数据结构 - 第 2 章 线性表
【考纲内容】
(一)、 线性表的定义和基本操作
(二)、线性表的实现
顺序存储;链式存储;线性表的应用
【知识框架】

【复习提示】
线性表是考研命题的重点 ;
这类算法题实现起来比较容易而且代码量较少,但却要求具有最优的性能(时间 、空间复杂度),才能获得满分;
因此,需要牢固掌握线性表的各种操作(基于两者存储结构),在平时的学习中多注重培养动手能力;
另外,需要提醒的是,算法最重要的是思想!考场上的时间有限,在试卷上不一定要求代码具有实际的可执行性,因此应尽力表达出算法的思想和步骤,而不必过于拘泥于每个细节!注意算法题只能用 C/C++ 语言实现
2.1 线性表的定义和基本操作
| 线性表的定义和基本操作 | |
| ################################################################################## | |
| 2.1.1 线性表的定义 | |
| 线性表的定义 | 线性表是具有相同数据类型的  ( (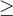 0)个数据元素的有限序列 0)个数据元素的有限序列 |
| 表长 | 线性表中数据元素的个数 |
| 空表 | 当数据元素个数 为 0 时,称为 "空表" |
| 线性表的一般表示 | 用 L 命名线性表,其一般表示为 |
| 线性表的逻辑特性 | (i). (ii). (iii). 除表头元素外,每个元素有且仅有一个直接前驱 (iv). 除表尾元素外,每个元素有且仅有一个直接后继 |
| 线性表的特点 | (i). 表中元素的个数有限 (ii). 表中元素具有逻辑上的顺序性,表中元素有其先后次序 (iii). 表中元素都是数据元素,每个元素都是单个元素 (iv). 表中元素的数据类型都相同,即每个元素占有相同大小的存储空间 (v). 表中元素具有抽象性,仅讨论元素间的逻辑关系,而不考虑元素究竟表示什么内容 |
| 注意 | 线性表是一种逻辑结构,表示元素之间一对一的相邻关系; 顺序表和链表是指存储结构,两者属于不同层面的概念,不要将其混淆 |
| ################################################################################## | |
| 2.1.2 线性表的基本操作 | |
| ################################################################################## | |
| Init(&L) | 初始化表:构造一个空的线性表 |
| Length(L) | 求表长:返回线性表 L 的长度,即 L 中数据元素的个数 |
| Empty(L) | 判空操作:若 L 为空表,则返回 true ,否则返回 false |
| LocateElem(L,e) | 按值查找操作:在表 L 中查找给定关键字值的元素 |
| GetElem(L,i) | 按位查找操作:获取表 L 中第 i 个位置上的元素的值 |
| Insert(&L,i,e) | 插入操作:在表 L 中的第 i 个位置插入指定元素 e |
| Delete(&L,i,&e) | 删除操作:删除表 L 中第 i 个位置上的元素,并用 e 返回被删除元素的值 |
| PrintList(L) | 输出操作:按先后顺序输出线性表 L 的所有元素的值 |
| Destroy(&L) | 销毁操作:销毁线性表,并释放线性表 L 所占用的内存空间 |
| 注意 | (i). 基本操作的实现取决于采用哪种存储结构(顺序存储还是链式存储),存储结构不同,算法的实现也不同 (ii). "&" 表示 C++ 中的引用调用,若传入的变量是指针型变量,且在函数体内要对传入的指针进行修改,则会用到指针变量的引用型;在 C 语言中采用指针的指针也可以达到同样的效果 |
 = (
= ( ,
, ,... ,
,... , ,
, ,... ,
,... , )
)2.2 线性表的顺序表示
2.2.1 顺序表的定义
| 顺序表的定义 | |
| 顺序表的概念 | 线性表的顺序存储又称顺序表 |
| 顺序表是用一组地址连续的存储单元,依次存储线性表中的数据元素; 从而使得逻辑上相邻的两个元素在物理位置上也相邻 |
|
| 位序 | 第 1 个元素存储在线性表的起始位置, 第 称 |
| 顺序表的特点 | 表中元素的逻辑顺序与其物理顺序相同 |
| 顺序存储结构 | 假设线性表
则表 |
 |
|
| 注意 | 线性表中元素的位序是从 1 开始的, 数组中元素的下标是从 0 开始的 |
| ################################################################################## | |
| 线性表存储类型描述 | |
| 一维数组可以是 静态分配 的,也可以是 动态分配 的 | |
| 静态分配 | 由于数组的大小和空间事先已经固定,一旦空间占满, 再加入新的数据将会产生溢出,进而导致程序崩溃 |
| #define MaxSize 50 // 定义线性表的最大长度 typedef struct { ElemType data[MaxSize]; // 顺序表的元素 int length; // 顺序表的当前长度 }SqList; // 顺序表的类型定义 |
|
| 动态分配 | 存储数组的空间是在程序执行过程中通过动态分配语句分配的, 一旦数据空间占满,就另外开辟一块更大的存储空间, 用以替换原来的存储空间,从而扩充存储数组空间, 而不需要为线性表一次性划分所有空间 |
| #define InitSize 100 // 表长度的初始定义 typedef struct { ElemType *data; // 指示动态分配数组的指针 int capacity; // 数组的最大容量 int length; // 数组的当前个数 }SeqList; // 动态分配数组顺序表的类型定义 |
|
