期末GIS人的《计量地理学》突击复习有救了
前言:
内容知识主要参考徐建华版本的《计量地理学》
每章前部分附有《计量地理学》的思维导图,希望读者在复习背诵的同时梳理出章节框架内容,对整个计量地理学的历史发展及知识框架有整体把握,同时能够与GIS书本上的知识点有补充作用。祝君复习顺利!
笔记整理者:林鑫
文章目录
- 第一章:绪论
-
- 第1节:计量地理学的形成和发展
- 第2节:对计量地理学的评价
- 第3节:计量地理学的应用
- 第二章:地理数据及其采集与预处理
-
-
-
- **(二)描述地理数据分布的离散程度的指标**
-
-
- 第三章:地理模型与地理建模概述(重点)
-
- SEM(结构关系模型)
-
-
- 基本概念
- 结构表示
- 具体结构
-
- GWR(地理加权回归)
-
-
- 定义
-
- 第四章 地理学中的经典统计分析方法
-
- 相关分析(初级)
- 两要素之间
-
- 秩相关系数(两种地理要素的分析方法)
-
- 基本概念
- 线性相关计算及检验(两种地理要素的分析方法)
-
- 计算
- 检验
- 正负相关系数
- 多要素之间
-
- 偏相关系数(**多要素间相关程度**)
-
- 概念
- 原理
- 回归分析(更高级的分析)先相关再回归
-
- 线性回归
- 回归分析
- 自回归分析
- 常见统计概念量
-
-
- 残差平方和(RSS)
- 均方误差(MSE)
- **均方根误差(RMSE)**
- **平均绝对误差(MAE) :Mean Absolute Error**
- 回归平方和(ESS)
- 误差平方和(SSE)
-
- 时间序列分析
-
- 时间序列的自相关性判断
- 时间序列中的自回归分析
- 季节变动的预测方法
-
- **步骤**
- **具体预测**
- 趋势面分析
-
-
- 定义
- 一般原理
- 趋势面模型的适度检验
-
- (一)趋势面拟合适度的R^2R2R^2R2检验
- (二)趋势面拟合适度的显著性F检验
- (三)趋势面适度的逐次检验
-
- 空间分析与经典统计分析
- 地理学第一定律(fig)
- 聚类分析
-
-
- **原理**
- 注意事项
- 直接聚类
-
- 直接聚类的过程,需掌握过程
- 系统聚类分析
-
- **类类距离的选择**
- **类内距离的选择**
- K-Means均值聚类法
-
- 原理
- 步骤
-
- 主成分分析
-
-
- 模型的选择
- 聚类分析与主成分分析两种方法如何组合使用?
-
- 1 主成分分析
- 2 聚类分析
- 3 结合使用
-
- 第五章 空间统计分析初步
-
- 探索性空间统计分析
-
-
- ESDA(探索性空间数据分析)
- 建立空间权重矩阵的规则
-
- **空间自相关**
- 空间关系概念化
-
-
- 概念——理解
- 种类
- 反距离
- 距离范围
- 无差别区域
- K最邻近要素
- (二)**全局空间自相关**
- (三)局部空间自相关
-
- LISA(空间联系的局部指标)
-
- 经典分析在地学研究中的拓展
-
- 地理加权回归
-
- 定义
- 基本原理
- 关于权函数,带宽
- 权函数
- 距离阈值法
- 距离反比法
- Gauss函数法
-
- 带宽
- Gauss函数法
-
- 带宽
第一章:绪论
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-03t1D4g9-1669971282047)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221201173622414.png)]
-
第1节:计量地理学的形成和发展
-
一、现代地理学发展史上的计量运动
-
二、计量地理学的发展阶段
-
三、计量地理学在中国的发展
-
-
第2节:对计量地理学的评价
-
第3节:计量地理学的应用
第二章:地理数据及其采集与预处理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V7QvBDHB-1669971282048)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221202114358901.png)]
-
第1节:地理数据的类型
-
一、空间数据
-
二、属性数据
-
(一)数量标志数据
-
(二)品质标志数据
-
-
-
第2节:地理数据的基本特征
-
一、数量化、形式化与逻辑化
-
二、不确定性
-
三、多种时空尺度
-
四、多样性
-
-
第3节:地理数据的采集与处理
-
一、地理数据的采集
-
二、地理数据的处理
-
-
第4节:地理数据的统计预处理
-
一、统计整理
-
基本步骤
-
(一)统计分组
-
