Making Large Language Models Perform Better in Knowledge Graph Completion论文阅读
文章目录
- 摘要
- 1.问题的提出
-
- 引出当前研究的不足与问题
-
- KGC方法
- LLM幻觉现象
- 解决方案
- 2.数据集和模型构建
-
- 数据集
- 模型方法
-
- 基线方法
- 任务
- 模型方法
-
- 基于LLM的KGC的知识前缀适配器
-
- 知识前缀适配器
- 与其他结构信息引入方法对比
- 3.实验结果与分析
-
- 结果分析:
- 可移植性实验:
- 消融实验
- 4.结论与启示
-
- 结论总结
-
- 局限性
- 启发

原文链接: Making Large Language Models Perform Better in Knowledge Graph Completion
摘要
基于大语言模型(LLM)的知识图补全(KGC)旨在利用 LLM 预测知识图谱中缺失的三元组,并丰富知识图谱,使其成为更好的网络基础设施,这可以使许多基于网络的自动化服务受益。然而,基于LLM的KGC研究有限,缺乏对LLM推理能力的有效利用,忽略了KG中的重要结构信息,阻碍了LLM获取准确的事实知识。在本文中,论文中讨论如何将有用的知识图谱结构信息融入到LLM中,旨在实现LLM中的结构感知推理。论文中首先将现有的LLM范式转移到结构感知设置,并进一步提出知识前缀适配器(KoPA)来实现这一既定目标。 KoPA 采用结构embedding预训练来捕获知识图谱中实体和关系的结构信息。然后,KoPA 通知 LLM 知识前缀适配器,该适配器将结构embedding投影到文本空间中,并获取虚拟知识标记作为输入提示的前缀。论文中对这些基于结构感知的 LLM 的 KGC 方法进行了全面的实验,并进行了深入的分析,比较了结构信息的引入如何更好地提高 LLM 的知识推理能力。
KEYWORDS
Knowledge Graphs, Knowledge Graph Completion, Triple Classification, Large Language Models, Instruction Tuning
1.问题的提出
引出当前研究的不足与问题
KGC方法
知识图补全(KGC)其目的是挖掘给定不完整知识图谱中缺失的三元组。KGC包含几个子任务,例如三元分类、实体预测和关系预测
主流的KGC方法: 基于embedding的方法和基于PLM的方法
– 基于embedding:充分利用知识图谱的结构信息,忽略了 KG 中的文本信息
– 基于PLM:利用了PLM的强大功能,但将训练过程变成基于文本的学习,很难捕获知识图谱中的复杂结构信息。
LLM幻觉现象
LLM对细粒度的事实知识记忆力不足,会导致幻觉现象。因此,将KG信息融入到提示中,提供更多的辅助信息,引导LLM进行结构感知推理,是实现优秀的基于LLM的KGC的关键。
(LLM4KGC)中的应用,目前缺乏仔细的研究
在本文中,论文中将探讨如何将知识图谱中的复杂结构信息融入到LLM中,以实现更好的知识图补全推理能力。
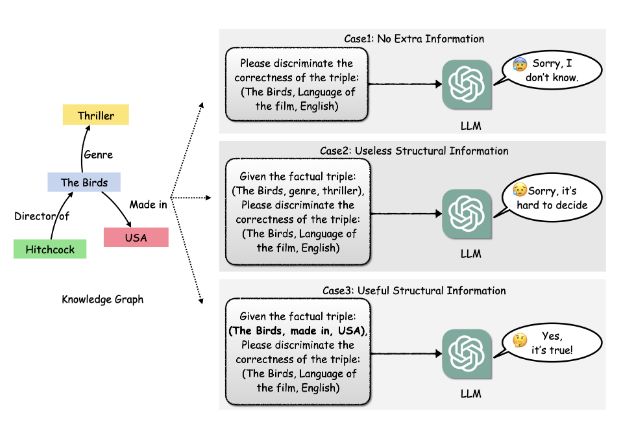
