ShardingSphere数据库中间件
分库分表概念:
- 将原来独立的数据库拆分成若干数据库组成;
- 将原来的达标(存储近千万数据的表)拆分成若干个小表;
目的:使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
什么是分库分表
使用索引,缓存等,数据库的压力仍然很大,就需要使用到数据库拆分了,切分的目的就在于减少数据库的负担,缩短查询时间。
分库:从单个数据库拆分成多个数据库的过程,将数据散落在多个数据库中。当整个数据库读写出现性能瓶颈,例如数据库连接数被打满了(MySQL最大连接数默认150),或者并发量太大导致单个数据库已经无法满足日常的读写需求,就需要将整个库拆开。
分表:从单张表拆分成多张表的过程,将数据散落在多张表内。单表数据量非常大,存储和查询的性能就会遇到瓶颈了,如果你做了很多优化之后还是无法提升效率的时候,就需要考虑做分表了。一般千万级别数据量,就需要分表。
分库分表: 单表数据量大,所在库也出现性能瓶颈,就要既分库又分表。

什么时候分库分表
单表行数超过`500万`行或者单表容量超过`2GB`,才推荐进行分库分表。
应该**提前规划分库分表**,如果估算`3`年后,你的表都不会到达这个五百万,则不需要分库分表。分库的时候除了要考虑平时的业务峰值读写QPS外,还要考虑到诸如双11大促期间可能达到的峰值,需要提前做好预估。
一般情况下,单表数据量到达千万级别,就可以考虑分库分表了。具体是否需要分库分表还是要看具体的业务场景,例如流水表、记录表,数据量非常容易到达千万级、亿万级,需要在设计数据库表的阶段就进行分表,还有一些表虽然数据量只有几百万,但字段非常多,而且有很多text、blog格式的字段,查询性能也会很慢,可以考虑分库分表。
数据库拆分策略
业务场景
- 垂直切分
- 业务维度
垂直分割是将一个表按照列的方式拆分成多个表,减少单个表的记录数和列数,提高查询性能。垂直分割一般分为两种: 基于功能分割和基于范式分割。例如,将一个用户表拆分为登录信息表、用户信息表和账户信息

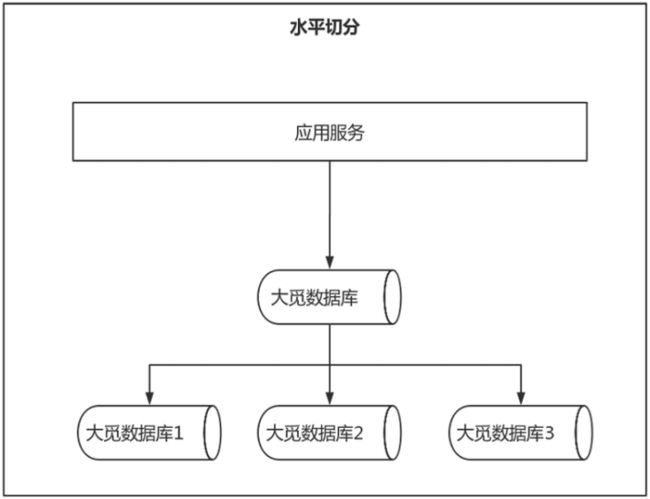
- 水平切分
- 数据维度
水平分割是将一个表按照行的方式拆分成多个表,将数据存储到多个服务器上,提高查询性能。水平分割一般按照主键或按照特定的列进行分割。例如,将一个订单表按照订单号拆分成多个表。
- 混合切分
- 业务+数据
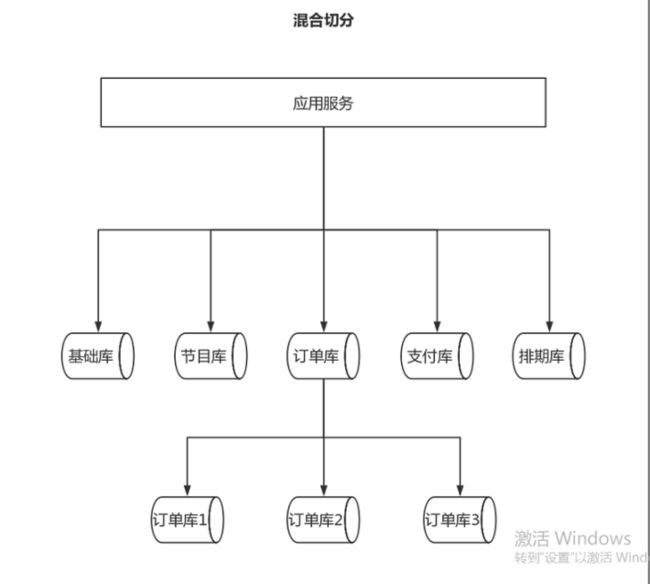
读写分离: 读写分离是将对数据库的读操作和写操作拆分到不同的服务器上,减轻单个数据库的负载压力,提高查询性能。例如,将一个电商网站的读取操作分配到从数据库上,将写操作分配到主数据库上。分片: 分片是将一个大型数据表按照某个维度拆分成多个小的数据表,并将数据存储到多个服务器上。分片一般按照 分片键进行分割,例如,将一个电商网站的订单表按照某个地理位置分割成多个子表。
ShardingSphere简介
Apache ShardingSphere是一款开源的分布式数据库中间件组成的生态圈,它由 Sharding-JDBC、 Sharding-Proxy 和 Sharding-Sidecar (规划中)这 3 款相互独立的产品组成。ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的 计算和存储能力,而并非实现一个全新的关系型数据库。