(二)计算各组数据的频数、频率,编制统计分组表
-
(三)作分布图
-
-
-
二、几种常用的统计指标与参数
-
(一)描述地理数据一般水平的指标
-
平均数
-
中位数
-
众数
-
-
(二)描述地理数据分布的离散程度的指标
-
极差
- 所有数据中最大值与最小组之差
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eBLjPujB-1669971282048)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221202114558318.png)]
-
离差
- 每一个地理数据与平均值的差
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QRwUG4HH-1669971282048)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221202114604612.png)]
-
离差平方和
- 总体上衡量一组地理数据与平均值的离散程度
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MPNxYFrF-1669971282049)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221202114612916.png)]
-
方差与标准差
-
从平均概况衡量一组地理数据与平均值的离散程度
-
其中方差是均方差的简称
方差
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ouMHGaHN-1669971282049)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221202114710745.png)]
标准差
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7Jpf3QIZ-1669971282049)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221202114718002.png)]
-
-
变异系数
-
表示了地理数据的相对变化(波动)程度
-
-
-
-
(三)描述地理数据分布特征的参数
-
偏度系数
-
测度了地理数据分布的不对称性情况,刻画了以平均值为中心的偏向情况
-
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8wHVPkUP-1669971282050)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221202114757905.png)]
-
-
峰度系数
- 测度了地理数据在均值附近的集中情况
-
-
-
-
-
三、变异系数的应用实例
-
-
第5节:地理数据分布的集中化与均衡度指数
地理现象的分布格局,常常用地理数据分布的集中化程度与均衡度来描述
-
一、洛伦兹曲线与集中化指数
-
洛伦兹曲线
累积频率曲线研究工业化的集中化程度
洛伦兹曲线的上凸程度代表部门集中化程度 -
集中化指数
范围在[0,1]
-
-
二、基尼系数(Gini coefficient)
洛伦兹曲线与集中化指数不能满足,对两组数据的进一步对比分析 -
三、锡尔系数(Theil,锡尔熵)
除了基尼系数之外,也可以用基尼系数来进一步定量化描述数据
-
第三章:地理模型与地理建模概述(重点)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YTpeqgc2-1669971282050)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221201173542903.png)]
SEM(结构关系模型)
基本概念
观测变量
可直接测量的变量,通常是指标潜在变量无法直接观测并测量的变量。
潜变量
需通过设计若干指标间接加以测量。
外生变量
指那些在模型或系统中,只起解释变量作用的变量。它们在模型或系统中,只影响其他变量,而不受其他变量的影响。在路径图中,只有指向其他变量的箭头,没有箭头指向它的变量均为外生变量
内生变量
是指那些在模型或系统中,受模型或系统中其它变量包括外生变量和内生变量影响的变量,即在路径图中,有箭头指向它的变量。它们也可以影响其它变量。
结构表示

具体结构
GWR(地理加权回归)
定义
这里只引入概念,在第五章 空间统计分析初步中详细解释
第四章 地理学中的经典统计分析方法
经典分析包括以下内容