| C 的初始动态分配语句: L.data = (ElemType*)malloc(sizeof(ElemType) * InitSize); C++ 的初始动态分配语句: L.data = new ElemType[InitSize]; |
|
| ################################################################################## | |
| 注意 | 动态分配并不是链式分配,还是属于顺序存储结构, 物理结构没有变化,依然是随机存储方式, 只是分配的空间大小可以在运行时决定 |
| 顺序表的特点 |
随机访问,即通过首地址和元素序号可在时间 找到指定的元素 |
| 顺序表的优点 |
存储密度高,每个结点只存储数据元素 |
| 顺序表的缺点 |
逻辑上相邻的元素在物理上也相邻, 所以插入和删除操作,需要移动大量元素 |
 个元素的存储位置后面紧接着存储的是第
个元素的存储位置后面紧接着存储的是第 2.2.2 顺序表的接口
1. 存储结构
#include
#include
#define MAXSIZE 20
#define OK 1 // success
#define ERROR 0 // failure
typedef int Status; // function return type
typedef int ElemType; // simple data type
typedef struct {
ElemType *elem;
int cap
int len;
}SeqList; 2. 初始化表
Status InitList(SeqList* L)
{
L->elem = (ElemType*)malloc(sizeof(ElemType) * MAXSIZE);
if (L->elem == NULL)
{
printf("Out of memory!\n");
return ERROR;
}
L->cap = MAXSIZE;
L->len = 0;
return OK;
}3. 求表长
int Length(SeqList *L)
{
return L->len;
}4. 按值查找
int LocateElem(SeqList *L, ElemType e)
{
for (int k = 0; k < L->len; k++)
{
if (L->elem[k] == e)
{
return k + 1;
}
}
return -1;
}| 按值查找 | |
| 概念 | 在顺序表 并返回该元素的位序 |
| 时间复杂度分析 | |
| 最好情况 | 查找的元素就在表头,仅需比较一次,时间复杂度为  |
| 最坏情况 | 查找的元素在表尾(或不存在)时,需要比较 时间复杂度为 |
| 平均情况 | 假设 (1 <= 则在长度为 |
 |
|
因此,线性表按值查找算法的平均时间复杂度为  |
|
 的元素,
的元素,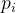 (
(  )是查找的元素在第
)是查找的元素在第 5. 按位获取
Status GetElem(SeqList *L, int i, ElemType *e)
{
if (i < 1 || i > L->len)
{
printf("Invalid index !\n");
return ERROR;
}
if (L->len == 0)
{
printf("Empty List !\n");
return ERROR;
}
*e = L->elem[i-1];
return OK;
}6. 插入
Status Insert(SeqList *L, int i, ElemType e)
{
if (i < 1 || i > L->len + 1)
{
printf("Invalid index !\n");
return ERROR;
}
if (L->len == L->cap)
{
L->elem = (ElemType*)realloc(L->elem, 2 * L->cap);
if (L->elem == NULL)
{
printf("Out of memory !\n");
return ERROR;
}
}
for (int k = L->len; k >= i; k--)
{
L->elem[k] = L->elem[k-1];
}
L->elem[i-1] = e;
L->len++;
return OK;
}| 插入操作 | |
| 概念 | 在顺序表 若 将顺序表的第 腾出一个空位置插入新元素 插入成功,返回 true |
| 注意 | 区别顺序表的位序和数组下标 |
| 时间复杂度分析 | |
| 最好情况 | 在表尾插入(即 不需要后移元素,时间复杂度为 |
| 最坏情况 | 在表头插入(即 时间复杂度为 |
| 平均情况 | 假设 则在长度为 平均次数为 |
|
|
|
| 因此,线性表插入算法的平均时间复杂度为 |
|
 ),元素后移语句将执行
),元素后移语句将执行 7. 删除
Status Delete(SeqList *L, int i, ElemType *e)
{
if(L->len == 0)
{
printf("Empty List !\n");
return ERROR;
}
if(i < 1 || i > L->len)
{
printf("Invalid index !\n");
return ERROR;
}
*e = L->elem[i-1];
for(int k = i; k < L->len; k++)
{
L->elem[k-1] = L->elem[k];
}
L->len--;
return OK;
}| 删除操作 | |
| 概念 | 删除顺序表 若成功则返回 true ,并将被删除的元素用引用变量 若失败则返回 false |
| ################################################################################## | |
| 时间复杂度分析 | |
| 最好情况 | 删除表尾元素(即 时间复杂度为 |
| 最坏情况 | 删除表头元素(即 所有元素,时间复杂度为 |
