图像分割实战-系列教程13:deeplabV3+ VOC分割实战1-------项目介绍与参数解析
图像分割实战-系列教程 总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在Pycharm中进行
本篇文章配套的代码资源已经上传
deeplab系列算法概述
deeplabV3+ VOC分割实战1
deeplabV3+ VOC分割实战2
deeplabV3+ VOC分割实战3
deeplabV3+ VOC分割实战4
deeplabV3+ VOC分割实战5
1、项目介绍
1.1 VoC2012数据集介绍
Visual object classes challenge 2012,一般简称VoC2012,一个非常经典的数据集,很多论文都使用它,分类检测分割任务都有用这个数据集
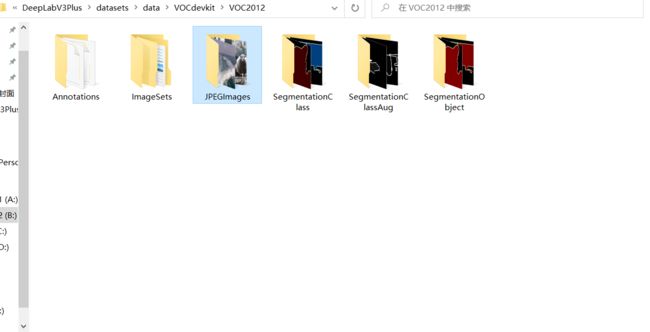

如图所示,在我们已经上传的项目中,我已经下载了这个数据集,voc2012中包含,6个文件夹,其中JPEGImages是包含了很多张的图像,一共有17125张图像,这是我们所有的数据。而Annotations文件夹就是包含了这17125张图像对应的标签数据,全部都是xml文件:
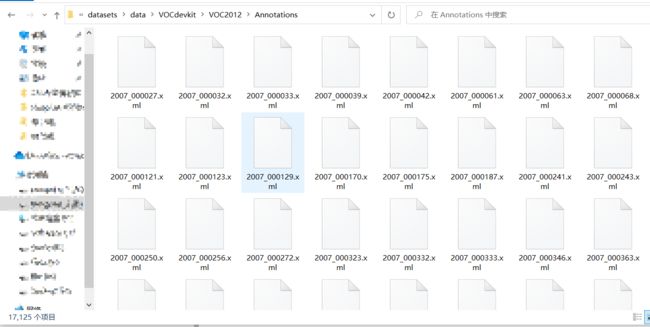

我们的任务主要是图像分割,使用的是VOC2012文件夹中的SegmentationClassAug文件夹的数据:

1.2 项目介绍
本项目包含10个文件(夹),以本文上传的项目为准:
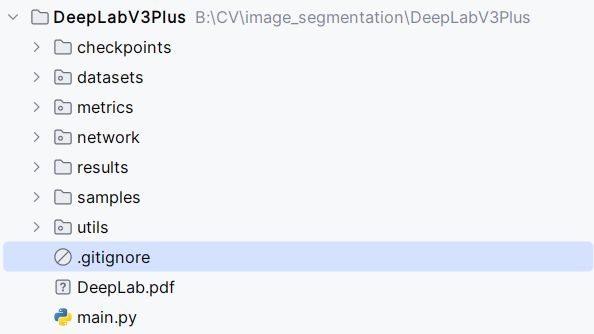
- 运行的文件就是main.py,执行训练和验证都是main.py,只不过训练和验证的配置参数不同
- DeepLab.pdf,介绍DeepLabv3+的ppt
- checkpoint文件夹是保存的模型文件
- datasets文件夹,保存了所有的数据、标签、以及处理数据的代码
- metrics文件夹,评价指标的代码
- network文件夹,构建网络的代码
- results文件夹,训练部分结果得到的图像
- samples文件夹,验证部分结果得到的图像
- utils文件夹,可视化、损失计算、学习率调度策略等代码
- .gitignore文件,是一个文本文件,告诉Git 要忽略项目中的哪些文件或文件夹
2、项目参数
def get_argparser():
parser = argparse.ArgumentParser()
# Datset Options
parser.add_argument("--data_root", type=str, default='./datasets/data',
help="path to Dataset")
parser.add_argument("--dataset", type=str, default='voc',
choices=['voc', 'cityscapes'], help='Name of dataset')
parser.add_argument("--num_classes", type=int, default=None,
help="num classes (default: None)")
- data_root:数据位置
- dataset:deeplabv3+有两个数据集,这里默认就是我们的voc
- num_classes:类别,一共有21类
# Deeplab Options
parser.add_argument("--model", type=str, default='deeplabv3plus_mobilenet',
choices=['deeplabv3_resnet50', 'deeplabv3plus_resnet50',
'deeplabv3_resnet101', 'deeplabv3plus_resnet101',
'deeplabv3_mobilenet', 'deeplabv3plus_mobilenet'], help='model name')
parser.add_argument("--separable_conv", action='store_true', default=False,
help="apply separable conv to decoder and aspp")
parser.add_argument("--output_stride", type=int, default=16, choices=[8, 16])
- model:特征提取网络的选择,根据任务来,可以选择复杂的速度就会慢,mobilenet就相对比较简易的网络,分别都有对应的3和3+版本
- separable_conv:部署剪枝用的参数
- output_stride:输出通道
# Train Options
parser.add_argument("--test_only", action='store_true', default=False)
parser.add_argument("--save_val_results", action='store_true', default=False,
help="save segmentation results to \"./results\"")
parser.add_argument("--total_itrs", type=int, default=30e3,
help="epoch number (default: 30k)")
parser.add_argument("--lr", type=float, default=0.01,
help="learning rate (default: 0.01)")
parser.add_argument("--lr_policy", type=str, default='poly', choices=['poly', 'step'],
help="learning rate scheduler policy")
parser.add_argument("--step_size", type=int, default=10000)
parser.add_argument("--crop_val", action='store_true', default=False,
help='crop validation (default: False)')
parser.add_argument("--batch_size", type=int, default=16,
help='batch size (default: 16)')
parser.add_argument("--val_batch_size", type=int, default=4,
help='batch size for validation (default: 4)')
parser.add_argument("--crop_size", type=int, default=513)
parser.add_argument("--ckpt", default=None, type=str,
help="restore from checkpoint")
parser.add_argument("--continue_training", action='store_true', default=False)
parser.add_argument("--loss_type", type=str, default='cross_entropy',
choices=['cross_entropy', 'focal_loss'], help="loss type (default: False)")
parser.add_argument("--gpu_id", type=str, default='0',
help="GPU ID")
parser.add_argument("--weight_decay", type=float, default=1e-4,
help='weight decay (default: 1e-4)')
parser.add_argument("--random_seed", type=int, default=1,
help="random seed (default: 1)")
parser.add_argument("--print_interval", type=int, default=10,
help="print interval of loss (default: 10)")
parser.add_argument("--val_interval", type=int, default=100,
help="epoch interval for eval (default: 100)")
parser.add_argument("--download", action='store_true', default=False,
help="download datasets")
训练参数:
- test_only:模型仅在测试模式下运行,跳过训练
- save_val_results:是否需要保留结果
- total_itrs:迭代次数,epochs
- lr:学习率
- lr_policy:学习率衰减
- step_size:设置学习率变化的频率
- crop_val:是否需要对验证集进行裁剪
- batch_size:batch_size根据自己的gpu资源选择
- val_batch_size:验证集batch_size
- crop_size:输入图像裁剪的大小(默认为513x513像素)
- ckpt:checkpoint,检查点,是模型训练过程中的一个保存状态,使得训练过程可以在中断后从相同的状态恢复,而不是从头开始。这在长时间训练、遇到硬件故障或需要使用资源进行其他任务时特别有用
- continue_training:设置True将从最后一个检查点继续训练
- loss_type:指定用于训练的损失函数类型。选项有’cross_entropy’(交叉熵)和’focal_loss’(焦点损失)
- gpu_id:标识用于训练的GPU,一般填0就可以了,除非你有多个显卡
- weight_decay:学习率衰减
- random_seed:随机种子
- print_interval:打印训练损失的频率
- val_interval:训练期间执行验证的频率
- download:设置True将自动下载所需的数据集
# PASCAL VOC Options
parser.add_argument("--year", type=str, default='2012',
choices=['2012_aug', '2012', '2011', '2009', '2008', '2007'], help='year of VOC')
# Visdom options
parser.add_argument("--enable_vis", action='store_true', default=False,
help="use visdom for visualization")
parser.add_argument("--vis_port", type=str, default='13570',
help='port for visdom')
parser.add_argument("--vis_env", type=str, default='main',
help='env for visdom')
parser.add_argument("--vis_num_samples", type=int, default=8,
help='number of samples for visualization (default: 8)')
return parser
可视化展示:
- year:数据集选项,指定使用哪个年份的PASCAL VOC数据集
- enable_vis:启用或禁用Visdom进行可视化
- vis_port:参数定义了Visdom服务器监听的端口号
- vis_env:管理不同项目或实验可视化的方式
- vis_num_samples:可视化时要展示的样本数量
deeplab系列算法概述
deeplabV3+ VOC分割实战1
deeplabV3+ VOC分割实战2
deeplabV3+ VOC分割实战3
deeplabV3+ VOC分割实战4
deeplabV3+ VOC分割实战5