相关分析(初级)
关系图
两要素之间
秩相关系数(两种地理要素的分析方法)
基本概念
秩相关系数(Coefficient of Rank Correlation),又称等级相关系数,是将两要素的样本值按数据的大小顺序排列位次,以各要素样本值的位次代替实际数据而求得的一种统计量。它是反映等级相关程度的统计分析指标,
常用的等级相关分析方法有Spearman相关系数和Kendall秩相关系数等。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xmOV4dCW-1669971282050)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221201174924390.png)]
线性相关计算及检验(两种地理要素的分析方法)
地理模型可以分为线性模型和非线性模型
计算
检验
正负相关系数
多要素之间
偏相关系数(多要素间相关程度)
概念
原理
通常采用双侧t检验
回归分析(更高级的分析)先相关再回归
线性回归
回归分析
自回归分析
为什么要进行
常见统计概念量
残差平方和(RSS)
这里对象主要是回归
统计学上把数据点与它在回归直线上相应位置的差异称为残差,把每个残差平方之后加起来 称为残差平方和(相当于实际值与预测值之间差的平方之和)
残差平方和是在[线性]模型中衡量模型拟合程度的一个量
均方误差(MSE)
这里主要对象是参数
均方误差是指参数估计值与参数真值之差平方的期望值
在样本量一定时,评价一个点估计的好坏标准使用的指标总是点估计与参数真值 的距离的函数
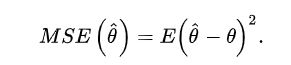
均方根误差(RMSE)
均方根误差亦称标准误差
均方误差:均方根误差是均方误差的算术平方根

平均绝对误差(MAE) :Mean Absolute Error
平均绝对误差是绝对误差的平均值,平均绝对误差能更好地反映预测值误差的实际情况

回归平方和(ESS)
因变量回归值ŷ-因变量平均值y的离差平方和
回归平方和ESS (Explained Sum of Squares)是因变量回归值ŷ-因变量平均值y的离差平方和,数值上=∑(ŷ-ȳ)2,也称为解释平方和。用回归方程或回归线来描述变量之间的统计关系时,实验值yi与按回归线预测的值ŷ并不一定完全一致。ESS越大说明多元线性回归线对样本观测值的拟合情况越好。
回归平方和ESS是总偏差平方和(总离差平方和)TSS与残差平方和之差RSS,ESS= TSS-RSS。
其中,TSS=∑(yi-ȳ)2=∑(u)2,其中ȳ是各实验值yi的平均值,u=y-ŷ;RSS=∑(yi-ŷ)2。
ESS=R²×TSS,R²为可决系数(亦称确定系数)。 [1]
误差平方和(SSE)
比如在k-means中有应用
误差平方和又称[残差平方和]、[组内平方和]等(Sum of the Squared Errors),根据n个观察值拟合适当的模型后,余下未能拟合部份(ei=yi一y平均)称为残差,其中y平均表示n个观察值的平均值,所有n个残差平方之和称误差平方和。在回归分析中通常用SSE表示,其大小用来表明函数拟合的好坏。将残差平方和除以自由度n-p-1(其中p为自变量个数)可以作为误差方差σ2的无偏估计,通常用来检验拟合的模型是否显著。
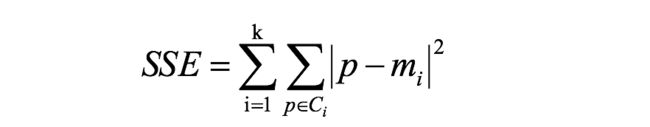
时间序列分析
时间序列的自相关性判断
具体过程
时间序列中的自回归分析
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MDR37q5l-1669971282051)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221201180034264.png)]
季节变动的预测方法
步骤
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YfKnNogX-1669971282051)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221201174352074.png)]
具体预测
趋势面分析
趋势面有哪些模型
-
定义
- 利用数学曲面模拟地理系统要素在空间上的分布及变化趋势的一种数学方法
本质是通过回归分析原理,运用最小二乘法(OLS)拟合一个二维非线性函数,模拟地理要素在空间上的分布规律,展示地理要素在地域空间上的变化趋势
- 利用数学曲面模拟地理系统要素在空间上的分布及变化趋势的一种数学方法
-
一般原理
趋势面是一种抽象的数学曲面,抽象并过滤掉了一些局域随机因素的影响,使地理要素的空间分布规律明显化