| 平均情况 | 假设 则在长度为 平均次数为 |
| 因此,线性表删除算法的平均时间复杂度为 |
|
 ),无需移动元素,
),无需移动元素, ),需移动除第一个元素外的
),需移动除第一个元素外的8. 打印
void PrintList(SeqList *L)
{
if (L->len == 0)
{
printf("Empty List !\n");
return ERROR;
}
for (int i = 0; i < L->len; i++)
{
printf("the %d th element is %d\n", i+1, L->elem[i]);
}
return OK;
}9. 判空
bool Empty(SeqList *L)
{
if (L->len == 0)
return true;
else
return false;
}10. 销毁
void Destroy(SeqList *L)
{
free(L->elem);
L->elem = NULL;
L->len = 0;
L->cap = 0;
}2.2.3 练习题
接口:
#include
#include
#define MAXSIZE 100
#define OK 1
#define ERROR 0
typedef int ElemType;
typedef int Status;
typedef struct {
ElemType *elem;
int cap;
int len;
} SeqList;
Status InitList(SeqList *L);
void Destroy(SeqList *L);
Status Empty(SeqList *L);
int Length(SeqList *L);
int LocateElem(SeqList *L, ElemType e);
Status GetElem(SeqList *L, int i, ElemType *e);
Status Insert(SeqList *L, int index, ElemType e);
Status Delete(SeqList *L, int index, ElemType *e);
Status PrintList(SeqList* L);
int main(int argc, char* argv[])
{
SeqList L;
ElemType e = 0;
InitList(&L);
printf("Just Init!\n");
if (Empty(&L) == OK)
printf("Empty\n");
else
printf("Not Empty\n");
printf("len of list is %d\n", Length(&L));
Insert(&L, 1, 5);
Insert(&L, 2, 7);
Insert(&L, 3, 11);
Insert(&L, 4, 13);
Insert(&L, 5, 17);
printf("the index of 13 is %d\n", LocateElem(&L, 13));
PrintList(&L);
Delete(&L, 3, &e);
if (Empty(&L) == OK)
printf("Empty\n");
else
printf("Not Empty\n");
printf("len of list is %d\n", Length(&L));
Destroy(&L);
return 0;
}
Status InitList(SeqList *L)
{
L->elem = (ElemType*)malloc(sizeof(ElemType) * MAXSIZE);
if (L->elem == NULL)
{
printf("Out of memory!\n");
return ERROR;
}
L->cap = MAXSIZE;
L->len = 0;
return OK;
}
void Destroy(SeqList *L)
{
free(L->elem);
L->elem = NULL;
L->len = 0;
L->cap = 0;
}
Status Empty(SeqList *L)
{
if (L->len == 0)
return OK;
else
return ERROR;
}
int Length(SeqList *L)
{
return L->len;
}
int LocateElem(SeqList *L, ElemType e)
{
for (int k = 0; k < L->len; k++)
{
if (L->elem[k] == e)
{
return k + 1;
}
}
return -1;
}
Status GetElem(SeqList *L, int i, ElemType *e)
{
if (i < 1 || i > L->len)
{
printf("Invalid index !\n");
return ERROR;
}
if (L->len == 0)
{
printf("Empty List !\n");
return ERROR;
}
*e = L->elem[i - 1];
return OK;
}
Status Insert(SeqList *L, int index, ElemType e)
{
if (index < 1 || index > L->len + 1)
{
printf("Invalid index !\n");
return ERROR;
}
if (L->len == L->cap)
{
L->elem = (ElemType*)realloc(L->elem, 2 * L->cap);
if (L->elem == NULL)
{
printf("Out of memory !\n");
return ERROR;
}
}
for (int k = L->len; k >= index; k--)
{
L->elem[k+1] = L->elem[k];
}
L->elem[index-1] = e;
L->len++;
printf("the %dth inserted elem is %d\n", index, e);
