爬虫基本原理讲解
1.什么是爬⾍?
2.爬虫基本流程
3.什么是Request和Response?
4.Request中包含什么?
5.Response中包含什么?
6.爬虫能抓怎样的数据?
7.怎样来解析?
8.为什什么我抓到的和浏览器器看到的不一样?
9.怎样解决JavaScript渲染的问题?
10.可以怎样保存数据
1.什么是爬⾍?
请求网站并提取数据的自动化程序
2.爬虫基本流程
2.1 发起请求
通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器响应。
2.2 获取响应内容
如果服务器能正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能有HTML,Json字符串,二进制数据(如图片视频)等类型。
2.3 解析内容
得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析。可能是Json,可以直接转为Json对象解析,可能是二进制数据,可以做保存或者进一步的处理。
2.4 保存数据
保存形式多样,可以存为文本,也可以保存至数据库,或者保存特定格式的文件。
3.什么是Request和Response?
Request与Response
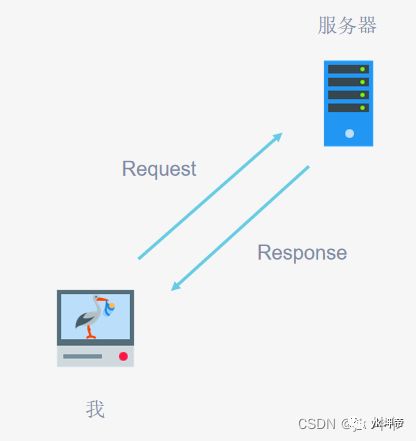
(1)浏览器就发送消息给该网址所在的服务器,这个过程叫做HTTP Request。
(2)服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应处理,然后把消息回传给浏览器。这个过程叫做HTTP Response。
(3)浏览器收到服务器的Response信息后,会对信息进行相应处理,然后展示。
4.Request中包含什么?
(1) 请求方式
主要有GET、POST两种类型,另外还有HEAD、PUT、DELETE、OPTIONS等。
(2) 请求URL
URL全称统一资源定位符,如一个网页文档、一张图片、一个视频等都可以用URL唯一来确定。
(3) 请求头
包含请求时的头部信息,如User-Agent、Host、Cookies等信息。
(4) 请求体
请求时额外携带的数据,如表单提交时的表单数据
5.Response中包含什么?
(1) 响应状态
有多种响应状态,如200代表成功、301跳转、404找不到页面、502服务器错误
(2) 响应头
如内容类型、内容长度、服务器信息、设置Cookie等等。
(3) 响应体
最主要的部分,包含了请求资源的内容,如网页HTML、图片二进制数据等。
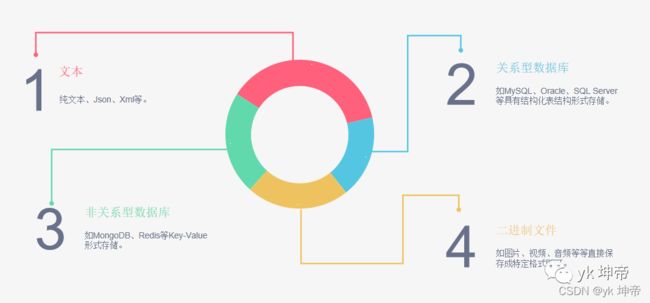
6.爬虫能抓怎样的数据?
(1) 网页文本
如HTML文档、Json格式文本等。
(2) 图片
获取到的是二进制文件,保存为图片格式。
(3) 视频
同为二进制文件,保存为视频格式即可。
(4) 其他
只要是能请求到的,都能获取。
7.怎样来解析?
解析方式

8.为什什么我抓到的和浏览器器看到的不一样?
9.怎样解决JavaScript渲染的问题?

10.可以怎样保存数据
以上就是“爬虫基本原理讲解”的全部内容,希望对你有所帮助。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。