-
实际的地理曲面分解为趋势面和剩余面两部分
-
趋势面是确定性因素作用的结果,而剩余面是随机因素作用的结果
-
(一)趋势面模型建立
- 计算趋势面的数学方程式有多项式函数和傅里叶级数
-
(二)趋势面模型的参数估计
- 实际上是对非线性回归系数的估计
利用最小二乘法来给出多项式系数的最佳线性无偏估计
- 实际上是对非线性回归系数的估计
-
-
趋势面模型的适度检验
趋势面分析拟合程度与回归模型的效果直接相关
-
(一)趋势面拟合适度的R2R2R2R2检验
说人话就是评价当前模型到底有多合适
-
用来比较趋势面与实际面的拟合程度
-
R²最大值为1。R²的值越接近1,说明回归直线对观测值的拟合程度越好;
-
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hk3QVoqY-1669971282051)(https://api2.mubu.com/v3/document_image/8bd2f638-9f55-42af-a826-8fb8d735e5bc-12988243.jpg)]
-
-
(二)趋势面拟合适度的显著性F检验
说人话就是比较评价当前模型是否符合要求
-
趋势面拟合适度的检验,是对趋势面回归模型整体的显著性检验,
-
即判断拟合结果是否具有可信度以及具有多大的置信区间。
-
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9s1Tz3xa-1669971282052)(https://api2.mubu.com/v3/document_image/76e1f061-e740-4bec-b87d-7cf3f5d5e9b9-12988243.jpg)]
-
-
(三)趋势面适度的逐次检验
说人话就是比较不同模型之间哪个更好
- 对相继的两个阶次趋势面模型的适度性进行比较,为此求出较高次多项式方程的回归平方和与较低次多项式方程的回归平方和之差
-
空间分析与经典统计分析
地理学第一定律(fig)
「地理学第一定律」:任何事物之间都是空间相关的,距离越近的事物之间的空间相关性越大。
相应的还有地理学第二定律等,这里不做深究,读者知道即可
聚类分析
原理
注意事项
直接聚类
直接聚类的过程,需掌握过程
直接聚类法是一.种简便的聚类方法,它利用距离矩阵进行,是一种基于分层的聚类方法
其基本思想为:
先把各个分类对象单独视为-类, 然后根据距离最小的原则,依次选出一-对分类对象, 合并成新类;如果其中-一个分类对象已归于某一类, 则把另一个也归入该类;如果- -对分类对象正好分别属于已归的两类,则把这两类并为一类.每一次归并,都在距离矩阵中划去该对
象所在的行和相应的列.
若分类对象的总数为N,则按照上述步骤,经过N- 1次就可以把全部分类对象归为一类.此外,根据归并的先后顺序,我们还可以做出聚类分析的谱系图.
具体过程
务必掌握:https://blog.csdn.net/chengyq116/article/details/87391847
系统聚类分析
常用的聚类方法——系统聚类
遥感上也有,isodata算法
-
又称群分析或点群分析,研究多要素事物分类问题的数量方法
-
常见方法
-
系统聚类法
-
模糊聚类法
-
动态聚类法
-
类类距离的选择
类内距离的选择
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-47ML5HIR-1669971282052)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221201180115742.png)]
K-Means均值聚类法
原理
K-Mean算法,即 K 均值算法,是一种常见的聚类算法。算法会将数据集分为 K 个簇,每个簇使用簇内所有样本均值来表示,将该均值称为“质心”。
步骤
主成分分析
模型的选择
-
第6节:#主成分分析
用较少的变量代替原来较多的变量
-
一、主成分分析的基本原理
-
解释
-
把原来多个变量划为少数几个综合指标的一种统计分析方法(数据降维技术)
-
即用较少的综合指标代替原来较多的变量指标,使较少的综合指标能较多反映原来信息(且独立)
-
最简单形式:原来变量的线性组合
-
-
原则
减少数目,抓住主要矛盾,简化关系
-
①新变量相互无关
-
②Z_1Z1Z_1Z1是一切线性组合中方差最大者(贡献最大,第一主成分)
-
-
-
二、主成分分析的计算步骤
-
(1)计算相关系数矩阵
-
(2)计算特征值与特征向量
这里要用到雅克比行列式来进行变量代换
-
(3)计算主成分贡献率及累积贡献率
-
(4)计算主成分载荷(也就是占比)
-
-
聚类分析与主成分分析两种方法如何组合使用?