图 1:基于 LLM 的 KGC 的简单案例。描述实体周围信息的有用结构信息可以作为辅助提示,指导LLM做出正确的决策。
解决方案
已有的LLM4KGC的方法往往是通过指令微调的方式,构造提示词模版将一条条的三元组输入大模型中对大模型进行微调,来训练出能够完成KGC任务的LLM,但是这样的方法没有充分利用KG中存在的复杂结构信息,导致LLM无法充分地理解知识图谱中的结构信息,从而限制了LLM解决KGC问题的能力。围绕如何在LLM中引入KG结构信息这一个问题,
该文章做出了如下几点贡献:
-
论文探究了在常见的LLM范式(不需要训练的上下文学习方法和需要训练的指令微调(in-context learning (ICL) and instruction tuning (IT)))基础上如何引入知识图谱的结构信息,分别提出了一种结构增强的上下文学习方法和结构增强的指令微调方法
-
论文提出了一种知识前缀适配器(Knowledge Prefix Adapter, KoPA),将KG中提取的结构知识通过一个适配器映射到大模型的文本token表示空间中,并和三元组的文本一起进行指令微调,使得LLM能够充分理解KG中的结构信息,并在结构信息的辅助下完成知识图谱的推理。
-
论文进行了大量的实验,来验证了论文中提出的多种方法的性能,探索最合理的结构信息引入方案。
2.数据集和模型构建
数据集
论文中使用三个公共 KG 基准 UMLS、CoDeX-S 和 FB15K-237N来评估所提出的基于 LLM 的 KGC 方法的能力。
模型方法
基线方法
基于embedding的方法、基于PLM的方法和基于LLM的方法。
- 基于embedding的 KGC 方法。TransE、DistMult、ComplEx 和 RotatE
- 基于 PLM 的 KGC 方法。KG-BERT和PKGC
- 基于 LLM 的 KGC 方法。KGLLaMA ,ZSR、ICL、IT和结构感知IT(增强IT)
进一步将基于LLM的方法分为两类:免训练方法和微调方法。Trainingfree方法包括ZSR和ICL(零样本推理和上下文学习),其余都是finetuning方法。
任务
三元组分类任务,区分三元组 (h, r, t) 是真还是假
使用准确率、精确率、召回率和F1分数作为评价指标。
模型方法
论文首先提出了结构增强的上下文学习和指令微调方法,通过将输入的三元组的局部结构信息通过文本描述的方式添加到指令模版中,实现结构信息的注入。
基于LLM的KGC的知识前缀适配器
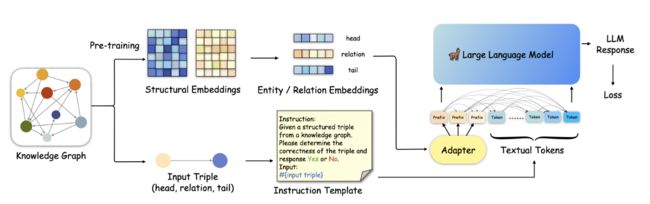
图 2:论文中的知识前缀适配器 (KoPA) 概述。 KoPA 是一个基于 LLM 的两阶段 KGC 框架。 KoPA 首先对给定 KG 中的实体和关系进行结构embedding预训练。然后 KoPA 使用指令调整来微调 LLM。给定输入三元组的结构embedding将由适配器投影到LLM的文本标记空间中,并作为输入提示序列前面的一串前缀,也称为虚拟知识标记。利用仅解码器LLM的单向注意力机制,这些虚拟知识标记将被后续的文本标记看到,这将允许LLM在结构感知状态下解码指令的答案。