return OK;
}
Status Delete(SeqList *L, int index, ElemType *e)
{
if(L->len == 0)
{
printf("Empty List !\n");
return ERROR;
}
if(index < 1 || index > L->len)
{
printf("Invalid index !\n");
return ERROR;
}
*e = L->elem[index - 1];
if(index < L->len)
{
for(int k = index; k < L->len; k++)
{
L->elem[k-1] = L->elem[k];
}
}
L->len--;
printf("the %dth deleted elem is %d\n", index, *e);
return OK;
}
Status PrintList(SeqList* L)
{
if (L->len == 0)
{
printf("Empty List !\n");
return ERROR;
}
for (int i = 0; i < L->len; i++)
{
printf("the %d th element is %d\n", i+1, L->elem[i]);
}
return OK;
} 1. 删除最小元素
/*
* 从顺序表中删除具有最小值的元素(假设唯一)并由函数返回背包删除元素的值,
* 空出的位置由最后一个元素填补,若顺序表为空则显示出错信息并退出运行
*/
void DeleteMin(SqList *L, ElemType *e)
{
if (L->len == 0)
{
printf("Empty List, can not delete any element !\n");
return ERROR;
}
int minIndex = 0;
for (int i = 1; i < L->len; i++)
{
if (L->elem[i] < L->elem[i-1])
{
minIndex = i;
}
}
*e = L->elem[minIndex];
if (minIndex != L->len - 1)
{
L->elem[minIndex] = L->elem[L->len-1];
L->elem[L->len-1] = 0;
}
L->len--;
return;
}2.3 线性表之链式表示
| 顺序表的优点 | 可以随时存取表中的任意一个元素,存储位置可以用简单 、直观的公式表示 |
| 顺序表的缺点 | 插入和删除操作需要移动大量元素 |
| 链表 | |
| 链表的特点 | 不需要使用地址连续的存储单元, 即,不要求逻辑上相邻的元素在物理位置上也相邻, 通过 "链" 来建立起数据元素之间的逻辑关系 |
| 链表的优点 | 插入和删除操作不需要移动元素,只需修改指针 |
| 链表的缺点 | 无法像顺序表那样随机存取元素 |
2.3.1 单链表的定义
| 单链表的定义 | |
| 概念 | 线性表的链式存储又称单链表; 通过一组任意的存储单元来存储线性表中的数据元素; 为了建立数据元素之间的线性关系,对每个链表结点,除存放元素自身的信息外, 还需要存放一个指向其后继的指针; |
| 结点 | 单链表结点结构如图所示,其中 data 为数据域,存放数据元素; next 为指针域,存放其后继结点的地址 |
|
|
|
| 单链表中结点 类型的描述 |
typedef struct LNode { // 定义单链表结点类型 ElemType data; // 数据域 struct LNode *next; // 指针域 } LNode, *LinkList; |
| 小结 | (i). 利用单链表可以解决顺序表需要大量连续存储单元的缺点;然而单链表附加指针域,存在浪费存储空间的缺点 (ii). 单链表的元素离散地分布在存储空间中,故单链表无法随机存取,即不能直接找到表中某个特定的结点 (iii). 如果想查找某个特定的结点,则必须从表头开始遍历,依次查找 |
| 技巧 | (i). 通常用头指针来标识一个单链表,如单链表 (ii). 为了操作上的方便,在单链表第一个结点之前附加一个结点,称为 "头结点" (iii). 头结点的数据域可以没有信息,也可以记录表长;头结点的指针域指向线性表的第一个元素结点 |
 |
|
| 头结点与 头指针 |
不管带不带头结点,头指针时钟指向链表的第一个结点; 头结点是带头结点的链表的第一个结点,头结点内通常不存储信息 |
| 引入头结点 的优势 |
(1). 由于第一个数据结点的位置被存放在头结点的指针域中,所以在链表的第一个位置上的操作和在表中其他位置上的操作一致,无需进行特殊处理 (2). 无论链表是否为空,其头指针都指向头结点的非空指针(空表中头结点的指针域为空),因此空表和非空表的处理得到统一 |

2.3.2 单链表的接口
#include
#include
typedef int ElemType;
struct Node;
typedef struct Node *PtrToNode;
typedef PtrToNode List;
typedef PtrToNode Position;
struct Node
{
ElemType Elem;
Position Next;
};
List MakeEmpty(List L);
int IsEmpty(List L);
int IsLast(Position P);
Position FindPrevious(List L, ElemType E);
Position Find(List L, ElemType E);
void HeadInsert(Position Head, ElemType E);
Position TailInsert(Position Tail, ElemType E);
void Delete(List L, ElemType E);
void DeleteList(List L);
Position Header(List L);
Position First(List L);