1 主成分分析
主要思想在进行高维数据系统分析时,通过主成分分析,可以在纷繁的指标变量描述下,了解影响这个系统存在与发展的主要因素。
主成分分析是研究如何通过少数几个主成分来解释多变量的方差的分析方法,也就是求出少数几个主成分,使他们尽可能多地保留原始变量的信息,且彼此不相关它是一种数学变换方法,
即把给定的一组变量通过线性变换,转换为一组不相关的变量,在这种变换中保持变量的总方差不变,同时具有最大总方差,称为第一主成分;具有次大方差,成为第二主成分。依次类推。
2 聚类分析
是主要思想聚类分析又称为群分析,是一种对指标或者样本进行分类的多元统计方法,是将数据分类到不同的簇当中,使得同一个簇之间的样本具有较大的相似程度,不同的簇之间相似度较低。
从机器学习的层面上分析,聚类是搜索簇的无监督学习过程,其并不依赖带有类别标记的训练集实例,而是需要聚类算法自动标记类别,属于观察式学习范畴。分类技术在不同的领域都有着一定的贡献,用于数据描述、衡量数据源之间的相似性和数据源分类。
3 结合使用
SPSS主成分分析的结果是可以直接用来做聚类分析哈,做聚类分析是需要将数据归一化处理的,以保证数据的可比性。
第五章 空间统计分析初步
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4sduL6PQ-1669971282052)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221202121416904.png)]
探索性空间统计分析
ESDA(探索性空间数据分析)
-
一、探索性空间统计分析的基本原理
-
(一)空间权重矩阵
为了揭示现象之间的空间联系,首先需要定义空间对象的相互邻接关系
空间权重矩阵是**空间统计分析与经典统计分析**的重要区别之一[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EhLjUyUR-1669971282053)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221202121704816.png)]
如上图定义了一个空间权重矩阵W,描述了n个个体之间的空间依赖关系。
即描述了空间个体之间的相互影响程度
-
建立空间权重矩阵的规则
规则有很多,以下为常用的两种
-
①简单的二进制邻接矩阵
-
-
②基于距离的二进制空间权重矩阵
-
-
-
-
空间自相关
空间关系概念化
概念——理解
Conceptualization of Spatial Relationships你即可以直接翻译为概念化,也可以理解为:空间关系的形象化描述信息。通俗的说,就是在进行分析之前,需要对你的空间关系,进行一个定义。常见的空间关系概念化包括了距离、时间、区域、邻近、邻接等,具体使用哪个,取决于要测量和分析的对象是什么。
种类
-
反距离
如果选择的是“反距离”这种方式的话,空间关系的概念模型就表示为一种阻抗或者是距离衰减。按照地理学第一定律,任何要素都会影响其他的要素,但是距离越远,影响就越小。所以使用反距离这个概念,即:随着距离的增大,影响就会减少。通常使用距离这个概念来描述空间关系的话进行分析的话,还会去设定一个距离范围,或者说阈值,这样可以减少所需要的计算数(特别是对于大型数据集而言,至关重要)。
-
距离范围
对于某些研究,比如热点分析,使用固定的距离是默认的空间关系的概念化。什么叫固定距离呢?就是在同等距离范围内的所有要素,都认为每个事件对我的影响是同等的。
比如我要研究的是小区居民对周边商业的影响,那么固定距离就是这个小区的范围。在小区里面居住的所有居民,无论是住在小区的中心,还是住在小区最角落里面的那栋楼,都对我的研究时候所产生的影响是一样的。
-
无差别区域
这个名词和翻译,总是让人感觉到怪怪的,但是实际上确很简单,其的意思就是“在一定的区域内,实行无差别化;超出这个区域,就实行距离衰减化”,其实就是把“反距离”和“固定距离范围”两个模型合二为一了。
在进行无差别的区域建模的时候,首先设定一个区域,这个区域以内的所有事件要素都设为同样的权重(固定距离);超出这个区域之后,所有的事件要素的影响权重就开始衰减(反距离)。
-
K最邻近要素
所谓的K最近相邻,就是指在一定的范围内,都算相邻的要素,这个概念是“距离范围”模型改良之后生成的。距离范围是以一定距离为阈值,而这个模型是以要素的个数为阈值的。
这种模型的优点,在于它可以确保每个目标要素都能找到相邻的要素,特别是在一些在研究区域内,要素分布非常不均匀的,密度差别非常大的情况下,也能保证有相邻要素的存在。
-
-
(二)全局空间自相关
Moran指数IIII和Geary系数CCCC是两个用来度量空间自相关的全局指标
Moran指数反映的是空间邻接或空间邻接的区域单元属性值的相似程度,而Geary系数与Moran指数存在负相关关系-
Moran指数IIII
-
取值一般为-1~1
-
对于Moran指数,可以用标准化统计量Z来检验n个区域是否存在空间自相关关系
Z是一般是否满足关系的检验指标
-
-
Geary系数CCCC
- 取值一般为0~2
-
-
(三)局部空间自相关
Moran指数IIII和Geary系数CCCC对空间自相关做了全局评估,但忽略了空间过程的潜在不稳定性问题
如果进一步考虑是否存在观测值的高低或低值的局部空间聚集等问题就需要考虑局部空间自相关
虽然上空间总体上有这层关系,但是局部的话可能有突变(局部空间聚集),所以要再单独考虑局部空间数据的自相关性,由此引出局部空间自相关理论-
具体分类
