三个远程页面管理原语:ralloc、rfree、rwalk。图7展示了这三个原语的过程,示例中显示了一个主机(H),背板(B)和一个内存节点(MN)。

ralloc原语用于在内存节点中新分配一个物理页面。图7(a),计算节点发送一个ralloc请求到背板,因为主机的内存管理单元触发了初始页面错误(例如,在内核中修改的do_page_fault())。背板中的地址转换单元(ATU)分配一个页面并更新相应的权限标志,然后向计算节点发送完成信号Cmp。
rfree用于释放内存节点中已分配的页面。图7(b),计算节点触发了远程页面的释放过程(例如,在内核中修改的deallocuvm()),并发送rfree消息。地址转换单元取消分配请求的页面,并取消相应权限标志的掩码。
rwalk用于将本地物理地址转换为全局物理地址。图7(c),一个内存请求(例如,MemRd)发送到背板。背板通过反复访问内存节点中的页表,进行第二级页表遍历。在获取了权限标志之后,原始请求被重定向到内存节点。由于假定了地址翻译缓存,转换后的信息也可以传递到主机,进行地址翻译缓存。因此,提出的机制需要修改主机的内存管理单元以管理三个原语及其响应。如[32]中提到的,缓存的翻译一致性是基于失效的处理进行管理的。例如,由于作业迁移,从本地物理地址到全局物理地址的映射发生了变化。随后,ATU将通过发出携带本地物理地址的请求来使缓存的翻译失效。在我们的系统中,地址转换是通过CXL.io通道管理的,因此失效也可以通过相同的通道执行,通过在CXL.io的第15字节中定义一个专用消息来实现。
推测性访问
【就是乐观的执行仿存,若权限检查失败在回滚】
SDM中的推测访问用于和谐地结合地址转换缓存和数据缓存。推测访问的主要思想是在允许权限检查前进行访问,即,在检查权限标志之前对内存请求进行推测性处理。因此,计算节点无需等待来自内存节点的权限标志(如图4(b))。
在权限标志到达计算节点后,CXL主代理硬件执行权限验证过程。例如,对于写请求,如果在相应的数据上允许该请求,则继续执行写请求;否则,使用“重放数据”将更新的数据回滚到原始状态。为了支持重放数据,推测访问需要在计算节点中的建立重放缓冲区。一旦需要回滚,则使用重放缓冲区中的旧数据条目将更新的数据恢复到旧状态。为了系统的安全操作,如果数据被恶意的非法访问,访问控制违规处理将隔离相应的会话,以防止来自该用户会话的进一步请求。
修改系统代理
为了在SDM中支持CXL事务,必须修改系统代理。图5(b)详细说明了计算节点中的系统代理。系统代理缓存位于系统代理中,用于缓存远程数据,系统代理缓存中的数据也可以被处理器核心的L1-L3缓存缓存。在系统代理缓存旁边,主机桥将内存请求多路复用到本地DIMM控制器或CXL主代理之间,主代理充当计算节点和背板之间的接口。一旦主代理接收到与一致性相关的消息,它将消息重定向到一致性桥(COHB),后者读取和更新存储在本地内存中的一致性目录。一致性目录是存储系统代理缓存中每行的一致性状态的重要特性。在不中断处理器的情况下,CXL主代理引入了一个直接内存访问(DMA)引擎,用于直接与本地内存通信。
实验
实验环境
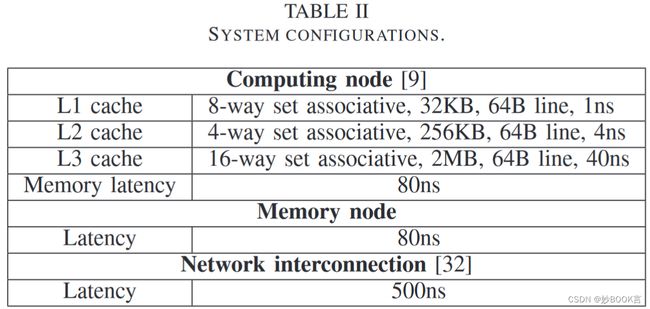
使用Intel PIN tool构建了模拟器,一些参数如表2,具体细节没说,统计运行数据,根据公式计算访问时间和延迟。
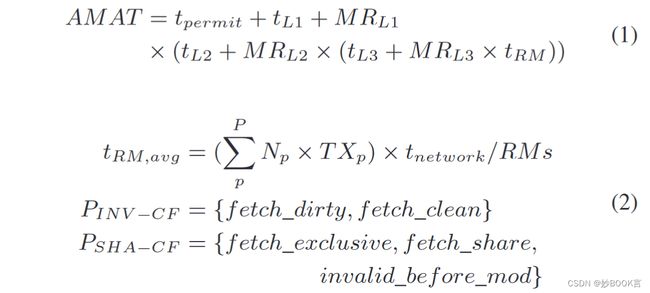
数据集
-
PARSEC(计算密集型)[8],11个工作负载:blackscholes、bodytrack、canneal、dedup、facesim、ferret、fluidanimate、raytrace、streamcluster、swaptions和x264。
-
Intel GAP(内存密集型)[7],我们使用两个真实世界的图,twitter和web,其中应用了四个内核:bfs(广度优先搜索)、bc(介数中心性)、cc(连通分量)和sssp(单源最短路径),通过组合这些不同的图和内核来评估8个图的工作负载。
对比实验
对比:吞吐量、延迟、对计算节点数量的敏感性、对网络延迟的敏感性
总结
利用CXL优化分离式内存,利用CXL特性优化多处理器间的缓存一致性协议(MESI协议)。通过支持共享的控制流(SHA-CF)促进多主机间的共享,本质还是基于嗅探的MESI协议,利用CXL反向失效进行优化;利用CXL.io管理节点资源,不影响CXL.cache和CXL.mem传输;提出推测访问,就是乐观的执行仿存,若权限检查失败在回滚。
局限性:总体来看比较简单,利用CXL的特性来优化MESI协议;实验基于Intel PIN tool构建了模拟器,但没有具体细节,只对比了基础的基于嗅探的MESI协议,没有对比更好的缓存一致性算法。