Position Advance(Position P);
ElemType Retrieve(Position P);
void PrintList(List L);
void PrintEmpty(List L);
int main(int argc, char* argv[])
{
List Lh, Lt;
Position Head, Tail;
Lh = Lt = Head = Tail = NULL;
Lh = MakeEmpty(Lh);
Lt = MakeEmpty(Lt);
Head = Lh->Next;
Tail = Lt->Next;
for (int i = 1; i <= 5; i++)
{
HeadInsert(Head, i*i+3); // 4 7 12 19 28
Tail = TailInsert(Tail, i*i+3);
}
printf("\n");
printf("HeadInsert : \n");
PrintList(Lh);
printf("\n");
printf("TailInsert : \n");
PrintList(Lt);
printf("\n");
DeleteList(Lh);
DeleteList(Lt);
return 0;
}
List MakeEmpty(List L)
{
L = (List)malloc(sizeof(struct Node));
if (!L)
return NULL;
Position header = (Position)malloc(sizeof(struct Node));
if (!header)
return NULL;
header->Next = NULL;
L->Next = header;
return L;
}
int IsEmpty(List L)
{
return L->Next == NULL;
}
int IsLast(Position P)
{
return P->Next == NULL;
}
Position FindPrevious(List L, ElemType E)
{
Position P;
P = L;
while (P->Next != NULL && P->Next->Elem != E)
P = P->Next;
return P;
}
Position Find(List L, ElemType E)
{
Position P;
P = L->Next;
while (P != NULL && P->Elem != E)
P = P->Next;
return P;
}
void HeadInsert(Position Head, ElemType E)
{
Position NewCell;
NewCell = (Position)malloc(sizeof(struct Node));
if (NewCell == NULL)
{
printf("Out of memory!\n");
exit(0);
}
NewCell->Elem = E;
NewCell->Next = Head->Next;
Head->Next = NewCell;
}
Position TailInsert(Position Tail, ElemType E)
{
Position NewCell;
NewCell = (Position)malloc(sizeof(struct Node));
if (NewCell == NULL)
{
printf("Out of memory!\n");
exit(0);
}
NewCell->Elem = E;
NewCell->Next = NULL;
Tail->Next = NewCell;
return NewCell;
}
void Delete(List L, ElemType E)
{
Position P, TmpCell;
P = FindPrevious(L, E);
if (!IsLast(P))
{
TmpCell = P->Next;
P->Next = TmpCell->Next;
free(TmpCell);
}
}
void DeleteList(List L)
{
Position P, TmpCell;
P = L->Next;
L->Next = NULL;
while (P != NULL)
{
TmpCell = P->Next;
free(P);
P = TmpCell;
}
}
Position Header(List L)
{
return L;
}
Position First(List L)
{
return L->Next;
}
Position Advance(Position P)
{
return P->Next;
}
ElemType Retrieve(Position P)
{
return P->Elem;
}
void PrintList(List L)
{
Position Head, Cur;
int count = 1;
Head = L->Next;
Cur = Advance(Head);
while (Cur != NULL)
{
printf("%dth elem is %d\n", count, Retrieve(Cur));
count++;
Cur = Advance(Cur);
}
}
void PrintEmpty(List L)
{
if (IsEmpty(L) != 0)
printf("Empty\n");
else
printf("Not Empty\n");
} 2.3.3 双链表
| 双链表的定义 | |
| 单链表的局限性 | 单链表结点中只有一个指向其后继的指针,使得单链表只能从头结点依次顺序向后遍历;要访问某个结点的前驱结点(插入 、删除操作时),只能从头开始遍历,访问后继结点的时间复杂度为 ,访问前驱结点的时间复杂度为 |
| 引入双向链表 | 为了克服单链表的上述缺点,引入了双链表,双链表结点中有两个指针 prior 和 next ,分别指向当前结点的前驱结点和后继结点 |
 |
|