另一方面,论文中提出的知识前缀适配器(KoPA)的主要设计方案如上图所示,首先KoPA 通过结构特征的预训练提取知识图谱中实体和关系的结构信息 ,之后,KoPA通过一个设计好的 适配器,将输入三元组对应的结构特征投影到大语言模型的文本表示空间中,然后放置于输入prompt的最前端,让输入的提示词模版中的每个token都能“看到”这些结构特征,然后通过微调的Next Word Prediction目标对LLM的训练。
- 对给定 KG 中的实体和关系进行结构embedding预训练
- 然后 KoPA 使用指令调整来微调 LLM
- 给定输入三元组的结构embedding将由适配器投影到LLM的文本标记空间中,并作为输入提示序列前面的一串前缀,也称为虚拟知识标记。
知识前缀适配器
LLM无法理解(h,r,t)的embedding,所以应用知识前缀适配器P将他们投影到M的文本标记表示空间中
通过P转换为多个虚拟知识标记
S = K ⊕ I ⊕ X
K = P () ⊕ P () ⊕ P ()
指令提示I是人工准备的指导LLM M执行KGC任务的指令
X(ℎ, , ) = D (ℎ) ⊕ D ( ) ⊕ D ()
由于单向性,后面的所有文本标记都可以看到带有前缀 K 的文本标记 (通过这样做,文本标记可以单向关注输入三元组的结构embedding)
与其他结构信息引入方法对比
论文对不同的结构信息引入方案进行了对比,对比的结果如下:

表 1:基于 LLM 的 KGC 方法三种方式的比较。对于提示长度分析,LI、LT分别表示指令提示和三元组提示的长度。 LD 表示演示的长度,k 是演示编号。 ZSR/ICL/IT 分别指零样本推理、上下文学习和指令调整。
与基本范式(ZSR/ICL/IT)相比,KoPA结合了KG结构embedding进入LLM以结合文本和结构信息
KoPA 可以通过更简化的提示获得更好的结果
3.实验结果与分析
实现部分,该论文选取了三个数据集,进行了三元组分类的实验。三元组分类是一项重要的知识图谱补全任务,旨在判断给定三元组的正确性。论文的主要实验结果如下:
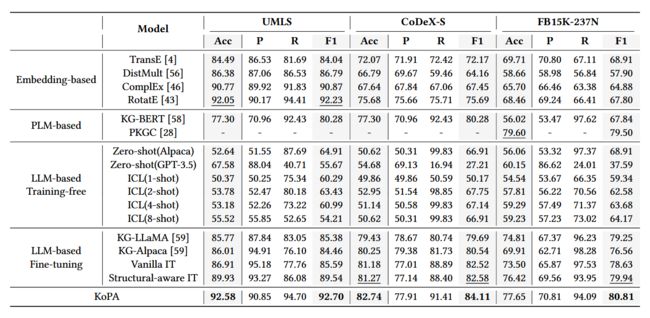
可以看到,相比于传统方法、基于大模型的方法和引入结构信息的方法来说,KoPA在三个数据集上的准确率、F1值等指标取得了一定的提升。
结果分析:
微调LLM可以将KG信息引入LLM,整体性能有了明显的提升。同时,结构感知IT虽然通过三元组的邻域信息增强了输入提示,但与KoPA相比,其性能也有限。这表明,与基于文本的辅助提示相比,结构embedding包含更丰富的语义信息,LLM 也可以通过前缀适配器来理解这些信息。
-
LLM在不进行微调的情况下无法很好地理解KG结构信息
-
与基于文本的辅助提示相比,结构embedding包含更丰富的语义信息,LLM 也可以通过前缀适配器来理解这些信息。
-
KoPA在更短的提示之上取得了更好的结果。
可移植性实验:
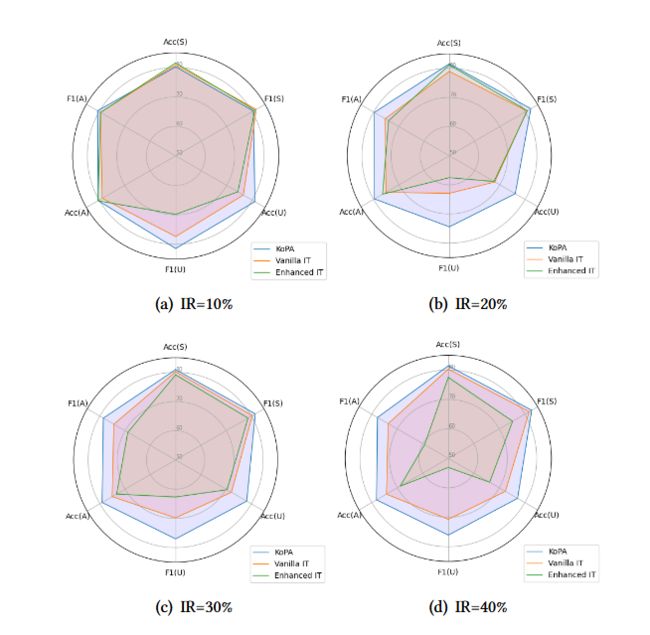