-
LISA(空间联系的局部指标)
local indicators of spatial association
LISA考虑到了全局指标moran指数的分解,分解到每个值的贡献(局部moran)
局部Moran指数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wPkjytHN-1669971282053)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221202165347977.png)]
- 局部Geary指数
用来探索空间联系
-
G统计
如果全局统计量不足以证明存在空间联系时(退而求其次解决),一般使用局部G统计量来探测区域单元的观测值在局部水平上的空间聚集程度
- 使用局部G统计量来探测区域单元的观测值在局部水平上的空间集聚程度
-
Moran散点图
-
研究局部的空间不稳定性,它是对空间滞后因子W_zWzW_zWz和z数据可视化的二维图示
-
具有四个象界
分别对应于区域单元与其邻居直接的四种类型的局部空间联系形式
-
-
-
-
经典分析在地学研究中的拓展
SEM和GWR
**结构方程模型(struc tural equation modeling, SEM) *研究地理要素因果关系、路径分析、因子分析、方差分析的综合手段
**地理加权回归(Geographical weighted regression,GWR) *研究地理要素空间可视关系、空间模式,空间异质性规律的有效手段
地理加权回归
定义
地理加权回归(Geographically weighted regression, GWR)是一种空间分析技术,广泛应用于地理学及涉及空间模式分析的相关学科。GWR通过建立空间范围内每个点处的局部回归方程,来探索研究对象在某一尺度下的空间变化及相关驱动因素,并可用于对未来结果的预测。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8BZxFdOS-1669971282053)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221202124722076.png)]
基本原理
传统的ols(最小二乘模型)里面式子没有考虑到空间关系,而GWR考虑到了地理位置的影响(即加入了关于地理位置的函数)
GWR具体形式如下
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vns54q0B-1669971282054)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221202124330388.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8dHtsH2X-1669971282054)(C:\Users\林大王\AppData\Roaming\Typora\typora-user-images\image-20221202124404398.png)]
而** β k ( u i , v i ) β_k(u_i,v_i) βk(ui,vi)**是关键,它的估算就要用到权函数
关于权函数,带宽
权函数
GWR模型的核心是空间权重矩阵,其选取的适当与否对回归参数的正确估计至关重要,比较常见的空间权函数有:1.距离阈值法;2.距离反比法;3.Gauss函数法等
距离阈值法
距离阈值法是最简单的权函数选取方法,其关键是选取合适的距离阈值D与dij进行对比,若大于阈值则权重为0,否则为1,形式如下:
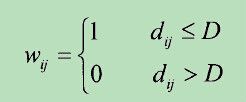
距离反比法
假定空间相近的地物比较远的地物具有更强的相关性,基本形式为:

Gauss函数法
基本思想是通过选取一个连续单调递减函数表示权重与距离之间的关系,以此来克服以上两种方法的缺点。函数形式如下:

式中b是描述权重与距离之间函数关系的非负数衰减参数,称为带宽。带宽越大,权重随距离增加衰减得越慢,反之则权重衰减得越快。
带宽
带宽是核函数中高斯函数法中的
非负数衰减参数
描述权重与距离之间函数关系的非负数衰减参数,称为带宽**。带宽越大,权重随距离增加衰减得越慢,反之则权重衰减得越快。
常用的最优窗宽选取准则有CV交叉验证确认方法以及AICc信息准则。
-
交叉确认方法(Cross-validation (CV) criterion)
-
AICc信息准则(Corrected Akaike information criterion (AICc))
ma&fromModule=lemma_content-image&ct=single)
Gauss函数法
基本思想是通过选取一个连续单调递减函数表示权重与距离之间的关系,以此来克服以上两种方法的缺点。函数形式如下:
式中b是描述权重与距离之间函数关系的非负数衰减参数,称为带宽。带宽越大,权重随距离增加衰减得越慢,反之则权重衰减得越快。
带宽
带宽是核函数中高斯函数法中的
非负数衰减参数
描述权重与距离之间函数关系的非负数衰减参数,称为带宽**。带宽越大,权重随距离增加衰减得越慢,反之则权重衰减得越快。
常用的最优窗宽选取准则有CV交叉验证确认方法以及AICc信息准则。
-
交叉确认方法(Cross-validation (CV) criterion)
-
AICc信息准则(Corrected Akaike information criterion (AICc))