| 双链表中结点类型的描述 | typedef struct DNode { // 定义双链表结点类型 ElemType data; // 数据域 struct DNode *prior,*next; // 前驱和后继指针 } DNode,*DLinkList; |
| 注意 | 双链表在单链表的结点中增加了一个指向当前结点的前驱的 prior 指针,因此双链表中的按值查找和按序号查找的操作,与单链表的相同;但双链表在插入和删除操作的实现上,与单链表有着较大的不同,这是因为 "链" 变化时也需要对 prior 指针做出修改,其关键是保证在修改的过程中不断链; 此外,双链表可以很方便地找到其前驱结点,因此,插入 、删除操作的时间复杂度仅为 |
| ################################################################################## | |
| 双链表的插入操作 | |
在双链表中  所指的结点之后插入结点 所指的结点之后插入结点  ,其指针变化过程如下图 ,其指针变化过程如下图 |
|
 |
|
| 上图中,是在当前结点的前面,插入新结点;当然也可以在当前结点的后面,插入新结点; 这里,插入操作是有顺序的; 假如 4 个操作,2 个操作是一对,每对操作中,都是由新结点发起连接; 前插中,第一步操作完成,新结点和当前结点的前驱建立连接; 后插中,第一步操作完成,新结点和当前结点的后继建立连接; |
|
| 前插 | 规则:新结点,先与当前结点的前驱结点建立连接,再和当前结点建立连接 (i). s->prior = p->prior; // 新结点先开始,新结点的前驱指针指向当前结点的前驱结点 p->prior->next = s; // 当前结点的前驱结点的后继指针指向新结点 (ii). s->next = p; // 新结点先开始,新结点的后继指针指向当前结点 p->prior = s; // 当前结点的前驱指针指向新结点 |
| 后插 | 规则:新结点,先与当前结点的后继结点建立连接,再和当前结点建立连接 (i). s->next = p->next; // 新结点先开始,新结点的后继指针指向当前结点的后继结点 p->next->prior = s; // 当前结点的后继结点的前驱指针指向新结点 (ii). s->prior = p; // 新结点先开始,新结点的前驱指针指向当前结点 p->next = s; // 当前结点的后继指针指向新结点 |
| 总结 |
第一点:无论是在前插还是后插中,新结点与当前结点建立连接都是在第二步中; 第二点:无论是在第一步中还是第二步中,连接都是由新结点发起 总结:违反第一点,就会断链,指针丢失导致插入失败 (新结点先与当前结点建立连接,则无法通过当前结点找到其前驱或后继了,因为此时当前结点的前驱或后继指针已经指向了新结点) |
| ################################################################################## | |
| 双链表的删除操作 | |
| 删除双链表中当前结点 *p 的后继(前驱)结点 *q ,其指针的变化过程如下 | |
 |
|
| 删除当前结点 | c->prior->next = c->next; c->next->prior = c->prior; free(c); |
| 删除当前结点前驱 | tmp = c->prior; tmp->prior->next = c; c->prior = tmp->prior; free(tmp); |
| 删除当前结点后继 | tmp = c->next; tmp->next->prior = c; c->next = tmp->next; free(tmp); |
#include
#include
typedef int ElemType;
struct Node;
typedef struct Node *PtrToNode;
typedef PtrToNode List;
typedef PtrToNode Position;
struct Node
{
ElemType Elem;
Position Prior, Next;
};
List MakeEmpty(List L);
int IsEmpty(List L);
int IsLast(Position P);
Position FindPrevious(List L, ElemType E);
Position Find(List L, ElemType E);
void HeadInsert(Position Head, ElemType E);
void TailInsert(List L, ElemType E);
void DeleteElem(List L, ElemType E);
void DeletePos(List L, Position Pos);
void DeleteList(List L);
Position Header(List L);
Position First(List L);
Position Advance(Position P);
ElemType Retrieve(Position P);
void PrintList(List L);
void PrintEmpty(List L);
int main(int argc, char* argv[])
{
List L;
Position Cur, Pre, H;
L = MakeEmpty(L);
PrintList(L);
H = L->Next;
HeadInsert(L, 2);
printf("L insert elem 2\n");
HeadInsert(L, 3);
printf("L insert elem 3\n");
HeadInsert(L, 5);
printf("L insert elem 5\n");
HeadInsert(L, 7);
printf("L insert elem 7\n");
HeadInsert(L, 11);
printf("L insert elem 11\n");
HeadInsert(L, 13);