常用分库分表的工具
在选定了分表字段和分表算法之后,那么,如何把这些功能给实现出来,需要怎么做呢?
我们如何可以做到像处理单表一样处理分库分表的数据呢?这就需要用到一个分库分表的工具了。
目前市面上比较不错的分库分表的开源框架主要有三个,分别是sharding-jdbc、TDDL和Mycat。
1、Sharding-JDBC
现在叫ShardingSphere(Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar这3款相互独立的产品组成)。它定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
开源地址:https://shardingsphere.apache.org
2、TDDL
TDDL 是淘宝开源的一个用于访问数据库的中间件, 它集成了分库分表, 读写分离,权重调配,动态数据源配置等功能。封装 jdbc 的 DataSource给用户提供统一的基于客户端的使用。
开源地址:https://github.com/alibaba/tb_tddl
3、Mycat
Mycat是一款分布式关系型数据库中间件。它支持分布式SQL查询,兼容MySQL通信协议,以Java生态支持多种后端数据库,通过数据分片提高数据查询处理能力。
开源地址:https://github.com/MyCATApache/Mycat2
原文链接:http://t.csdnimg.cn/LPMDI
org.projectlombok
lombok
true
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
4.0.0-RC1
mysql
mysql-connector-java
5.1.44
com.baomidou
mybatis-plus-boot-starter
3.4.0
com.alibaba
druid-spring-boot-starter
1.1.10
server:
port: 80
spring:
shardingsphere:
datasource:
names: ds0,ds1 # 一主一从
ds0:
type: com.alibaba.druid.pool.DruidDataSourcex
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3301/smbms?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC
username: root
password: 123456
# 从数据源
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3302/smbms?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC
username: root
password: 123456
masterslave:
# 读写分离配置
load-balance-algorithm-type: round_robin # 多个从库的负载均衡策略:轮询
# 最终的数据源名称
name: da
# 主库数据源名称
master-data-source-name: ds0
# 从库数据源名称列表,多个逗号分隔
slave-data-source-names: ds1
props:
sql:
show: true #打印SQL
main:
allow-bean-definition-overriding: true #就是允许定义相同的bean对象 去覆盖原有的
mybatis-plus:
type-aliases-package: com.hz.pojo
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: false #驼峰映射
spring:
main:
allow-bean-definition-overriding: true #就是允许定义相同的bean对象 去覆盖原有的
shardingsphere:
datasource:
names: ds0,ds1 # 一主一从
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3301/smbms?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC
username: root
password: 123456
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3302/smbms?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC
username: root
password: 123456
sharding:
tables:
user: # 指定表名,此名必须和model中 @TableName(value = "my_table") 一致
actual-data-nodes: ds$->{0..1}.user$->{1..2} # 创建了两个表,下标0和1 如果在同一数据库下,只做分表 ds0.smbms_bill_$->{1..2}
key-generator:
column: id #主键id
type: SNOWFLAKE #生成策略雪花id
databaseStrategy: #如果只分表,可不设置
inline: # 指定表的分片策略
shardingColumn: id #参与分片运算的列名
algorithmExpression: ds$->{id % 2} #分片算法
# 分表策略
table-strategy:
inline: #指定表的分片策略
sharding-column: id
algorithm-expression: user$->{id%2 + 1} #分片规则
props:
sql:
show: true #打印SQL
mybatis-plus:
type-aliases-package: com.hz.pojo
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: false #驼峰映射
server:
port: 80垂直拆分
spring:
main:
allow-bean-definition-overriding: true #就是允许定义相同的bean对象 去覆盖原有的
shardingsphere:
datasource:
names: ds0,ds1 # 一主一从
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3301/smbms?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC
username: root
password: 123456
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3302/smbms?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC
username: root
password: 123456
sharding:
tables:
user:
actual-data-nodes: ds0.user1 #指定关联的数据库
bill:
actual-data-nodes: ds1.bill1 #指定关联的数据库
props:
sql:
show: true #打印SQL
mybatis-plus:
type-aliases-package: com.hz.pojo
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: false #驼峰映射
server:
port: 80spring:
main:
allow-bean-definition-overriding: true #就是允许定义相同的bean对象 去覆盖原有的
shardingsphere:
datasource:
names: ds0,ds1 # 一主一从
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3301/smbms?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC
username: root
password: 123456
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3302/smbms?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTC
username: root
password: 123456
sharding:
tables:
bill: # 指定表名,此名必须和model中 @TableName(value = "my_table") 一致
actual-data-nodes: ds0.bill$->{1..2} # 创建了两个表,下标0和1
key-generator:
column: id # 主键ID
type: SNOWFLAKE # 生成策略雪花id
# 分表策略
table-strategy:
inline: # 指定表的分片策略
sharding-column: id
algorithm-expression: bill$->{id % 2 + 1} #分片规则
user: # 指定表名,此名必须和model中 @TableName(value = "my_table") 一致
actual-data-nodes: ds0.user$->{1..2} # 创建了两个表,下标0和1
key-generator:
column: id # 主键ID
type: SNOWFLAKE # 生成策略雪花id
# 分表策略
table-strategy:
inline: # 指定表的分片策略
sharding-column: id
algorithm-expression: user$->{id % 2 + 1} #分片规则
masterslave:
# 读写分离配置
load-balance-algorithm-type: round_robin # 多个从库的负载均衡策略:轮询
# 最终的数据源名称
name: da
# 主库数据源名称
master-data-source-name: ds0
# 从库数据源名称列表,多个逗号分隔 至少需要有一个
slave-data-source-names: ds1
props:
sql:
show: true #打印SQL
mybatis-plus:
type-aliases-package: com.hz.pojo
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: false #驼峰映射
server:
port: 80