图 3:可转移性实验的结果。论文中报告了不同诱导率(IR)下 CoDeX-S 数据集的结果。此外,论文中根据实体在训练过程中是否出现将测试数据分为可见(S)和不可见(U)部分。论文中还将所有 (A) 测试数据的结果加在一起。雷达图表中报告了准确度 (Acc) 和 F1 分数 (F1)。
为了进一步验证KoPA的通用性和可移植性,论文中进行了一项新的可移植性实验。
- 归纳率(IR)的归纳设置,IR 指的是训练期间未见过的实体的比例。
- 可以观察到 KoPA 在看不见的三元组方面优于其他方法,并且当 IR 增加时性能下降较少。
- 这些现象表明知识前缀适配器可以学习从结构embedding到文本表示的良好映射,即使在训练期间看不见实体,这种映射也是可转移的,模型具有较好的可转移性
消融实验
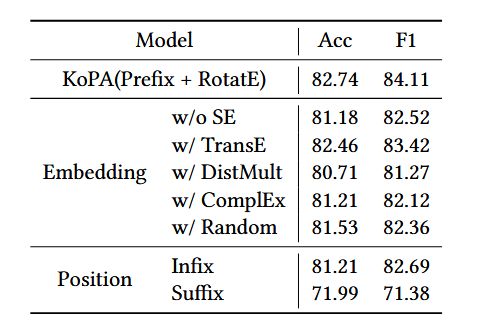
表 4:CoDeX-S 上的消融实验结果。论文中首先用其他组件替换预训练的结构embedding,并改变虚拟知识标记的插入位置,以证明知识前缀适配器的有效性。
- 第一部分旨在验证结构embedding的有效性 (选择RotatE的合理性)
- 第二部分旨在验证前缀适配器的有效性。(使用前缀而不是中缀和后缀的合理性)
将适配器生成的虚拟知识标记放在输入序列的中间(中缀)或最后(后缀)也会降低性能。将标记放在序列的前面将使所有文本都关注它们。
结合消融研究的这两部分,论文中相信KoPA设计是有效且合理的。
4.结论与启示
结论总结
在本文中,论文中提出了KoPA,一个为基于 LLM 的 KGC 设计的知识前缀适配器。 KoPA 旨在将KG的结构信息融入LLM中,并用KoPA生成的虚拟知识标记增强输入提示序列,指导文本解码过程做出合理的预测。 KoPA 是一种两阶段方法,包括结构embedding预训练和 LLM 上的指令调整。论文中进行了三元组分类实验,这是一项重要的 KGC 任务,旨在证明 KoPA 取得的优异结果。
该论文探索了如何将知识图谱中的结构知识引入大语言模型中,以更好地完成知识图谱推理,同时提出了一个新的知识前缀适配器,将从知识图谱中提取到的向量化的结构知识注入到大模型中。在未来,作者将进一步探索基于大语言模型的复杂知识图谱推理,同时也将关注如何利用知识图谱使得大语言模型能够在知识感知的情况下完成更多下游任务比如问答、对话等等。
-
提出了 KoPA :基于 LLM 的 KGC 设计的知识前缀适配器
-
KoPA旨在将KG的结构信息融入LLM中
-
两阶段方法,包括结构embedding预训练和 LLM 上的指令调整
-
三元组分类实验证明 KoPA 取得的优异结果
局限性
本文中基于三元组分类任务进行实验,目前,论文中还没有将模型方法推广到各种 KGC 任务,例如实体预测和关系预测。
启发
-
结构信息与大型语言模型(LLM)的协同利用: 有效地结合知识图谱(KG)的结构信息与大型语言模型LLM,可能提高模型对于知识推理的能力。
-
结构信息的预训练与传递: 如何通过结构信息的预训练,将图谱中实体和关系的结构embedding传递给大型语言模型,以提升语言模型对知识图谱中实体和关系的理解。 文中提出的**知识前缀适配器(KoPA)**可以帮助LLM来理解结构embedding中丰富的语义信息。