printf("L insert elem 13\n");
printf("\n\n");
printf("Head Insert !!!\n");
PrintList(L);
printf("\n\n");
//printf("Del Elem = 7\n");
//DeleteElem(L, 7);
printf("Find Elem 11 and 5\n\n");
Pre = FindPrevious(L, 11);
printf("Pre's Next Elem is %d\n", Pre->Next->Elem);
Cur = Find(L, 5);
printf("Cur's Elem is %d\n", Cur->Elem);
printf("Del Elem = 7\n");
DeleteElem(L, 7);
printf("Current L is like below:\n");
PrintList(L);
printf("\n\n");
DeletePos(L, L->Next);
PrintList(L);
printf("Del First Node and Current L is like below\n");
DeletePos(L, L->Next);
PrintList(L);
printf("Del First Node and Current L is like below\n");
DeletePos(L, L->Next);
PrintList(L);
DeleteList(L);
printf("\n\n Current L is like below:\n");
PrintList(L);
return 0;
}
List MakeEmpty(List L)
{
L = (List)malloc(sizeof(struct Node));
if (!L)
return NULL;
Position header = (Position)malloc(sizeof(struct Node));
if (!header)
return NULL;
header->Next = NULL;
header->Prior = L;
L->Next = header;
L->Prior = NULL;
return L;
}
int IsEmpty(List L)
{
return L->Next->Next == NULL;
}
int IsLast(Position P)
{
return P->Next == NULL;
}
Position FindPrevious(List L, ElemType E)
{
Position P;
P = L;
while (P->Next != NULL && P->Next->Elem != E)
P = P->Next;
return P;
}
Position Find(List L, ElemType E)
{
Position P;
P = L->Next;
while (P != NULL && P->Elem != E)
P = P->Next;
return P;
}
void HeadInsert(Position Head, ElemType E)
{
Position NewCell;
NewCell = (Position)malloc(sizeof(struct Node));
if (NewCell == NULL)
{
printf("Out of memory!\n");
exit(0);
}
NewCell->Elem = E;
NewCell->Next = Head->Next;
Head->Next->Prior = NewCell;
NewCell->Prior = Head;
Head->Next = NewCell;
}
void TailInsert(List L, ElemType E)
{
Position NewCell, Tail;
Tail = L->Next;
while (Tail->Next != NULL)
Tail = Tail->Next;
NewCell = (Position)malloc(sizeof(struct Node));
if (NewCell == NULL)
{
printf("Out of memory!\n");
exit(0);
}
NewCell->Elem = E;
NewCell->Next = Tail->Next;
Tail->Next->Prior = NewCell;
NewCell->Prior = Tail;
Tail->Next = NewCell;
}
void DeleteElem(List L, ElemType E)
{
Position Pre, Cur;
Pre = FindPrevious(L, E);
if (!IsLast(Pre))
{
Cur = Pre->Next;
Pre->Next = Cur->Next;
Cur->Next->Prior = Pre;
free(Cur);
}
}
void DeletePos(List L, Position Pos)
{
Position Pre, Cur;
Pre = FindPrevious(L, Pos->Elem);
if (!IsLast(Pre))
{
Cur = Pre->Next;
Pre->Next = Cur->Next;
Cur->Next->Prior = Pre;
free(Cur);
}
}
void DeleteList(List L)
{
Position P, TmpCell;
P = L->Next;
L->Next = NULL;
while (P != NULL)
{
TmpCell = P->Next;
free(P);
P = TmpCell;
}
}
Position Header(List L)
{
return L;
}
Position First(List L)
{
return L->Next;
}
Position Advance(Position P)
{
return P->Next;
}
ElemType Retrieve(Position P)
{
return P->Elem;
}
void PrintList(List L)
{
Position Cur;
int count = 1;
Cur = L->Next;
if (Cur->Next == NULL)
{
printf("Empty List!\n");
return;
}
while (Cur->Next != NULL)
{
printf("%dth elem is %d\n", count, Retrieve(Cur));
count++;
Cur = Cur->Next;
}
}
void PrintEmpty(List L)
{
if (IsEmpty(L) != 0)
printf("Empty\n");
else
printf("Not Empty\n");
} 2.3.4 循环链表
| 循环单链表 | |
| 定义 | 循环单链表和单链表的区别在于: 循环单链表中最后一个结点的 next 指针不是 NULL,改为指向头结点, 从而整个链表形成一个环 |
 |
|
| 说明 | 在循环单链表中,表尾结点 *r 的 next 域指向头结点, 故表中没有指针域为 NULL 的结点 |
| 判空条件 | 循环单链表的判空条件不是头结点的 next 指针是否为 NULL , 而是头结点的 next 指针是否等于头指针 |
| 插入 、删除 | 循环单链表的插入 、删除操作与单链表的几乎一样,不同的地方在于, 若是在表尾插入 、删除,最后的表尾结点的 next 还得指向头结点, 来保持循环的性质 |
| 由于循环单链表是一个 "环",因此在任何一个位置上的插入和删除都等价, 无须判断是否是表尾 |
|
| 遍历 | (i). 在单链表中只能从表头结点开始往后顺序遍历整个链表, 而循环单链表可以从表中的任意一个结点开始遍历整个链表; (ii). 有时对单链表常做的操作是在表头和表尾进行的, 此时对于循环单链表不设头指针,而仅设尾指针,从而使得操作效率更高 (iii). 若设的是头指针,对表尾进行操作需要 若设尾指针 r ,r->next 即为头结点,对于表头与表尾进行操作都只需要
|
| ################################################################################## | |
| 循环双链表 | |
| 定义 | 在循环双链表中,头结点的 prior 指针还要指向表尾结点 |
 |
|
| 在循环双链表 当循环双链表为空表时,其头结点的 prior 和 next 都等于 |
|
2.3.5 静态链表
| 静态链表 | |
| 定义 | 静态链表借助数组来描述线性表的链式存储结构, 结点也有数据域 data 和指针域 next , 不同于前面所讲的链表, 这里的指针保存的是结点的相对地址(数组下标),也称游标 |
| 和顺序表一样,静态链表也要预先分配一块连续的存储空间 | |
| 静态链表和单链表的对应关系 | |
 |
|
| 静态链表结构类型的描述 | #define MaxSize 50 // 静态链表的最大长度 typedef struct { // 静态链表结点类型的定义 ElemType data; // 存储数据元素 int next; // 下一个元素的数组下标 } SLinkList[MaxSize]; |
| 总结 | 静态链表以 next == -1 作为其结束的标志 |
| 静态链表的插入 、删除操作与动态链表相同, 只需要修改指针,而不需要移动元素 |
|
2.3.6 顺序表和链表的比较
| 比较\类型 | 顺序表 | 链表 |
| 存取方式 | 可以顺序存取, 也可以随机存取 |
只能从表头顺序存取元素 |
| 逻辑结构与 物理结构 |
顺序存储,逻辑上相邻的元素, 对应的物理存储位置也相邻 |
链式存储,逻辑上相邻的元素, 物理存储位置不一定相邻, 对应的逻辑关系是通过指针链接表示 |
| 按值查找 | 顺序表无序时, 时间复杂度为 |
顺序查找,时间复杂度为 |
| 顺序表有序时,采用折半查找, 时间复杂度为 |
顺序查找,时间复杂度为 |
|
| 按序号查找 | 顺序表支持随机访问, 时间复杂度为 |
链表依旧只能从头开始顺序查找, 时间复杂度为 |
| 插入与删除 | 平均需要移动半个表长的元素 | 只需修改相关结点的指针域即可 |
| 每个结点都带有指针域,故存储密度不大 | ||
| 空间分配 | 静态分配: (i). 一旦存储空间装满就不能扩充,若再假如新元素,则内存溢出,因此需要预先分配足够大的存储空间 (ii). 预先分配过大,可能会导致顺序表后半部分空间大量闲置 (iii). 预先分配过小,会造成溢出 |
链式存储的结点空间只在需要时申请分配,只要内存有空间就可以分配,操作灵活 、高效 |
| 动态分配: (i). 当存储空间不够时,可以扩充存储空间 (ii). 扩充存储空间需要移动大量元素,导致操作效率低下 (iii). 若内存中没有更大块的连续存储空间, 则会导致分配失败 |
| 如何选取存储结构 | |
| 基于存储考虑 | 难以估计线性表的长度或存储规模时,不宜采用顺序表; 链表不用事先估计存储规模,但链表的存储密度较低, 显然链式存储结构的存储密度是小于 1 的 |
| 基于运算考虑 | 在顺序表中按序号访问 而链表中按序号访问的时间复杂度为 若常用的运算是按序号访问数据元素,则顺序表优于链表 |
| 在顺序表中进行插入 、删除操作时,平均移动表中一半的元素, 当数据元素的信息量较大且表较长时,必须考虑顺序表移动元素的特性; 在链表中进行插入 、删除操作时,虽然也要找插入位置,但操作主要是 比较操作; 若常用的运算是插入以及删除结点,则链表优于顺序表 |
|
| 基于环境考虑 | 顺序表容易实现,任何高级语言中都有数组类型; 链表的操作是基于指针; 相对而言,顺序表相较于链表,实现起来更简单 |
| 小结 | 两种存储结构各有长短,选择哪一种需要由实际问题的主要因素来决定; 通常较稳定的线性表选择顺序存储; 频繁进行插入 、删除操作的线性表(动态性较强)则应选择链式存储 |
| 注意 | 只有熟练掌握顺序存储和链式存储,才能深刻理解它们各自的优缺点 |